Каким кодом по классификатору обозначается автосцепное оборудование: Автосцепное оборудование грузовых вагонов
alexxlab | 23.01.2023 | 0 | Разное
Автосцепное оборудование грузовых вагонов
Автосцепным оборудованием называются устройства, которые обеспечивают сцепление вагонов между собой и с локомотивом, удерживают вагоны на определенном расстоянии друг от друга, а также передают и смягчают силы тяги и соударения вагонов.
Все типы грузовых вагонов РФ, стран СНГ и Балтии, оборудованы автосцепками типа СА-3 (советская сцепка третий вариант). При разработке этого типа автосцепных устройств учитывались следующие особенности.
При сцеплении вагонов между собой и с локомотивом могут возникнуть, по крайней мере, два варианта расположения экипажей (рис. 1).
Рис. 1. Схема расположения вагонов при сцеплении: а) в вертикальной плоскости; б) в горизонтальной плоскости
В варианте «а» из-за различной загрузки экипажей или по другим причинам возникает вертикальное Нв несовпадение осей сцепных устройств, а в варианте «б», при установке вагонов на кривом участке пути, возникает горизонтальное Нг несовпадение осей сцепных устройств.
Поэтому автосцепное устройство должно иметь такую конструкцию головок автосцепок, которые позволяли бы «улавливать» сцепляемые вагоны при нормированной величине как вертикальных, так и горизонтальных смещений экипажей.
В автосцепном оборудовании СА-3 эти и другие вопросы сцепления и расцепления экипажей решаются за счет соответствующих устройств.
Общий вид установки автосцепки на грузовом вагоне приведен на рис. 2.
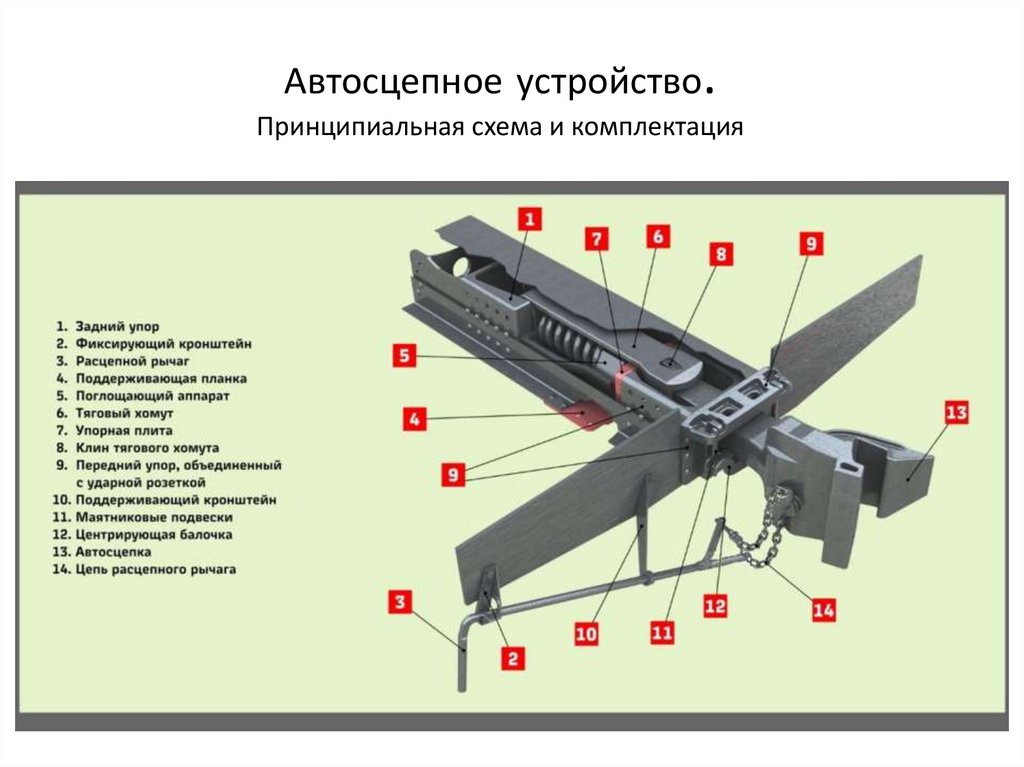
Автосцепное устройство вагона (рис. 2) состоит из следующих частей: 1) головки автосцепки и расположенного в ней замкового механизма; 2) расцепного привода; 3) ударно-центрирующего прибора; 4) упряжного устройства с поглощающим аппаратом.
Корпусом (головкой) автосцепки называется составная часть автосцепного устройства, которая обеспечивает «улавливание» и сцепление с другой автосцепкой, передачу растягивающих и сжимающих продольных усилий, а также удерживает вагоны на определенном расстоянии друг от друга.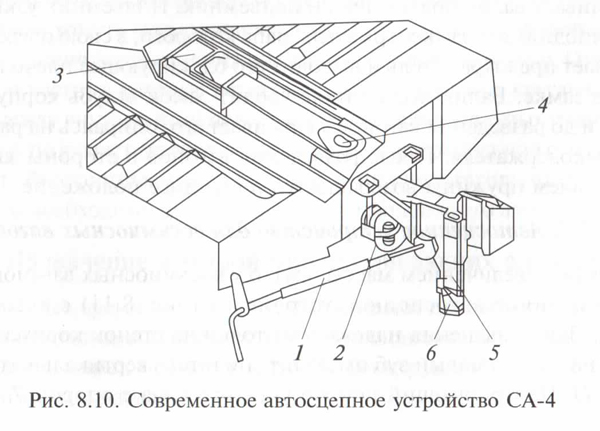
Рис. 2. Автосцепное устройство СА-3 грузовых вагонов:
1 — задние упорные угольники; 2 — фиксирующий кронштейн; 3 — расценкой рычаг; 4 — поддерживающая планка; 5 — поглощающий аппарат; 6 — тяговый хомут; 7 — упорная плита;
8 — тяговый клин; 9 — ударная розетка; 10 — державка; 11 — маятниковые болты; 12 — центрирующая балочка; 13 — головка автосцепки; 14 — цепочка расцепного привода
Расцепным приводом называется устройство, обеспечивающее срабатывание замкового механизма автосцепки на расцепление и удержание замка в утопленном состоянии, при постановке расцепного рычага на полочку.
Ударно-центрирующим прибором называется устройство, облегчающее горизонтальные перемещения головки автосцепки как при движении вагона, так и при улавливании (центрировании) автосцепки другого вагона в процессе сцепления экипажей, а также передачу части чрезмерных продольных сил, при полном сжатии поглощающего аппарата, на ударную розетку и далее на раму вагона.
Упряжным устройством называется механизм, обеспечивающий работу поглощающего аппарата только в режиме сжатия, как при действии растягивающих, так и сжимающих сил.
Поглощающим аппаратом называется устройство, обеспечивающее смягчение и частичное поглощение (рассеивание) энергии продольных сил, действующих на вагон.
Фактически поглощающий аппарат является горизонтальным рессорным комплектом, обеспечивающим рассеивание энергий соударений и продольных колебаний вагонов.
Использование машинного обучения для обнаружения шаблонов проектирования
Программное обеспечение все чаще выполняет основные функции Министерства обороны, такие как навигация кораблей и самолетов, логистика снабжения и ситуационная осведомленность в режиме реального времени. Однако сложность программного обеспечения затрудняет оценку качества программного обеспечения. Способность оценивать программное обеспечение имеет решающее значение как для разработчиков программного обеспечения, так и для менеджеров программ Министерства обороны США, отвечающих за приобретение программного обеспечения.
Качество программного обеспечения может создать или сломать бюджет программы. Атрибуты качества, такие как надежность, безопасность и модифицируемость, так же важны, как и уверенность в том, что программное обеспечение вычисляет правильный ответ. Любой основной подход к проектированию, выбранный разработчиком, будет иметь связанные с ним атрибуты качества. Клиент-сервер хорош для масштабируемости, многоуровневость хороша для переносимости, сервисы хороши для взаимодействия.
Важным компонентом оценки атрибутов качества программного обеспечения в масштабе является способность эффективно идентифицировать эти подходы к проектированию в исходном коде, известные как шаблоны проектирования . В этом сообщении блога объясняется, почему шаблоны проектирования имеют значение, и сообщается о многообещающих результатах экспериментального использования машинного обучения (МО) для обнаружения шаблонов проектирования в исходном коде.
Лучшие шаблоны проектирования делают лучшее программное обеспечение
В нашем недавнем опросе более 1800 разработчиков программного обеспечения было много ответов, похожих на этот ответ старшего разработчика:
У нас есть структура model-view-controller (MVC). Со временем мы нарушили простые правила этой структуры, и позже нам пришлось модифицировать многие функции [sic] с большими дополнительными затратами.
Платформа MVC, упомянутая в приведенном выше примере, является шаблоном проектирования или концептуальным руководством по разработке исходного кода для повышения гибкости, надежности и безопасности. Существует множество шаблонов дизайна. Известные шаблоны включают фильтрацию канала, публикацию-подписку, эхо-запрос, обработку транзакций.
Одна из причин, по которой шаблоны проектирования могут со временем нарушаться, заключается в том, что у разработчиков нет адекватных инструментов для обнаружения и обоснования правильной реализации шаблонов.
К сожалению, ручная оценка реализации шаблона проектирования является дорогостоящей, особенно в масштабе миллиардов строк исходного кода, лежащего в основе программного обеспечения Министерства обороны США. В ручной оценке участвуют высококвалифицированные архитекторы программного обеспечения, которые кропотливо исследуют исходный код построчно, обращая внимание как на содержимое каждой строки, так и на все соответствующие связи с другими строками, разбросанными по репозиторию.
Оценка качества программного обеспечения стоит дорого, но машинное обучение может помочь
Высокая стоимость обнаружения шаблонов проектирования побудила нас применить анализ кода и машинное обучение для автоматического обнаружения шаблонов проектирования. По состоянию на октябрь 2019 года мы пытались автоматически помечать файлы исходного кода платформы Spring MVC для исходного кода Java. Шаблон проектирования MVC делит интерактивное приложение на три взаимосвязанных элемента:
- Модель содержит основные функции и данные.
- Представления отображают данные для пользователя.
- Контроллеры обрабатывают пользовательский ввод.
Инфраструктура Spring MVC делит классы Java (или файлы, так как обычно один класс на файл) на эти непересекающиеся группы и дополнительно разлагает модель , как показано на рисунке 1.
Рисунок 1 : Платформа Spring MVC требует, чтобы каждый файл Java принадлежал к одной из нескольких непересекающихся функциональных групп с жестким набором ожиданий в отношении межгрупповых отношений. Источник изображения: Аниш и др. (2017) .
Источник изображения: Аниш и др. (2017) .
MVC — это подходящий шаблон для промышленных и программных возможностей Министерства обороны в корпоративных ИТ и операционных центрах, которые предоставляют интеллектуальную информацию на поле боя. Он широко используется и понятен, и представляет собой тип структур, используемых для разработки систем в масштабе. Кроме того, это слишком сложно для крупномасштабного программного проекта с использованием простых инструментов.
Мы создали классификатор, который оценивает метку группы MVC (с шестью возможными значениями) для каждого файла в репозитории исходного кода Java. Применимыми групповыми метками MVC являются контроллер и репозиторий, объект, служба и компонент , которые составляют модель (элемент представления шаблона MVC выходит за рамки кода, который мы рассмотрели). Все остальные файлы помечены как , другие . На рис. 2 показана производительность теста удержания нашего классификатора.
Классификатор использует машинное обучение, основанное на семантике языка программирования. Разработка функций включает в себя различные представления исходного кода, предоставляющие несколько входных сигналов для обучения обнаружению групп MVC на основе текстовой, поведенческой и структурной семантики. Группы MVC демонстрируют ряд различных характеристик. Разработчик, глядя на код контроллера, заметит, что он более связан, чем в среднем, поскольку он реагирует на пользовательский ввод и управляет потоком между моделью и представлением.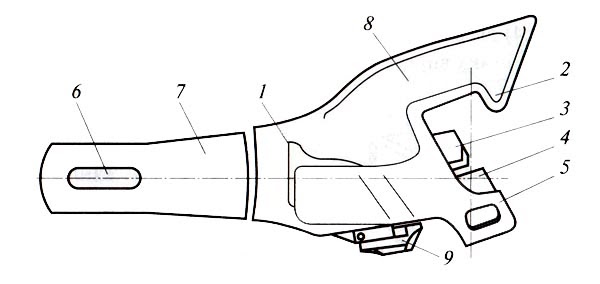 Однако код компонента может не так сильно отличаться от других, поскольку он предоставляет служебные классы для остальной части модели. Анализ результатов производительности в отношении этих характеристик дает возможность оценить модель машинного обучения, чтобы направить дальнейшие улучшения.
Однако код компонента может не так сильно отличаться от других, поскольку он предоставляет служебные классы для остальной части модели. Анализ результатов производительности в отношении этих характеристик дает возможность оценить модель машинного обучения, чтобы направить дальнейшие улучшения.
Представленный здесь классификатор недостаточно точен для запуска в производство для обнаружения шаблонов проектирования, но он демонстрирует, что машинное обучение может в значительной степени обнаруживать шаблоны проектирования в поддержку цели снижения стоимости оценки качества программного обеспечения. Будущие улучшения в разработке признаков приведут к гораздо большей точности. В конечном счете, высокоточный и надежный классификатор MVC может указывать на несоответствие шаблону проектирования MVC, распределяя свой вес вероятности предсказания по двум или более группам MVC, намекая на то, что файл необходимо реорганизовать или разделить на части, чтобы полностью соответствовать одной группе в MVC.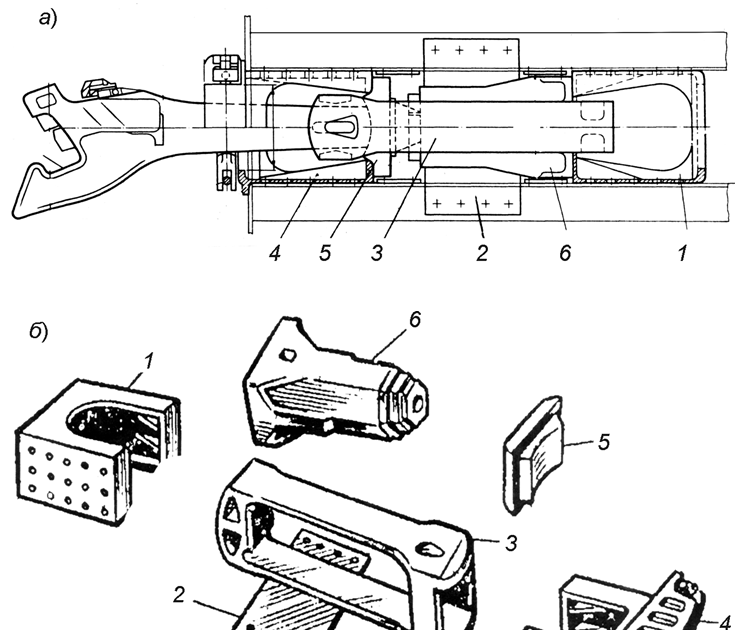 фреймворк.
фреймворк.
Детали методов и результатов классификатора
Мы описываем здесь наши методы и результаты, включая частичную информацию о
- необработанные данные, которые мы использовали для обучения и тестирования нашего классификатора,
- методы, которые мы использовали для определения числовых функций для каждого файла, который может содержать информацию о шаблоне проектирования,
- классификатор, который мы использовали для прогнозирования группы MVC файла на основе по его числовым характеристикам и
- оценка работы классификатора.
Необработанные данные : мы повторно использовали 104 проекта из коллекции проектов Java с открытым исходным кодом, которые Аниш и его коллеги ранее пометили и проанализировали на уровне файлов с помощью групповых меток MVC. В общей сложности наши проекты содержат около 54 000 файлов.
Мы разделили данные на уровне проекта на обучающую выборку (71 проект) и проверочную выборку (33 проекта). Разделение на уровне проекта (в отличие от случайного разделения между всеми 54 000 файлов) поддерживает строгую оценку точности классификатора, предотвращая использование классификатором специфических особенностей проекта во время тестирования. В частности, показатели производительности, о которых мы сообщаем, правдоподобно отражают производительность невиданного ранее репозитория Java, следующего за инфраструктурой Spring MVC.
Разделение на уровне проекта (в отличие от случайного разделения между всеми 54 000 файлов) поддерживает строгую оценку точности классификатора, предотвращая использование классификатором специфических особенностей проекта во время тестирования. В частности, показатели производительности, о которых мы сообщаем, правдоподобно отражают производительность невиданного ранее репозитория Java, следующего за инфраструктурой Spring MVC.
Учебный набор из 71 проекта включает более 38 000 файлов, а тестовый набор из 33 проектов включает более 15 000 файлов. Однако данные несбалансированы, так что наименее часто встречающаяся из шести групп MVC, репозиторий, представлена 990 файлами в обучающем наборе и 283 файлами в тестовом наборе.
Разработка признаков : Целью разработки признаков в этом контексте является определение числовых характеристик для каждого файла, которые содержат информацию о шаблонах проектирования файла. В нашем случае это было в виде вектора числовых характеристик для каждого файла, который мы называем вектор файла . Мы экспериментировали с пятью группами числовых признаков, как показано ниже и показано на рисунке 3.
Мы экспериментировали с пятью группами числовых признаков, как показано ниже и показано на рисунке 3.
- ( Классические метрики CK ) Чидамбер и Кремер (1994) определили несколько показателей гармонии между образцом исходного кода и принципами объектно-ориентированного проектирования (например, связь между объектами, отсутствие согласованности в методах). Эти метрики создают файловый вектор.
- ( Количество отношений сущностей ) SciTools Understand — это набор инструментов для статического анализа, который вычисляет граф нескольких типов отношений между всеми сущностями (например, переменными, методами, классами), определенными в проекте. Мы извлекли почти 4000 различных типов троек (сущность, связь, сущность) из графиков всех проектов. Примером такой тройки является ( общедоступный метод , использовать , частная переменная ). Мы подсчитали появление тройки каждого типа в файле, чтобы создать файловый вектор.

- ( code2vec* на отношениях сущностей ) Мы использовали Keras в Tensorflow 2.0 для рефакторинга архитектуры нейронной сети code2vec и немного модифицировали ее для прогнозирования группы MVC на уровне файла, назвав результат code2vec* . Эта архитектура принимает набор троек фиксированного размера (сущность, связь, сущность) в качестве входных данных; в этом случае мы использовали случайную выборку из 200 троек для каждого файла. Мы обучили сеть на нашем обучающем наборе, а затем оценили каждый файл как в обучающем, так и в тестовом наборах, чтобы получить вектор файла, извлекая активации предпоследнего слоя сети.
- ( code2vec* на путях AST ) Снова следуя методам Алона и его коллег, мы построили абстрактные синтаксические деревья (AST) для каждого файла и случайным образом выбрали 200 троек (конечный узел, соединительный путь, конечный узел) и использовали их. для обучения сети code2vec* и оценки каждого файла так же, как мы делали с тройками (сущность, связь, сущность).
- ( Pretrained code2vec ) Наконец, мы применили предварительно обученную модель code2vec (скачать здесь). Мы обучили эту модель прогнозированию элементов метода, которые могут не иметь прямого отношения к группе MVC, но наше обоснование заключалось в том, что семантическая информация в прогнозировании имен методов может пересекаться с проблемами шаблона проектирования. Кроме того, предварительно обученная модель, по-видимому, была обучена на гораздо большем обучающем наборе, чем мы обсуждали здесь, так что сеть должна была более глубоко изучить семантику. Как и в случае с code2vec* для путей AST, мы использовали предварительно обученную модель для создания вектора файлов на основе случайной выборки из 200 путей AST из каждого файла.


Рисунок 3: Мы использовали различные методы для создания пяти групп числовых признаков, которые могли бы содержать информацию о шаблонах проектирования каждого файла.
Классификатор: Мы обучили несколько разных экземпляров машины повышения градиента (в частности, LightGBM) для оценки метки группы MVC для каждого файла. Сначала мы создали пять отдельных классификаторов, обучая каждый из них исключительно одному из пяти наборов функций, представленных выше. Затем мы создали окончательный классификатор «все функции». На рис. 4 показана средняя производительность по шести группам MVC с одинаковым весом каждого из этих классификаторов с точки зрения нескольких популярных показателей. Нашей основной метрикой является площадь под кривой точности и полноты (AUPRC), поскольку она (а) включает в себя как точность, так и полноту, и (б) нечувствительна к глобальной неправильной калибровке (в отличие от оценки F1), измеряя способность классификатора ранжировать. упорядочить свои вероятностные предсказания файлов, принадлежащих группе MVC.
Рисунок 4: Средняя производительность каждого набора функций в терминах.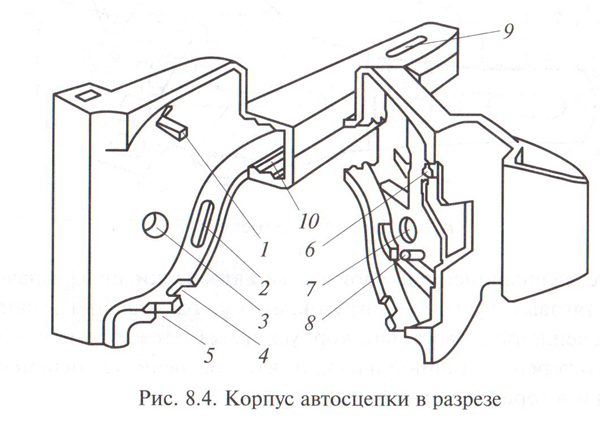 Горизонтальная пунктирная линия в каждой группе указывает базовый балл для случайного угадывания.
Горизонтальная пунктирная линия в каждой группе указывает базовый балл для случайного угадывания.
Результаты производительности, показанные на рис. 4, обнадеживают. Модель со всеми функциями работает лучше всего с точки зрения показателей F1 и AUPRC, предположительно потому, что она имеет доступ к наиболее предсказуемым функциям. Среди наборов функций функции, основанные на тройках отношений сущностей, по понятным причинам работают лучше всего, потому что эти функции фиксируют отношения между классами в стиле MVC. Возможности на основе AST менее эффективны, вероятно, потому, что мы извлекали функции AST только из каждого файла. Мы подозреваем, что дальнейшая работа по извлечению функций из более глобального графического представления кода, подобного AST, по всему репозиторию даст гораздо более информативные функции по отношению к дизайну MVC.
Обсуждение и будущая работа
Работа, которую мы представили выше, — не первая работа по автоматизации анализа шаблонов проектирования в исходном коде. Мы были вдохновлены несколькими темами связанной работы в литературе по машинному обучению для исходного кода.
Мы были вдохновлены несколькими темами связанной работы в литературе по машинному обучению для исходного кода.
- Первые приложения машинного обучения для исходного кода применяли готовые инструменты машинного обучения с извлеченными вручную функциями. Подключаемый модуль Metrics and Architecture для Eclipse (MARPLE) фиксирует контекст между элементами дизайна как микроструктуры в коде. Он использует эти структуры (например, абстрактный класс, вызов абстрактного метода и расширенное наследование) для поиска корреляций между элементами кода и ролями или отношений в шаблонах проектирования. Он хорошо обнаруживает простые одноуровневые паттерны (например, Singleton и Adapter), но плохо обнаруживает более сложные многоуровневые паттерны; например, составной шаблон дает оценку F1, равную 0,56. Основное ограничение обнаружения более сложных шаблонов проектирования потенциально объясняется особенностями, которые MARPLE использует для представления кода: микроструктуры кодируются вручную, а не изучаются из репрезентативного кода.
- Последующие приложения используют сам исходный код в рамках машинного обучения, черпая вдохновение из обработки естественного языка (NLP). НЛП считает, что моделирование контекста вокруг слов повышает производительность. word2vec создает векторное пространство, в котором слова, имеющие общий контекст, расположены близко друг к другу в пространстве. Это сохраняет смысловые отношения. doc2vec добавляет контекст абзаца к встраиванию слов, чтобы обеспечить представление документов, что может значительно повысить производительность для задач, требующих фиксации отношений на более высоких уровнях абстракции.
- Текущие приложения обещают новые модели машинного обучения, основанные на семантике языка программирования. code2vec стремится достичь семантического понимания исходного кода, поскольку он может — с небольшой точностью — предсказать имя метода из содержащегося в нем исходного кода. Хотя code2vec хорошо фиксирует закономерности в обучающих данных, его закономерности ограничены теми, которые можно наблюдать в изолированных методах, поскольку code2vec использует пути вдоль AST метода для своих прогнозов. Таким образом, представление не может фиксировать ни отношения между методами внутри одного класса, ни отношения между классами.

 Таким образом, представление не может фиксировать ни отношения между методами внутри одного класса, ни отношения между классами.
Таким образом, представление не может фиксировать ни отношения между методами внутри одного класса, ни отношения между классами.Согласование дизайна системы с ее реализацией повышает качество продукта и упрощает его эволюцию. По мере увеличения абстракции в форме шаблонов проектирования усложняется задача обнаружения и анализа их правильного использования. Преодоление разрыва в абстракции — важная задача для поддержки автоматизации, которая также требует объединения представлений в дизайне, анализе кода и машинном обучении.
Наше долгосрочное видение состоит в том, чтобы создавать классификаторы не только для одного, но и для многих различных типов шаблонов проектирования. В конечном счете, эти классификаторы станут частью недорогого инструмента соответствия шаблонам проектирования, чтобы (а) позволить руководителям программ оценить, соответствует ли поставляемая реализация дизайну, на который они заключили контракт при приобретении крупномасштабных систем, и ( б) помочь разработчикам программного обеспечения улучшить разработку исходного кода во время непрерывной интеграции и доставки, сводя к минимуму накопление технического долга.
Дополнительные ресурсы
Прочтите запись в блоге SEI «Векторы кода: машинное обучение для программного обеспечения» Закари Курца.
Прочтите другие записи блога SEI о машинном обучении.
Как выбрать алгоритм ML.NET – ML.NET
- Статья
- 6 минут на чтение
Для каждой задачи ML.NET существует несколько алгоритмов обучения на выбор. Какой из них выбрать, зависит от проблемы, которую вы пытаетесь решить, характеристик ваших данных, а также доступных вычислительных ресурсов и ресурсов хранения. Важно отметить, что обучение модели машинного обучения — это итеративный процесс. Возможно, вам придется попробовать несколько алгоритмов, чтобы найти тот, который работает лучше всего.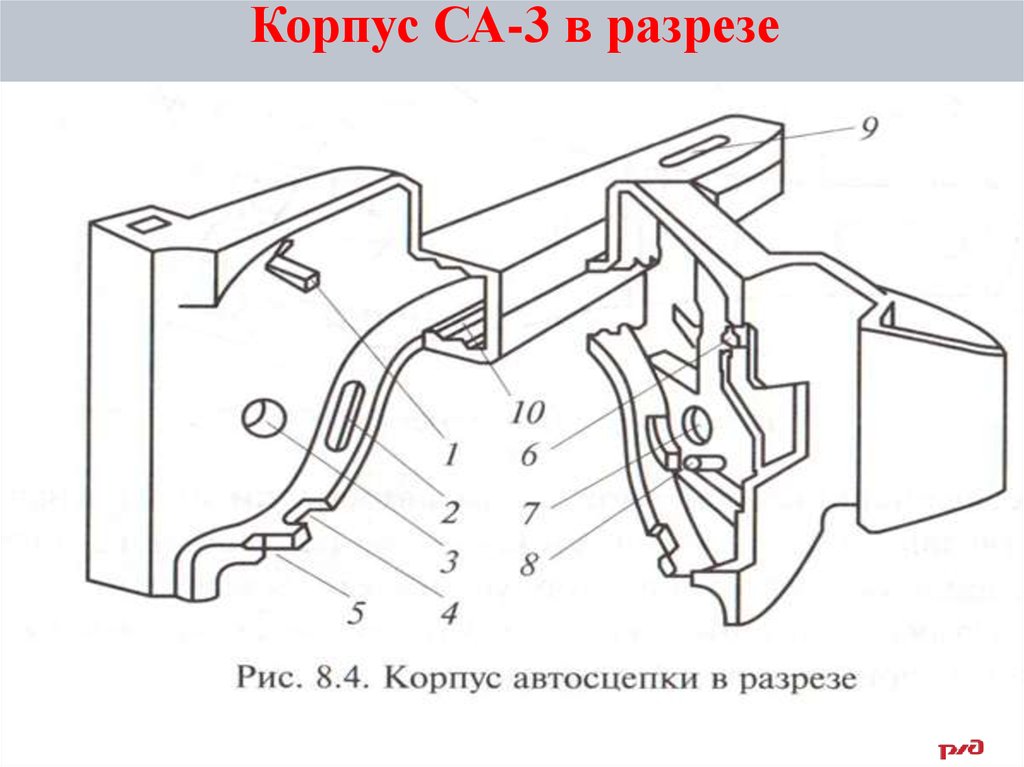
Алгоритмы работают с функциями . Характеристики — это числовые значения, вычисленные на основе ваших входных данных. Они являются оптимальными входными данными для алгоритмов машинного обучения. Вы преобразуете необработанные входные данные в функции, используя одно или несколько преобразований данных. Например, текстовые данные преобразуются в набор подсчетов слов и подсчетов словосочетаний. После того, как функции были извлечены из необработанного типа данных с помощью преобразования данных, они называются признаками . Например, расширенный текст или графические данные.
Тренажер = Алгоритм + Задача
Алгоритм — это математический расчет, который выполняется для создания модели . Разные алгоритмы создают модели с разными характеристиками.
В ML.NET один и тот же алгоритм можно применять к разным задачам. Например, стохастическое двухкоординатное восхождение можно использовать для бинарной классификации, мультиклассовой классификации и регрессии. Разница заключается в том, как результат алгоритма интерпретируется в соответствии с задачей.
Разница заключается в том, как результат алгоритма интерпретируется в соответствии с задачей.
Для каждой комбинации алгоритм/задача ML.NET предоставляет компонент, который выполняет обучающий алгоритм и выполняет интерпретацию. Эти компоненты называются тренерами. Например, SdcaRegressionTrainer использует 9Алгоритм 0219 StochasticDualCoordinatedAscent применен к задаче Regression .
Линейные алгоритмы
Линейные алгоритмы создают модель, которая вычисляет баллов из линейной комбинации входных данных и набора весов . Веса — это параметры модели, оцениваемые в процессе обучения.
Линейные алгоритмы хорошо работают для признаков, которые линейно разделимы.
Перед обучением по линейному алгоритму необходимо нормализовать признаки. Это препятствует тому, чтобы одна функция имела большее влияние на результат, чем другие.
В общем, линейные алгоритмы масштабируемы, быстры, дешевы в обучении и дешевы в прогнозировании. Они масштабируются по количеству признаков и примерно по размеру набора обучающих данных.
Они масштабируются по количеству признаков и примерно по размеру набора обучающих данных.
Линейные алгоритмы выполняют несколько проходов по обучающим данным. Если ваш набор данных помещается в память, то добавление контрольной точки кеша в ваш конвейер ML.NET перед добавлением тренера ускорит обучение.
Усредненный персептрон
Лучше всего подходит для классификации текста.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| Тренажер среднего персептрона | Бинарная классификация | Да |
Стохастический двойной координированный подъем
Настройка не требуется для хорошей производительности по умолчанию.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| SdcaLogisticRegressionBinaryTrainer | Бинарная классификация | Да |
| SdcaNonCalibratedBinaryTrainer | Бинарная классификация | Да |
| SdcaMaximumEntropyMulticlassTrainer | Многоклассовая классификация | Да |
| SdcaNonCalibratedMulticlassTrainer | Многоклассовая классификация | Да |
| SdcaRegressionTrainer | Регрессия | Да |
L-BFGS
Используйте при большом количестве функций.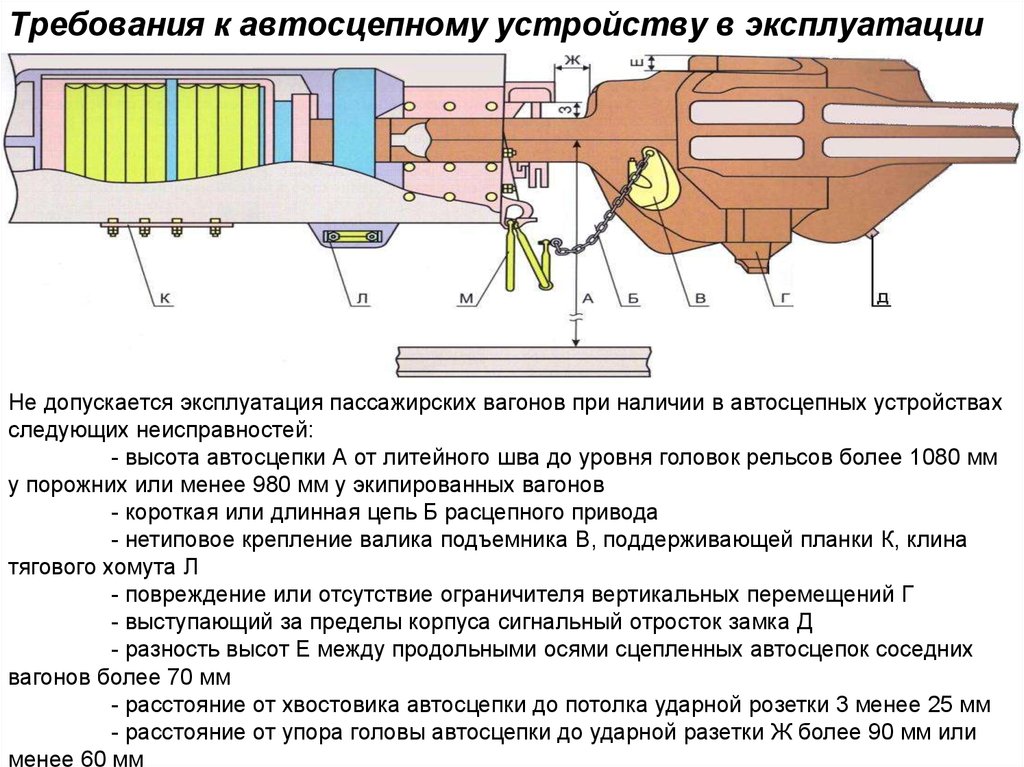 Создает статистику обучения логистической регрессии, но не масштабируется так же хорошо, как AveragedPerceptronTrainer.
Создает статистику обучения логистической регрессии, но не масштабируется так же хорошо, как AveragedPerceptronTrainer.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| LbfgsLogisticRegressionBinaryTrainer | Бинарная классификация | Да |
| LbfgsMaximumEntropyMulticlassTrainer | Мультиклассовая классификация | Да |
| LbfgsPoissonRegressionTrainer | Регрессия | Да |
Символический стохастический градиентный спуск
Самый быстрый и точный тренажер линейной бинарной классификации. Хорошо масштабируется с количеством процессоров.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| SymbolicSgdLogisticRegressionBinaryTrainer | Бинарная классификация | Да |
Градиентный спуск онлайн
Реализует стандартный (непакетный) стохастический градиентный спуск с выбором функций потерь и возможностью обновления вектора весов с использованием среднего значения векторов, наблюдаемых с течением времени.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| OnlineGradientDescentTrainer | Регрессия | Да |
Алгоритмы дерева решений
Алгоритмы дерева решений создают модель, содержащую ряд решений: фактически блок-схему значений данных.
Объекты не обязательно должны быть линейно разделимыми, чтобы использовать этот тип алгоритма. И функции не нужно нормализовать, потому что отдельные значения в векторе признаков используются независимо в процессе принятия решения.
Алгоритмы дерева решений обычно очень точны.
За исключением обобщенных аддитивных моделей (GAM), древовидные модели могут не объясняться при большом количестве функций.
Алгоритмы дерева решений требуют больше ресурсов и не масштабируются так хорошо, как линейные. Они хорошо работают с наборами данных, которые могут поместиться в памяти.
Усиленные деревья решений — это ансамбль небольших деревьев, в котором каждое дерево оценивает входные данные и передает результат следующему дереву для получения лучшего результата, и так далее, где каждое дерево в ансамбле улучшает предыдущее.
Машина с усилением светового градиента
Самый быстрый и точный из тренажеров дерева бинарной классификации. Высокая настраиваемость.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| LightGbmBinaryTrainer | Бинарная классификация | Да |
| LightGbm MulticlassTrainer | Многоклассовая классификация | Да |
| LightGbmRegressionTrainer | Регрессия | Да |
| LightGbmRankingTrainer | Рейтинг | № |
Быстрое дерево
Используется для данных изображений с признаками. Устойчив к несбалансированным данным. Высокая настраиваемость.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| FastTreeBinaryTrainer | Бинарная классификация | Да |
| FastTreeRegressionTrainer | Регрессия | Да |
| FastTreeTweedieTrainer | Регрессия | Да |
| FastTreeRankingTrainer | Рейтинг | № |
Быстрый лес
Хорошо работает с зашумленными данными.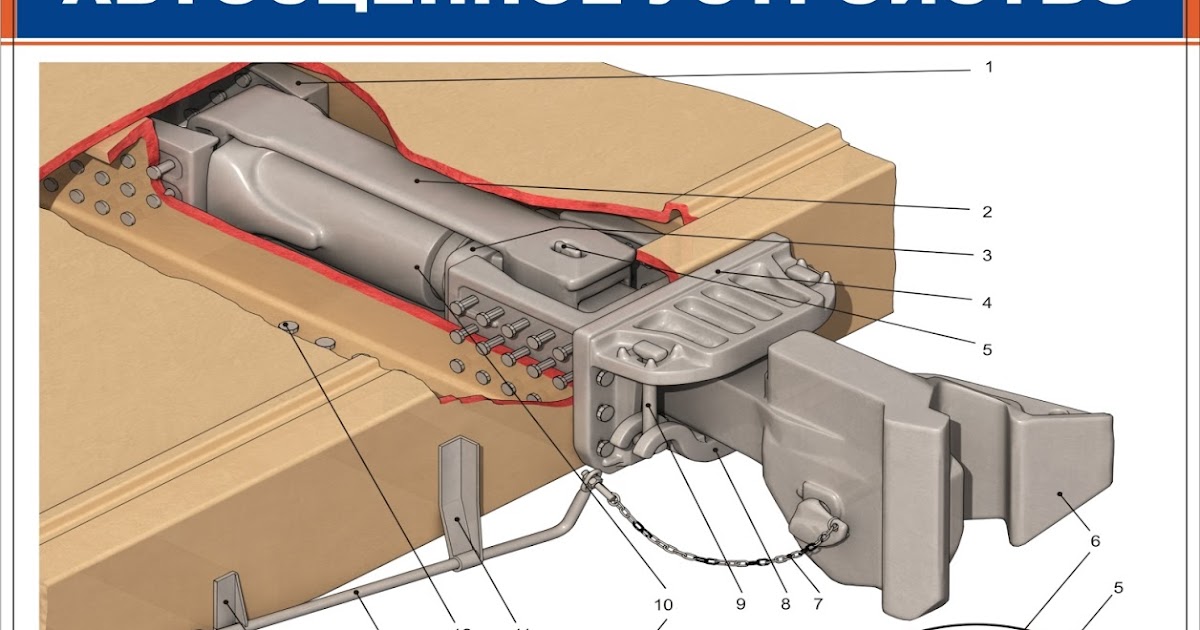
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| FastForestBinaryTrainer | Бинарная классификация | Да |
| FastForestRegressionTrainer | Регрессия | Да |
Обобщенная аддитивная модель (GAM)
Лучше всего подходит для задач, которые хорошо работают с древовидными алгоритмами, но где приоритетом является объяснимость.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| GamBinaryTrainer | Бинарная классификация | № |
| GamRegressionTrainer | Регрессия | № |
Матричная факторизация
Матричная факторизация
Используется для совместной фильтрации в рекомендациях.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| MatrixFactorizationTrainer | Рекомендация | № |
Полевая машина факторизации
Лучше всего подходит для разреженных категориальных данных с большими наборами данных.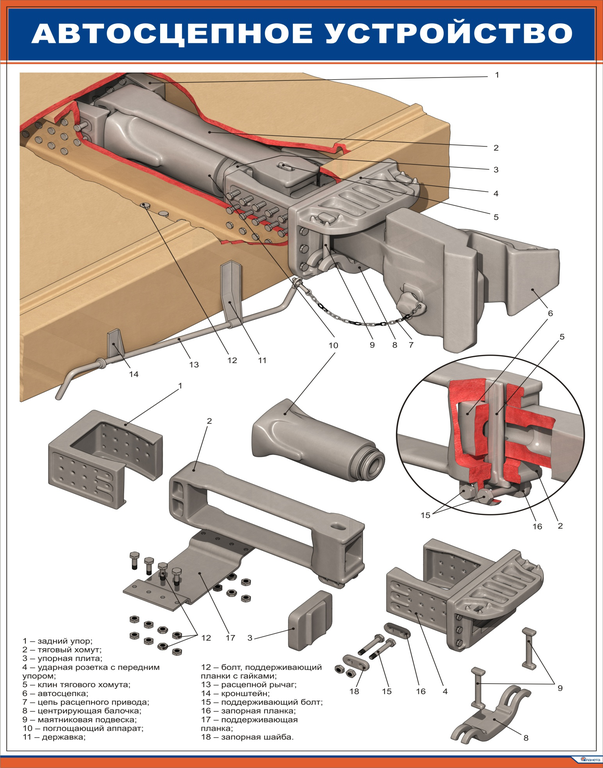
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| FieldAwareFactorizationMachineTrainer | Бинарная классификация | № |
Мета-алгоритмы
Эти трейнеры создают мультиклассовый трейнер из бинарного трейнера. Используйте с AveragedPerceptronTrainer, LbfgsLogisticRegressionBinaryTrainer, SymbolicSgdLogisticRegressionBinaryTrainer, LightGbmBinaryTrainer, FastTreeBinaryTrainer, FastForestBinaryTrainer, GamBinaryTrainer.
Один против всех
Этот многоклассовый классификатор обучает один двоичный классификатор для каждого класса, который отличает этот класс от всех других классов. Масштаб ограничен количеством классов для классификации.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| OneVersusAllTrainer | Многоклассовая классификация | Да |
Парная связь
Этот многоклассовый классификатор обучает алгоритм бинарной классификации для каждой пары классов. Ограничен в масштабе количеством классов, так как каждая комбинация двух классов должна быть обучена.
Ограничен в масштабе количеством классов, так как каждая комбинация двух классов должна быть обучена.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| Тренажер для парных соединений | Многоклассовая классификация | № |
K-Means
Используется для кластеризации.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| KMeansTrainer | Кластеризация | Да |
Анализ главных компонентов
Используется для обнаружения аномалий.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| РандомизированныйPcaTrainer | Обнаружение аномалий | № |
Наивный байесовский алгоритм
Используйте этот алгоритм многоклассовой классификации, когда признаки независимы, а набор обучающих данных небольшой.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| NaiveBayesMulticlassTrainer | Многоклассовая классификация | Да |
Prior Trainer
Используйте этот алгоритм бинарной классификации для оценки производительности других тренажеров. Чтобы быть эффективным, показатели других тренеров должны быть лучше, чем у предыдущего тренера.
| Тренажер | Задача | ONNX экспортируемый |
|---|---|---|
| PriorTrainer | Бинарная классификация | Да |
Машины опорных векторов
Машины опорных векторов (SVM) — чрезвычайно популярный и хорошо изученный класс моделей обучения с учителем, которые можно использовать в задачах линейной и нелинейной классификации.
Недавние исследования были сосредоточены на способах оптимизации этих моделей для эффективного масштабирования для более крупных обучающих наборов.
Линейный SVM
Предсказывает цель, используя модель линейной бинарной классификации, обученную на данных с булевой маркировкой. Чередуется шаги стохастического градиентного спуска и шаги проекции.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| LinearSvmTrainer | Бинарная классификация | Да |
Local Deep SVM
Предсказывает цель, используя нелинейную модель бинарной классификации. Снижает затраты времени на прогнозирование; стоимость предсказания растет логарифмически с размером обучающей выборки, а не линейно, с допустимой потерей точности классификации.
| Тренажер | Задача | Экспортируемый ONNX |
|---|---|---|
| LdSvmTrainer | Бинарная классификация | Да |
Метод наименьших квадратов
Метод наименьших квадратов (МНК) является одним из наиболее часто используемых методов линейной регрессии.