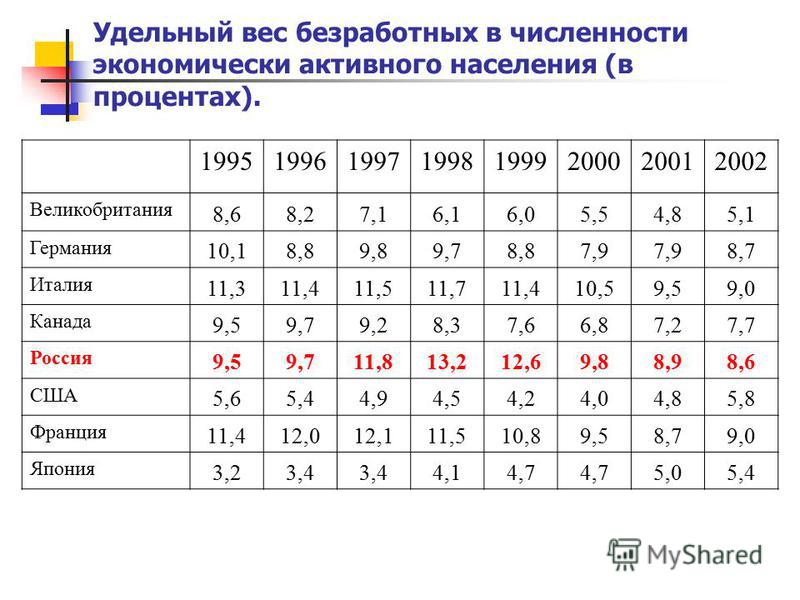
Удельный вес населения: Показатель 1 “Удельный вес населения в возрасте 5 – 18 лет, охваченного образованием, в общей численности населения в возрасте 5
alexxlab | 01.05.2023 | 0 | Разное
Показатель 1 “Удельный вес населения в возрасте 5 – 18 лет, охваченного образованием, в общей численности населения в возрасте 5
Показатель 1 “Удельный вес населения в возрасте 5 – 18 лет,
охваченного образованием, в общей численности населения
в возрасте 5 – 18 лет”
Субъект официального статистического учета, Росстат,
ответственный за сбор и представление информации Минобрнауки России
Исполнитель, ответственный за формирование показателя
(контактная информация: ф.и.о., должность, телефон,
адрес электронной почты)
1. Наименование показателя Удельный вес населения в возрасте 5 – 18
лет, охваченного образованием, в общей
численности населения в возрасте 5 – 18
лет
2. Единица измерения проценты
3. Определение показателя характеризует охват населения в возрасте 5
– 18 лет образованием. Определяется как
Определяется как
отношение численности обучающихся в
возрасте 5 – 18 лет в образовательных
организациях различных типов к численности
населения в возрасте 5 – 18 лет,
скорректированной на численность детей
данной возрастной группы, не подлежащих
обучению
4. Алгоритм формирования , где 5 i 18; j = 1, 2,
показателя и 3, 4, 5 ;
методологические
пояснения к показателю
5. Наблюдаемые относительные
характеристики
показателя
6. Временные характеристики на начало учебного года, на конец учебного
показателя года
7. Характеристика разреза Российская Федерация, субъекты Российской
наблюдения Федерации
8. Дополнительные требуется обеспечить сбор информации об
Дополнительные требуется обеспечить сбор информации об
характеристики, обучающихся по программам начального
необходимые для описания профессионального образования в
показателя негосударственных организациях. Для
корректного расчета показателя необходимо
разработать инструмент измерения
численности детей, не подлежащих обучению
─────┬─────────────────────┬───────────┬──────────────┬────────────────┬─────────────────┬─────────────
N │ Наименования и │ Буквенное │ Орган │ Метод сбора │ Объект и единица│Охват единиц
п/п │ определения базовых │обозначение│исполнительной│ информации, │ наблюдения │совокупности
│ показателей │ в формуле │ власти │ индекс формы │ │
│ │ расчета │(организация) │ отчетности │ │
│ │ │ – источник │ │ │
│ │ │ информации │ │ │
─────┴─────────────────────┴───────────┴──────────────┴────────────────┴─────────────────┴─────────────
1. Численность Чij,
Численность Чij,
обучающихся в где 5 i
возрасте “i” 18
а) численность детей в периодическая дошкольные сплошное
возрасте “i” в отчетность, образовательные наблюдение
дошкольных форма N 85-К организации
образовательных
организациях
б) численность Минобрнауки периодическая образовательные сплошное
обучающихся в России отчетность, организации, наблюдение
возрасте “i” по формы N N ОШ-1, реализующие
программам общего 76-РИК, СВ-1 программы общего
образования образования
в) численность Минобрнауки периодическая образовательные сплошное
обучающихся в России отчетность, организации, наблюдение
возрасте “i” по форма N 1 реализующие
программам начального (профтех) программы
профессионального начального
образования профессионального
образования
г) численность Росстат периодическая образовательные сплошное
обучающихся в отчетность, организации, наблюдение
возрасте “i” по форма N СПО-1 реализующие
программам среднего программы
профессионального среднего
образования профессионального
образования
д) численность Росстат периодическая образовательные сплошное
обучающихся в отчетность, организации, наблюдение
возрасте “i” по форма N ВПО-1 реализующие
программам высшего программы высшего
образования образования
2. Численность Росстат периодическая население в сплошное
Численность Росстат периодическая население в сплошное
населения в возрасте отчетность, возрасте 5 – 18 наблюдение
5 – 18 лет данные лет
демографической
статистики о
возрастно-
половом составе
населения
3. Численность детей в Минобрнауки периодическая население в сплошное
возрасте 5 – 18 лет, России отчетность, возрасте 5 – 18 наблюдение
не подлежащих данные о лет
обучению численности
детей в
возрасте 5 – 18
лет, не
подлежащих
обучению
───────────────────────────────────────────────────────────────────────────────────────────────────────
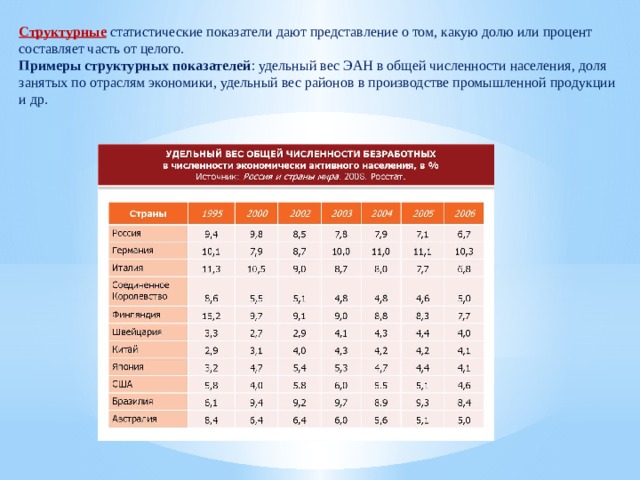
Целевые значения критериев доступности и качества медицинской помощи
| № | Наименование показателя | Оценка |
| 1 | Удовлетворенность населения медицинской помощью | не менее 40% |
| 2 | Смертность населения (на 1 000 населения) | не более 13,5 |
| 3 | Смертность населения от болезней системы кровообращения (на 100 000 населения) | 690,7 |
| 4 | Смертность населения от новообразований (в том числе от злокачественных) (на 100 000 населения) | 193 |
| 5 | Смертность населения от дорожно-транспортных происшествий (на 100 000 населения) | 14,9 |
| 6 | Смертность населения от туберкулеза (на 100 000 населения) | 35,6 |
| 7 | Смертность населения в трудоспособном возрасте (на 100 000 населения) | 801,5 |
| 8 | Смертность населения в трудоспособном возрасте от болезней системы кровообращения (на 100 000 населения) | 230,0 |
| 9 | Материнская смертность (случаев на 100 000 человек, родившихся живыми) | 5,2 |
| 10 | Младенческая смертность (случаев на 1000 родившихся живыми) | 8,7 |
| 11 | Смертность детей в возрасте 0-14 лет (на 100 тыс. человек населения соответствующего возраста) человек населения соответствующего возраста) | 120 |
| 12 | Удельный вес больных злокачественными новообразованиями, выявленных на ранних стадиях, в общем количестве впервые выявленных больных злокачественными новообразованиями | 46% |
| 13 | Количество обоснованных жалоб, в том числе на отказ в оказании медицинской помощи, предоставляемых в рамках Программы | не должно быть |
| 14 | Количество медицинских организаций, осуществляющих автоматизированную запись на прием к врачу с использованием сети Интернет и информационно-справочных сенсорных терминалов | 19,7% |
| 15 | Обеспеченность населения врачами (человек на 10 тыс.населения) всего, в т.ч. по условиям оказания медицинской помощи | 41,8 |
| 16 | Средняя длительность лечения в медицинской организации, оказывающей медицинскую помощь в стационарных условиях (дней) | 12 |
| 17 | Эффективность деятельности медицинских организаций на основе оценки выполнения функции врачебной деятельности, показателей рационального и целевого использования коечного фонда | В соответствии с приложением к ТПГГ |
| 18 | Объем медицинской помощи, оказываемой в условиях дневных стационаров (число пациенто-дней на 1 жителя, на 1 застрахованное лицо) | В соответствии с приложением к ТПГГ |
| 19 | Уровень госпитализации населения, прикрепленного к медицинской организации, оказывающей первичную медико-санитарную помощь (на 1000 чел. | 263,1 |
| 20 | Удельный вес госпитализаций в экстренной форме в общем объеме госпитализаций населения, прикрепленного к медицинской организации, оказывающей первичную медико-санитарную помощь | 41,1 |
Пропорции населения » Биостатистика » Колледж общественного здравоохранения и медицинских профессий » Университет Флориды
- Доверительные интервалы
- Расчет размера выборки
- Когда безопасно использовать эти методы?
- Подведем итоги
CO-4: Проводить различия между различными шкалами измерения, выбирать соответствующие описательные и логические статистические методы на основе этих различий и интерпретировать результаты.
LO 4.30: Интерпретировать доверительные интервалы для параметров совокупности в контексте.
LO 4.32: Найдите доверительные интервалы для доли совокупности с помощью формулы (при соблюдении необходимых условий) и выполните расчет размера выборки.
CO-6: Применение основных понятий вероятности, случайной вариации и широко используемых статистических распределений вероятностей.
LO 6.24: Объясните связь между выборочным распределением статистики и ее свойствами как точечной оценки.
LO 6.25: Объясните, что представляет собой доверительный интервал, и определите, как изменения размера выборки и уровня достоверности влияют на точность доверительного интервала.
Видео: Доля населения (4:13)
Доверительные интервалы
Как мы упоминали во введении к Модулю 4A, когда переменная, которую мы хотим изучить в совокупности, категориальная , параметр, который мы пытаются сделать вывод о
Чтобы освежить вашу память, вот картинка, которая обобщает рассмотренный нами пример.
Теперь мы переходим к интервальной оценке p. Другими словами, мы хотели бы разработать набор интервалов, которые с разным уровнем достоверности будут фиксировать значение p. На самом деле мы проделали всю подготовительную работу и обсудили все важные идеи интервальной оценки, когда говорили об интервальной оценке для μ (mu), так что мы сможем пройти через это намного быстрее. Давай начнем.
Напомним, что общий вид любого доверительного интервала для неизвестного параметра:
оценка ± погрешность Я вам выше напомнил) это примерная пропорция п-шляпы. Таким образом, доверительный интервал для p имеет вид:
(напомним, что m — это обозначение предела погрешности.) Погрешность (m) дает нам максимальную ошибку оценки с определенной достоверностью. В этом случае это говорит нам о том, что p-hat отличается от p (параметр, который он оценивает) не более чем на m единиц.
Из нашего предыдущего обсуждения доверительных интервалов мы также знаем, что предел погрешности является произведением двух компонентов:
Раздел «Распределение выборки» блока «Вероятность» о распределении выборки p-hat. Мы обнаружили, что при определенных условиях (к которым мы вернемся позже) p-hat имеет нормальное распределение со средним значением p и
Мы обнаружили, что при определенных условиях (к которым мы вернемся позже) p-hat имеет нормальное распределение со средним значением p и
Этот результат упрощает для нас задачу, поскольку показывает, из каких двух компонентов состоит погрешность:
- Поскольку, как и выборочное распределение x-bar, выборочное распределение p-hat является нормальным , множители достоверности, которые мы будем использовать в доверительном интервале для p , будут теми же множителями z*, которые мы используем для доверительного интервала для µ (mu), когда известно σ (сигма) (используя точно те же рассуждения и результаты с одинаковой вероятностью). Множители, которые мы будем использовать, будут следующими: 1,645, 1,96 и 2,576 при доверительном уровне 90%, 95% и 99% соответственно.
- Стандартное отклонение нашей оценки p-hat равно .
Собрав все вместе, мы находим, что доверительный интервал для p должен быть:
Нам просто нужно решить одну практическую задачу, и все готово. Мы пытаемся оценить неизвестных
Мы пытаемся оценить неизвестных
Мы заменим p его образцом, p-hat, и будем работать с оценкой стандартной ошибки p-hat
Теперь мы закончили. Доверительный интервал для доли населения p составляет:
ПРИМЕР:
Препарат Виагра стал доступен в США в мае 1998 года после беспрецедентной по масштабу и интенсивности рекламной кампании. Опрос Гэллапа показал, что к концу первой недели мая 643 из случайной выборки из 1005 взрослых знали, что Виагра является лекарством от импотенции (на основе «Виагры — популярный хит», анализа опроса Гэллапа, проведенного Лидией Саад, 19 мая98).
Давайте оценим долю p среди всех взрослых в США, которые к концу первой недели мая 1998 года уже знали о виагре и ее назначении, установив 95% доверительный интервал для p.
Сначала нам нужно рассчитать долю выборки p-hat. Из 1005 отобранных взрослых 643 знали, для чего используется Виагра, поэтому p-hat = 643/1005 = 0,64
Следовательно, 95% доверительный интервал для p равен
. доля всех взрослых американцев, которые к тому времени уже были знакомы с виагрой, составляла от 0,61 до 0,67 (или от 61% до 67%).
Тот факт, что предел погрешности равен 0,03, говорит о том, что мы можем быть на 95 % уверены в том, что доля неизвестной популяции p находится в пределах 0,03 (3%) от наблюдаемой доли выборки 0,64 (64%). Другими словами, мы на 95% уверены, что 64% «отклоняются» не более чем на 3%.
Я понял?: Доверительные интервалы – Пропорции #1
Комментарий:
- Мы хотели бы поделиться с вами методологической частью официального опроса на примере Виагры. Надеемся, вы видите, что теперь у вас есть инструменты для понимания того, как анализируются результаты опроса:
«Результаты основаны на телефонных интервью со случайно выбранной национальной выборкой из 1005 взрослых в возрасте 18 лет и старше, проведенных 8-10 мая 1998 г. Для результатов, основанных на выборках такого размера, можно с 95-процентной уверенностью сказать, что ошибка, связанная с выборкой и другими случайными эффектами, может составлять плюс-минус 3 процентных пункта. Помимо ошибки выборки, формулировка вопроса и практические трудности в проведении опросов могут внести ошибку или предвзятость в результаты опросов общественного мнения».
Для результатов, основанных на выборках такого размера, можно с 95-процентной уверенностью сказать, что ошибка, связанная с выборкой и другими случайными эффектами, может составлять плюс-минус 3 процентных пункта. Помимо ошибки выборки, формулировка вопроса и практические трудности в проведении опросов могут внести ошибку или предвзятость в результаты опросов общественного мнения».
Целью следующего занятия является практическое руководство расчетом и интерпретацией доверительного интервала для доли населения p и получением на его основе выводов.
Учись на практике:
Два важных результата, которые мы подробно обсуждали, когда говорили о доверительном интервале для μ (мю), также применимы и здесь:
1. Существует компромисс между уровнем достоверности и шириной (или точностью) доверительного интервала. Чем больше точности вы хотите, чтобы доверительный интервал для p имел, тем больше вам придется платить за более низкий уровень достоверности.
2. Поскольку n появляется в знаменателе погрешности доверительного интервала для p, при фиксированном уровне достоверности чем больше выборка, тем она уже или точнее. Это естественным образом подводит нас к следующему пункту.
Расчет размера выборки
Как и в случае со средними значениями, когда у нас есть некоторый уровень гибкости в определении размера выборки, мы можем установить желаемую погрешность для оценки доли генеральной совокупности и найти размер выборки, который позволит этого достичь.
Например, для финального опроса за день до выборов требуется, чтобы погрешность была довольно малой (с высоким уровнем достоверности), чтобы можно было предсказать результаты выборов с максимальной точностью. Это особенно актуально, когда между кандидатами идет напряженная гонка. Опросная компания должна выяснить, сколько избирателей, имеющих право голоса, она должна включить в свою выборку, чтобы добиться этого.
Посмотрим, как мы это сделаем.
( Комментарий: Для нашего обсуждения здесь мы сосредоточимся на доверительном уровне 95 % (z* = 1,96), так как это наиболее часто используемый уровень достоверности.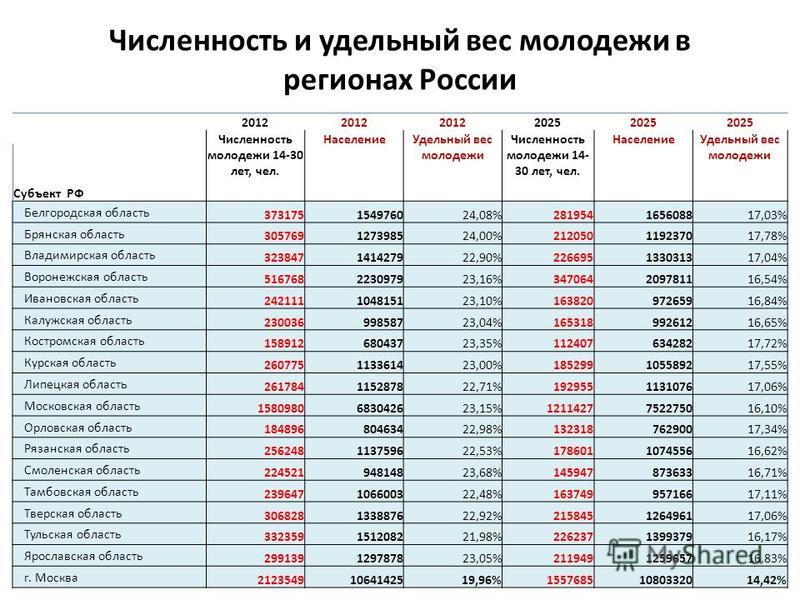 )
)
Доверительный интервал для p – тогда
Теперь мы изолируем n (т. е. выражаем его как функцию m).
С этим выражением связана практическая проблема, которую нам нужно решить.
На практике вы сначала определяете размер выборки, затем выбираете случайную выборку такого размера, а затем используете собранные данные для поиска p-hat.
Таким образом, тот факт, что приведенное выше выражение для определения размера выборки зависит от p-hat, является проблематичным.
Чтобы решить эту проблему, используйте консервативный подход, установив p-hat = 1/2 = 0,5.
Почему мы называем этот подход консервативным?
Он консервативен, потому что выражение, которое появляется в числителе,
максимально, когда p-hat = 1/2 = 0,5.
Таким образом, полученное значение n будет давать нам желаемую погрешность независимо от значения p-hat. Это подход «наихудшего случая». Итак, когда мы это делаем, мы получаем:
В целом, для любого уровня достоверности мы имеем
- Если мы знаем разумную оценку пропорции, мы можем использовать:
- Если мы выбираем консервативную оценку, предполагая, что мы ничего не знаем об истинной пропорции, мы используем:
ПРИМЕР:
Похоже, что в опросах СМИ обычно используется размер выборки от 1000 до 1200 человек.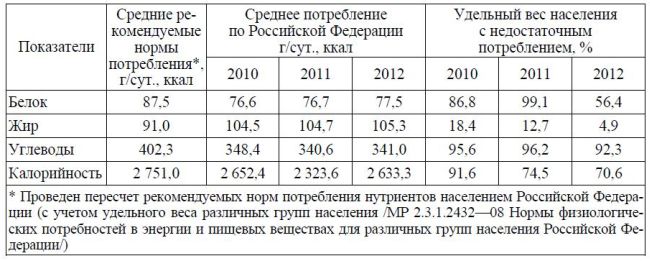 Это может озадачить.
Это может озадачить.
Каким образом результаты, полученные, скажем, от 1100 взрослых жителей США, могут дать нам информацию обо всем взрослом населении США? 1100 — это такая крошечная часть фактического населения. Вот ответ:
Какой размер выборки n необходим, если требуется погрешность m = 0,03?
(помните, всегда округляйте). Фактически, 0,03 — очень часто используемая погрешность, особенно для опросов СМИ. По этой причине большинство опросов СМИ работают с выборкой около 1100 человек.
Я понял?: Доверительные интервалы – Пропорции #2
Когда безопасно использовать эти методы?
Как мы упоминали ранее, одна из самых важных вещей, которую нужно изучить при работе с любым методом логического вывода, — это условия, при которых его безопасно использовать.
Как и для среднего значения, для разработки методов в этом подразделении мы сделали допущение о том, что выборочное распределение доли выборки p-hat является примерно нормальным. Напомним из блока вероятности, что условия, при которых это происходит, следующие: использовать методы, которые мы разработали в этом разделе.
Напомним из блока вероятности, что условия, при которых это происходит, следующие: использовать методы, которые мы разработали в этом разделе.
Вот последнее упражнение для этих доверительных интервалов!!
Я понял?: Доверительные интервалы – пропорции #3
Подведем итоги. , 1,96 для достоверности 95% и 2,576 для достоверности 99%.
Чтобы получить желаемую погрешность (m) в доверительном интервале для неизвестной доли населения, консервативный размер выборки составляет
Если известна разумная оценка истинной доли, размер выборки можно рассчитать с помощью
В год выборов мы видим в газетах статьи, в которых доверительные интервалы указываются в пропорциях или процентах. Например, опрос конкретного кандидата, баллотирующегося на пост президента, может показать, что кандидат имеет 40% голосов в пределах трех процентных пунктов (если выборка достаточно велика). Часто предвыборные опросы рассчитываются с 95% уверенности, поэтому социологи будут на 95% уверены, что истинная доля избирателей, поддерживающих кандидата, будет между 0,37 и 0,43: (0,40 – 0,03, 0,40 + 0,03).
Инвесторы на фондовом рынке заинтересованы в истинном соотношении акций, которые растут и падают каждую неделю. Предприятия, продающие персональные компьютеры, интересуются долей домохозяйств в США, владеющих персональными компьютерами. Доверительные интервалы можно рассчитать для истинной доли акций, которые растут или падают каждую неделю, и для истинной доли домохозяйств в США, владеющих персональными компьютерами.
Процедура определения доверительного интервала, размера выборки, границы ошибки и уровня достоверности для пропорции аналогична процедуре для среднего значения генеральной совокупности, но формулы разные.
Откуда вы знаете, что имеете дело с проблемой пропорций? Во-первых, базовое распределение является биномиальным распределением . (Нет упоминания о среднем или среднем значении.) Если X является биномиальной случайной величиной, то X ~ B 9, читайте “P hat”. )
)
Когда n велико, а p не близко ни к нулю, ни к единице, мы можем использовать нормальное распределение для аппроксимации бинома.
X~N(np,npq)X~N(np,npq)
Если мы разделим случайную величину, среднее и стандартное отклонение на n , мы получаем нормальное распределение пропорций P′ , называемое расчетная доля, как случайная величина. (Напомним, что пропорция количество успехов разделить на n .)
Xn=P′~ N(npn,npqn)Xn=P′~ N(npn,npqn)
Использование алгебры для упрощения: npqn=pqnnpqn=pqn
P0 следует за 9 нормальное распределение для пропорций : Xn=P′~ N(npn,npqn)Xn=P′~ N(npn,npqn)
Доверительный интервал имеет вид ( p′ – EBP , p′ + EBP ). EBP является ошибкой для пропорции.
EBP является ошибкой для пропорции.
р’ = xnxn
р’ = расчетная доля успехов ( p′ – это точечная оценка для p , истинная пропорция.)
Погрешность пропорции равна
EBP=(zα2)(p′q′n)EBP=(zα2)(p′q′n), где q′ = 1 – p′
Эта формула аналогична формуле границы ошибки для среднего , за исключением того, что «соответствующее стандартное отклонение» отличается. Для среднего значения, когда известно стандартное отклонение совокупности, используемое нами соответствующее стандартное отклонение равно σnσn. Для пропорции соответствующее стандартное отклонение равно pqnpqn.
Однако в формуле оценки погрешности мы используем
p’q’np’q’n в качестве стандартного отклонения вместо pqnpqn.
В формуле ограничения погрешности пропорции выборки p′ и q′ являются оценками неизвестных долей совокупности p и q . Расчетные пропорции p′ и q′ используются, потому что p и q неизвестны. Пропорции образца p′ и q′ рассчитываются по данным: p′ – расчетная доля успешных операций, а q′ – расчетная доля неудач.
Доверительный интервал можно использовать только в том случае, если количество успешных операций np’ и количество неудачных попыток nq’ больше пяти.
Примечание
Для нормального распределения пропорций формула z баллов выглядит следующим образом.
Если P′~N(p,pqn)P′~N(p,pqn), то z – формула оценки: z=p’-ppqnz=p’-ppqn
Пример 8.10
Проблема
Предположим, что фирма, занимающаяся исследованием рынка, нанята для оценки доли взрослых жителей большого города, имеющих мобильные телефоны. Пятьсот случайно выбранных взрослых жителей этого города опрашиваются, чтобы определить, есть ли у них сотовые телефоны. Из из 500 опрошенных 421 человек ответил утвердительно – у них есть сотовые телефоны. Используя уровень достоверности 95%, вычислите оценку доверительного интервала для истинной доли взрослых жителей этого города, имеющих мобильные телефоны.
Решение 1
- Первое решение — пошаговое.
- Второе решение использует функцию калькуляторов TI-83, 83+ или 84.
Пусть X = количество людей в выборке, у которых есть сотовые телефоны. х биномиально. Х~В(500,421500)Х~В(500,421500).
х биномиально. Х~В(500,421500)Х~В(500,421500).
Для расчета доверительного интервала необходимо найти p′ , q′ и EBP .
п = 500
x = количество успехов = 421
p′=xn=421500=0,842p′=xn=421500=0,842
p′ = 0,842 – доля выборки; это точечная оценка доли населения.
Q ′ = 1 – P ′ = 1 – 0,842 = 0,158
С CL = 0,95, затем α = 1 – CL = 1 – 0,95 = 0,05 (α2) (α2) (α2) (α2). = 0,025.
Тогда zα2=z0,025=1,96zα2=z0,025=1,96
Используйте команду калькулятора TI-83, 83+ или 84+ invNorm(0,975,0,1) найти z 0,025 . Помните, что площадь справа от z 0,025 равна 0,025, а слева от z 0,025 равна 0,975. Это также можно найти с помощью соответствующих команд на других калькуляторах, с помощью компьютера или с помощью таблицы вероятностей Standard Normal.
Помните, что площадь справа от z 0,025 равна 0,025, а слева от z 0,025 равна 0,975. Это также можно найти с помощью соответствующих команд на других калькуляторах, с помощью компьютера или с помощью таблицы вероятностей Standard Normal.
EBP=(zα2)p′q′n=(1,96)(0,842)(0,158)500=0,032EBP=(zα2)p′q′n=(1,96)(0,842)(0,158)500=0,032
p’ –ЭВП=0,842–0,032=0,81р’–ЭВП=0,842–0,032=0,81
p′+EBP=0,842+0,032=0,874p′+EBP=0,842+0,032=0,874
Доверительный интервал для истинной биномиальной доли населения равен ( p′ – EBP , p′ 3 EBP ) = (0,810, 0,874).
Интерпретация: Мы оцениваем с достоверностью 95%, что от 81% до 87,4% всех взрослых жителей этого города имеют сотовые телефоны.
Объяснение уровня достоверности 95%: 95% доверительных интервалов, построенных таким образом, будут содержать истинное значение доли всех взрослых жителей этого города, имеющих мобильные телефоны.
Решение 2
Пример 8.11
Проблема
В рамках классного проекта студент-политолог крупного университета хочет оценить процент студентов, зарегистрированных в качестве избирателей. Он опрашивает 500 студентов и обнаруживает, что 300 из них являются зарегистрированными избирателями. Вычислить 90% доверительный интервал для истинного процента учащихся, зарегистрированных в качестве избирателей, и интерпретировать доверительный интервал.
Решение 1
- Первое решение — пошаговое.
- Второе решение использует функцию калькуляторов TI-83, 83+ или 84.
х = 300 и n = 500
p’=xn=300500=0,600p’=xn=300500=0,600
q′=1-p′=1-0,600=0,400q′=1-p′=1-0,600=0,400
Так как CL = 0,90, то α = 1 – CL = 1 – 0,90 = 0,10(α2)(α2) = 0,05
zα2zα2 = z 0,05 = 1,645
Используйте команду калькулятора TI-83, 83+ или 84+ invNorm(0,95,0,1) найти z 0,05 . Помните, что площадь справа от z 0,05 равна 0,05, а слева от z 0,05 равна 0,95. Это также можно найти с помощью соответствующих команд на других калькуляторах, с помощью компьютера или с помощью стандартной таблицы нормальных вероятностей.
EBP=(zα2)p′q′n=(1,645)(0,60)(0,40)500=0,036EBP=(zα2)p′q′n=(1,645)(0,60)(0,40)500=0,036
p’–EBP=0,60-0,036=0,564p’-EBP=0,60-0,036=0,564
p′+EBP=0,60+0,036=0,636p′+EBP=0,60+0,036=0,636
Доверительный интервал для истинной биномиальной доли населения равен ( p′ – EBP , p′ + 3 EBP 6 ) = (0,564,0,636).
- Интерпретация: Мы оцениваем с достоверностью 90%, что истинный процент всех учащихся, зарегистрированных в качестве избирателей, составляет от 56,4% до 63,6%.
- Альтернативная формулировка: Мы оцениваем с достоверностью 90%, что от 56,4% до 63,6% ВСЕХ студентов являются зарегистрированными избирателями.

Объяснение уровня достоверности 90%: Девяносто процентов всех доверительных интервалов, построенных таким образом, содержат истинное значение процента учащихся, зарегистрированных в качестве избирателей.
Решение 2
Доверительный интервал «плюс четыре» для
pВ процесс вычисления доверительного интервала пропорции внесена определенная ошибка. Поскольку нам неизвестна истинная пропорция населения, мы вынуждены использовать точечные оценки для расчета соответствующего стандартного отклонения выборочного распределения. Исследования показали, что результирующая оценка стандартного отклонения может быть ошибочной.
К счастью, есть простая настройка, которая позволяет нам получать более точные доверительные интервалы. Мы просто делаем вид, что у нас есть четыре дополнительных наблюдения. Два из этих наблюдений являются успешными, а два — неудачными. Таким образом, новый размер выборки составляет 90 293 n 90 060 + 4, а новое количество успешных попыток — 90 293 x 90 060 + 2. 90 015
Таким образом, новый размер выборки составляет 90 293 n 90 060 + 4, а новое количество успешных попыток — 90 293 x 90 060 + 2. 90 015
Компьютерные исследования продемонстрировали эффективность этого метода. Его следует использовать, когда желаемый уровень достоверности составляет не менее 90%, а размер выборки не менее десяти.
Пример 8.12
Проблема
Случайной выборке из 25 студентов-статистиков был задан вопрос: «Выкурили ли вы сигарету на прошлой неделе?» Шесть студентов сообщили о курении в течение последней недели. Используйте метод «плюс четыре», чтобы найти 95-процентный доверительный интервал для истинной доли курящих студентов-статистиков.
Решение 1
Шесть студентов из 25 сообщили о курении в течение последней недели, поэтому x = 6 и n = 25. Поскольку мы используем метод «плюс четыре», мы будем использовать х = 6 + 2 = 8 и n = 25 + 4 = 29.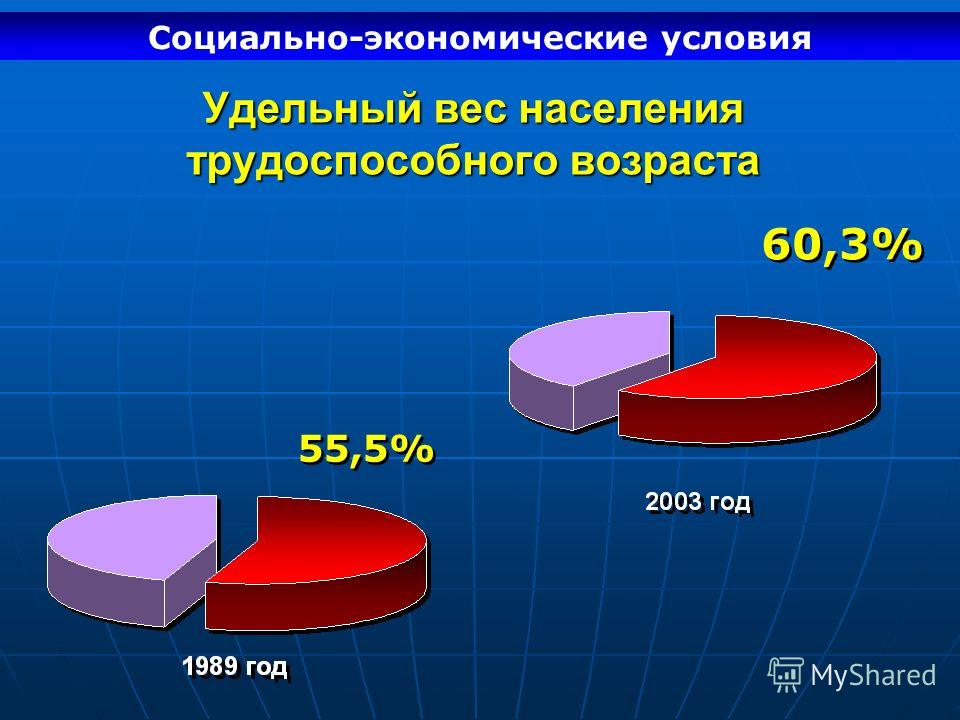
p′=xn=829≈0,276p′=xn=829≈0,276
q′=1–p′=1–0,276=0,724q′=1–p′=1–0,276=0,724
Поскольку CL = 0,95, мы знаем, что α = 1 – 0,95 = 0,05 и α2α2 = 0,025 .
z0,025=1,96z0,025=1,96
EPB=(zα2)p′q′n=(1,96)0,276(0,724)29≈0,163EPB=(zα2)p′q′n=(1,96)0,276(0,724)29≈0,163
p′ – EPB = 0,276 – 0,163 = 0,113
p′ + EPB = 0,276 + 0,163 = 0,439
Мы на 95% уверены, что истинная доля всех студентов статистики, курящих сигареты, находится между 0,113 и 0,439.
Решение 2
Пример 8.13
Проблема
Центр Беркмана по вопросам Интернета и общества в Гарварде недавно провел исследование, посвященное анализу привычек подростков-пользователей Интернета управлять конфиденциальностью. В группе из 50 подростков 13 сообщили, что у них более 500 друзей на Facebook. Используйте метод «плюс четыре», чтобы найти 90% доверительный интервал для истинной доли подростков, которые сообщили бы, что у них более 500 друзей в Facebook.
В группе из 50 подростков 13 сообщили, что у них более 500 друзей на Facebook. Используйте метод «плюс четыре», чтобы найти 90% доверительный интервал для истинной доли подростков, которые сообщили бы, что у них более 500 друзей в Facebook.
Решение 1
Используя «плюс четыре», мы имеем x = 13 + 2 = 15 и n = 50 + 4 = 54.
p’=1554≈0,278p’=1554≈0,278
q’=1–p’=1-0,241=0,722q’=1-p’=1-0,241=0,722
Поскольку CL = 0,90, мы знать α = 1 – 0,90 = 0,10 и α2α2 = 0,05.
z0,05=1,645z0,05=1,645
EPB=(zα2)(p′q′n)=(1,645)((0,278)(0,722)54)≈0,100EPB=(zα2)(p′q′n)=(1,645)((0,278)(0,722) 54)≈0,100
P ′ – EPB = 0,278 – 0,100 = 0,178
P ′ + EPB = 0,278 + 0,100 = 0,378
, мы будем на 90%.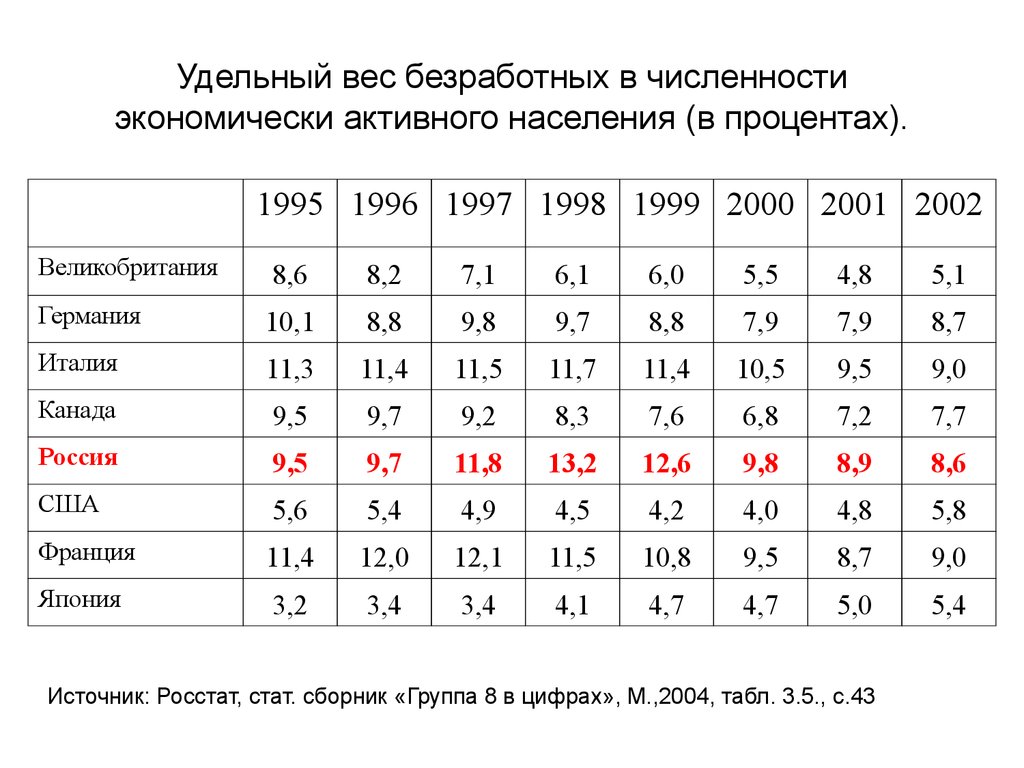 сообщить, что у него более 500 друзей на Facebook.
сообщить, что у него более 500 друзей на Facebook.
Решение 2
Расчет объема выборки
nЕсли исследователям нужна определенная погрешность, они могут использовать формулу ограничения погрешности для расчета требуемого размера выборки.
Формула ограничения погрешности для доли населения:
- EBP=(zα2)(p’q’n)EBP=(zα2)(p’q’n)
- Решение для n дает вам уравнение для размера выборки.
- n=(zα2)2(p′q′)EBP2n=(zα2)2(p′q′)EBP2
Пример 8.14
Проблема
Предположим, компания мобильной связи хочет определить текущую процентную долю клиентов в возрасте 50+, которые используют текстовые сообщения на своих мобильных телефонах. Сколько клиентов в возрасте 50+ должна опросить компания, чтобы получить 90% уверены, что оценочная (выборочная) доля находится в пределах трех процентных пунктов от истинной доли населения в возрасте 50+, использующих текстовые сообщения на своих мобильных телефонах.
Решение 1
Из задачи мы знаем, что EBP = 0,03 (3%=0,03) и zα2zα2 z 0,05 = 1,645, так как уровень достоверности составляет 90%.
Однако, чтобы найти n , нам нужно знать расчетную (выборочную) долю р ′. Помните, что q ′ = 1 – p ′. Но, мы пока не знаем p ′. Поскольку мы умножаем p ′ и q ′ вместе, мы делаем их оба равными 0,5, потому что p ′ q ′ = (0,5)(0,5) = 0,25 дает максимально возможное произведение. (Попробуйте другие продукты: (0,6)(0,4) = 0,24; (0,3)(0,7) = 0,21; (0,2)(0,8) = 0,16 и так далее). Максимально возможное произведение дает нам наибольшее n .