Намит трансформатор: Трансформатор НАМИТ-10
alexxlab | 07.05.2023 | 0 | Разное
| |||||||||||||||||||||||||||||||||||||||||||||||||

Трансформатор НАМИТ-10-2
Трансформатор НАМИТ-10-2 (аналог трансформатора НАМИ-10-95) является трехфазным антирезонансным масляным трансформатором напряжения. Применяется для понижения высокого первичного напряжения до значений пригодных для измерений. Служит для выработки сигнала измерительной информации и подачи его на измерительные приборы, а также устройства защиты и сигнализации в сетях с изолированной нейтралью частоты 50 (60) Гц. Предназначен для установки в комплектных распределительных устройствах.
Применяется для понижения высокого первичного напряжения до значений пригодных для измерений. Служит для выработки сигнала измерительной информации и подачи его на измерительные приборы, а также устройства защиты и сигнализации в сетях с изолированной нейтралью частоты 50 (60) Гц. Предназначен для установки в комплектных распределительных устройствах.
Трансформатор НАМИТ-10-2 имеет климатическое исполнение “УХЛ” категории размещения 2 и его необходимо эксплуатировать при следующих условиях:
– Установку необходимо производить на высоте не превышающей 1000м над уровнем моря;
– Температура воздуха внутри КРУ от -60°C до +40°C;
– Неагрессивная и не взрывоопасная окружающая среда.
Внимание! Основное отличие конструктивного исполнения “1” от исполнения “2”. Для трансформатора НАМИТ-10-1 первичные обмотки одного трансформатора предназначены для включения на линейные напряжения “AB” и “BC”, а первичная обмотка другого (заземленного) трансформатора включается на фазное напряжение “BX”. Для трансформатора НАМИТ-10-2 первичные обмотки трехфазного трехстержневого трансформатора включаются на линейные напряжения “AB”, “BC” и “CA” и служат для питания и защиты цепей электроизмерительных приборов, а первичная обмотка однофазного трансформатора нулевой последовательности предназначена для включения в нейтраль основного трансформатора и служит для защиты трехфазного трансформатора от повреждения при однофазных замыканиях и феррорезонанса.
Для трансформатора НАМИТ-10-2 первичные обмотки трехфазного трехстержневого трансформатора включаются на линейные напряжения “AB”, “BC” и “CA” и служат для питания и защиты цепей электроизмерительных приборов, а первичная обмотка однофазного трансформатора нулевой последовательности предназначена для включения в нейтраль основного трансформатора и служит для защиты трехфазного трансформатора от повреждения при однофазных замыканиях и феррорезонанса.
Конструкция: Трансформатор НАМИТ-10-2 состоит из трехфазного трехстержневого трансформатора прямой (обратной) последовательности и однофазного двухстержневого трансформатора нулевой последовательности. Активная часть состоит из магнитопровода изготавливаемого из холоднокатаной электротехнической стали, обмоток и выводов ВН, НН. Обмотки трансформатора изготавливают из медных проводов. Выводы обмоток – съемные проходные фарфоровые изоляторы. Обмотки закрепляются на соответствующих стержнях магнитопровода, после выполняются электротехнические соединения и сушка под вакуумом. Проверяются все электротехнические параметры трансформатора, и только после этого активная часть помещается в бак. Сверху крепится крышка и после этого трансформатор наполняют маслом. Трансформатор НАМИТ-10-2 имеет сварной бак. Удобство монтажа обеспечивается благодаря скобам, расположенным на крышке бака трансформатора. В низу бака расположены пробка для слива и взятия пробы масла, а также болт заземления. Пробка для заливки масла находится на крышке бака возле выводов обмоток ВН, НН.
Проверяются все электротехнические параметры трансформатора, и только после этого активная часть помещается в бак. Сверху крепится крышка и после этого трансформатор наполняют маслом. Трансформатор НАМИТ-10-2 имеет сварной бак. Удобство монтажа обеспечивается благодаря скобам, расположенным на крышке бака трансформатора. В низу бака расположены пробка для слива и взятия пробы масла, а также болт заземления. Пробка для заливки масла находится на крышке бака возле выводов обмоток ВН, НН.
Чертеж, габаритные и установочные размеры трансформатора НАМИТ-10-2
Трансформатор НАМИТ-10-2 обладает следующими техническими характеристиками:
| Наименование параметра | Значение | |
| Класс точности | 0,2 | 0,5 |
| Значение номинального напряжения первичной обмотки, кВ | 10; 6; (6,3) | |
| Значение наибольшего рабочего напряжения, кВ | 7,2; 12 | |
Значение номинального напряжения основной вторичной обмотки, кВ | 0,1; (0,11) | |
| Значение номинального напряжения дополнительной вторичной обмотки, кВ | 0,1/3; (0,11/3) | |
Значение номинальной мощности обмоток, ВА, при симметричной нагрузке основной вторичной в классе точности: – 0,2 – 0,5 – 1 – 3 дополнительной вторичной |
75 150 270 600 30 |
– 200 300 600 30 |
Значение предельной мощности вне класса точности, ВА: – трансформатора – основных вторичных обмоток – дополнительных вторичных обмоток |
1000 900 100 | |
| Значение частоты переменного тока, Гц | 50 | |
| Схема и группа соединений обмоток | Ун/Ун/П-0 | |
| Масса, кг | 110 | |
Видео трансформатора НАМИТ-10-2 6000/100:
Фото трансформатора НАМИТ-10-2:
- Шильдик трансформатора НАМИТ-10-2 6000/100 Шильдик трансформатора НАМИТ-10-2 6000/100
- Трансформатор НАМИТ-10-2 10000/100 Трансформатор НАМИТ-10-2 10000/100
- Трансформатор НАМИТ-10-2 10000/100 Трансформатор НАМИТ-10-2 10000/100
- Трансформатор НАМИТ-10-2 10000/100 Трансформатор НАМИТ-10-2 10000/100
- Трансформатор НАМИТ-10-2 10000/100 Трансформатор НАМИТ-10-2 10000/100
- Трансформатор НАМИТ-10-2 6000/100 Трансформатор НАМИТ-10-2 6000/100
- Трансформатор НАМИТ-10-2 6000/100 Трансформатор НАМИТ-10-2 6000/100
- Трансформатор НАМИТ-10-2 6000/100 Трансформатор НАМИТ-10-2 6000/100
Смотреть встроенную онлайн галерею в:
http://energosfera.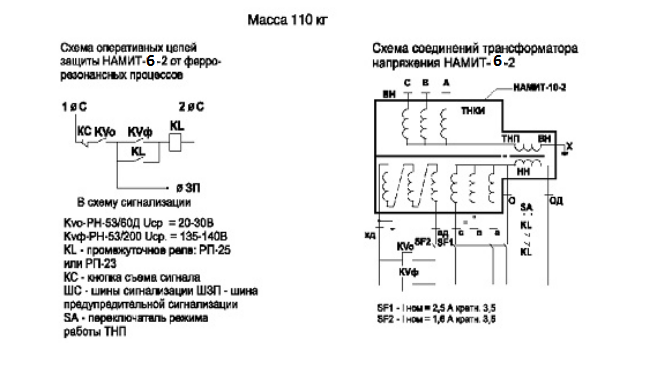 org.ua/transformatory/izmeritelnye-transformatory-napryazheniya/trekhfaznye-maslyanye-izmeritelnye-transformatory-napryazheniya-10kv/transformator-namit-10-2.html#sigProId30d4af82cd
org.ua/transformatory/izmeritelnye-transformatory-napryazheniya/trekhfaznye-maslyanye-izmeritelnye-transformatory-napryazheniya-10kv/transformator-namit-10-2.html#sigProId30d4af82cd
Под заказ трансформаторы типа НАМИТ-10-2 комплектуются защитными прозрачными крышками для раздельного пломбирования выводов вторичных обмоток для измерения.
Фото трансформатора НАМИТ-10 с защитными крышками для пломбирования вторичных выводов:
Заказывайте трансформатор НАМИТ-10-2 в компании “ЭнергоСфера” по телефону:
| (050)299-33-89 | (068)256-29-77 | (093)113-81-73 |
| – – Работаем на Экспорт – – Работаем на Экспорт – – |
- < Трансформатор НТМ-10
- Трансформатор ЗНАМИТ-10-1 >
Именование Трансформеров — Transformers Wiki
У всех Трансформеров есть имя, которое является прозвищем, которое они сами и другие используют для обозначения того, о ком идет речь.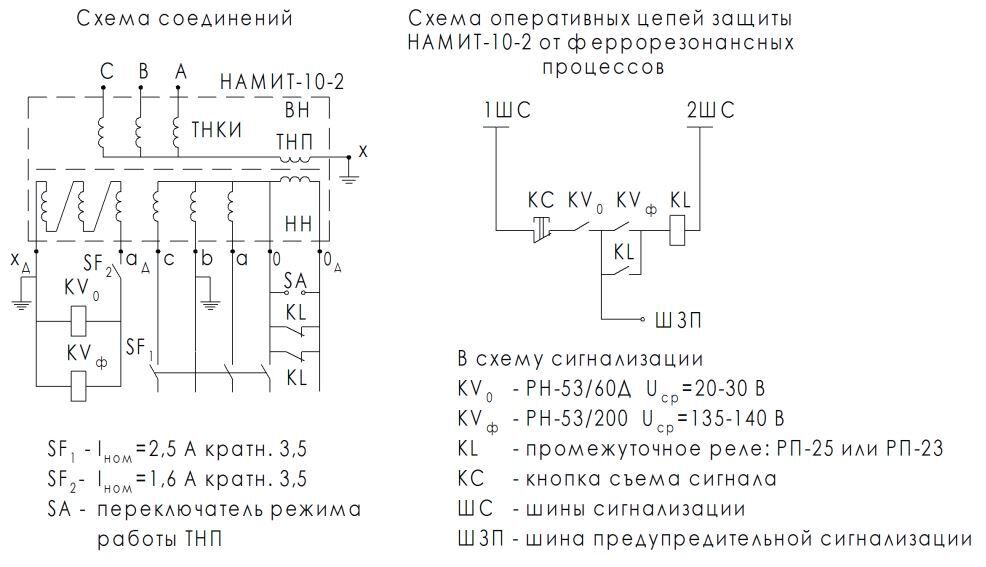 Иногда, когда Трансформер принимает новое тело, он также пользуется возможностью взять новое имя, которое может лучше соответствовать его новой форме.
Иногда, когда Трансформер принимает новое тело, он также пользуется возможностью взять новое имя, которое может лучше соответствовать его новой форме.
Амбулон: От глагола «ходить», что означает «ходить». Глупое имя…
…но все лучшие имена заняты. Амбулон и Рэтчет, Как Рэтчет вернул себе руки
Содержимое
|
Художественная литература
Поколение 1
Преемственность комиксов Marvel
Бамблби сказал Уитвики, что «Шмель» — это его кодовое имя. Силовая игра!
Силовая игра!
Трансформеры имели имена на родном языке. Эти имена часто непроизносимы для некибертронцев. По прибытии на Землю Трансформеры взяли английские кодовые имена. Человек из железа
Beast Wars мультипликационная преемственностьПрибыв на новую планету и приняв альтернативные режимы, отсканированные от местных форм жизни, Трансформеры обычно брали имена, соответствующие их новым формам. Активированные протоформы сделали то же самое.
События из книг IDW Publishing или Fun Publications выделены курсивом.
Автоботы, посетившие учебный лагерь автоботов, получили имена в зависимости от их особых способностей или личных качеств. Длиннорукий был назван в честь его способности вытягивать конечности, Айронхайд — из-за его способности покрывать себя броней, Переборка — из-за его размера и кажущегося отсутствия интеллекта, а Оса и Шмель — из-за их относительной точности (или неточности) с их жалом. . Лагерь автозагрузки
. Лагерь автозагрузки
Куп назвал многих молодых автоботов, в том числе Оптимуса за его оптимизм, Стража за его бдительность, Элиту-1 за его снобское поведение, Скрама за его импульсивное безрассудство, Быстрострела за ее навыки стрельбы, Бластера за его любовь к музыке и Hot Rod за то, что он ярко-красный с наклейками пламени. Альманах AllSpark II
TransTech преемственность Axiom Nexus заставила Джекпота взять новое имя, чтобы отличаться от других “Джекпотов”. Зашел слишком далекоПреемственность фильма с живыми актерами
Оптимус Прайм объяснил, что обозначения отдельных Трансформеров не могут быть правильно переведены на английский язык, что приводит к тому, что автоботы принимают обозначения, основанные на их личностях. Номер три адаптации к фильму Оптимус также попросил ненадолго подумать о подходящих обозначениях для двух десептиконов, терроризировавших Рим, и, наконец, придумал Swindle и Deadend. Скрытая угроза Наконец, Джетфайру потребовалось несколько минут, чтобы подобрать подходящий дескриптор на основе ограниченного разговора, который он услышал от группы Сэма Уитвики.![]() Месть падших (роман)
Месть падших (роман)
2005 Преемственность IDW
Хотя трансформеры встречаются редко, их полные имена указывают, откуда они на Кибертроне, подобно человеческой частице von . Примеры включают Megatron of Tarn, Chaos Theory Part 1 Orion Pax of Iacon, Chaos Theory Part 2 Galvatron of Protohex, Straxus of Yuss, Jhiaxus of Tesarus Minor, Post Hoc Cyclonus of Tetrahex и Rewind of Lower Petrohex. Маленькие победы Солдаты «Сделанные на заказ», рожденные во время войны, не имеют городов рождения, но вместо этого названы в честь военных кампаний, для участия в которых они были созданы. Операция: Роковой патруль. Двадцать плюс один
Некоторые трансформеры также имеют дополнительное имя, обозначающее, к какому дому они принадлежат. Дом Амбуса
Первоначально автобот Дент носил имя Проул, но был вынужден изменить свое имя, чтобы избежать путаницы со своим более известным тезкой. Жизнь после Большого Взрыва Позже медик Амбулон сообщил, что его имя произошло от глагола «амбулировать», что означает «ходить», потому что его альтернативным способом передвижения была нога.
После волны смерти Некротитана Старскрим подвергся словесной критике со стороны многих граждан Иакона, в том числе двух отдельных танкоров, которые он нашел символом того, как проходит его день. В то же время Слэг, который был тяжело ранен тем же событием, объяснил Свупу, что меняет свое имя на «Слаг», потому что Арси сочла его оскорбительным. нет выхода
Примечания
- Во многих преемственностях Трансформеры просто имеют имена без конкретного объяснения их происхождения. Это иногда приводит к несоответствиям, таким как Джаз, носивший название «Джаз» на Кибертроне за миллионы лет до изобретения джазовой музыки.
- Большинство имен Трансформеров в японской художественной литературе и линиях игрушек — английские слова. Заметными исключениями являются члены Trainbots и Dinoforce.

- Большинство имен Трансформеров в западной художественной литературе и линиях игрушек происходят от английских слов. Заметному меньшинству даются имена, полученные из латыни и псевдо-латыни, и обычно даются более «элитным» персонажам. Примеры включают:
- Децимус — десятый , имя, первоначально использовавшееся для десятого сына в семье.
- Оптимус — лучший , в именительном падеже мужского рода.
- Ультра Магнус
- Ультра — наречие или предлог, означающий за пределами .
- Магнус — большой или большой , в именительном падеже мужского рода.
- Примеры псевдолатинских имен включают Jhiaxus, Legonis, Octus, Rodimus и Megatronus.
- Другое меньшинство имен Трансформеров происходит от древнегреческого (через латынь) и иврита. Имена древнегреческого происхождения включают Альфа Трион, Бета, Орион/Орион Пакс, Дион, Андромеда и Кассиопея. Имена, производные от иврита, включают Ариэль и Авель.

См. также
- Переименование
- Имена трансформаторов в других линиях Hasbro
Что такое модель-трансформер?
Если вы хотите оседлать новую волну ИИ, возьмите трансформатор.
Это не игрушечные роботы-оборотни из телевизора и не бадьи размером с мусорное ведро на телефонных столбах.
Итак, что такое модель-трансформер?Модель преобразователя — это нейронная сеть, которая изучает контекст и, таким образом, значение, отслеживая отношения в последовательных данных, таких как слова в этом предложении.
Модели-трансформеры применяют постоянно развивающийся набор математических методов, называемых вниманием или само-вниманием, для обнаружения неуловимых способов, которыми даже отдаленные элементы данных в ряду влияют друг на друга и зависят друг от друга.
Трансформеры, впервые описанные в статье Google за 2017 год, являются одними из новейших и самых мощных классов моделей, изобретенных на сегодняшний день. Они продвигают волну достижений в области машинного обучения, которую некоторые называют искусственным интеллектом-трансформером.
Они продвигают волну достижений в области машинного обучения, которую некоторые называют искусственным интеллектом-трансформером.
Исследователи из Стэнфорда назвали трансформеры «основными моделями» в статье от августа 2021 года, потому что они видят, что они вызывают сдвиг парадигмы в ИИ. «Масштаб и размах моделей фундамента за последние несколько лет расширили наше представление о том, что возможно», — написали они.
Что могут модели-трансформеры?Transformers переводят текст и речь практически в режиме реального времени, открывая встречи и классы для разных участников и людей с нарушениями слуха.
Они помогают исследователям понять цепочки генов в ДНК и аминокислоты в белках таким образом, чтобы ускорить разработку лекарств. Преобразователи
, иногда называемые базовыми моделями, уже используются со многими источниками данных для множества приложений. Трансформаторы могут обнаруживать тенденции и аномалии для предотвращения мошенничества, оптимизации производства, предоставления онлайн-рекомендаций или улучшения здравоохранения.![]()
Люди используют трансформеры каждый раз, когда ищут в Google или Microsoft Bing.
Эффективный цикл Transformer AIЛюбое приложение, использующее последовательные текстовые, графические или видеоданные, является кандидатом для моделей Transformer.
Это позволяет этим моделям двигаться по благотворному циклу ИИ-трансформера. Преобразователи, созданные с использованием больших наборов данных, делают точные прогнозы, которые способствуют их более широкому использованию, генерируя больше данных, которые можно использовать для создания еще более совершенных моделей.
Исследователи из Стэнфорда говорят, что трансформеры знаменуют собой следующий этап развития ИИ, который некоторые называют эрой ИИ-трансформеров.«Трансформеры сделали возможным обучение с самоконтролем, а искусственный интеллект достиг невероятной скорости», — сказал основатель и генеральный директор NVIDIA Дженсен Хуанг в своем программном выступлении на этой неделе в GTC.
Преобразователи заменяют CNN, RNN Преобразователи во многих случаях заменяют сверточные и рекуррентные нейронные сети (CNN и RNN), самые популярные типы моделей глубокого обучения всего пять лет назад.
Действительно, 70 процентов статей arXiv по ИИ, опубликованных за последние два года, упоминают трансформаторы. Это радикальный сдвиг по сравнению с исследованием IEEE 2017 года, в котором сообщалось, что RNN и CNN были наиболее популярными моделями распознавания образов.
Без меток, выше производительностьДо появления преобразователей пользователям приходилось обучать нейронные сети с помощью больших помеченных наборов данных, создание которых требовало больших затрат и времени. Находя закономерности между элементами математически, преобразователи устраняют эту необходимость, делая доступными триллионы изображений и петабайты текстовых данных в Интернете и в корпоративных базах данных.
Кроме того, математика, которую используют трансформеры, поддается параллельной обработке, поэтому эти модели могут работать быстро.
Трансформеры теперь доминируют в популярных списках лидеров по производительности, таких как SuperGLUE, эталонный тест, разработанный в 2019 году для систем обработки языков.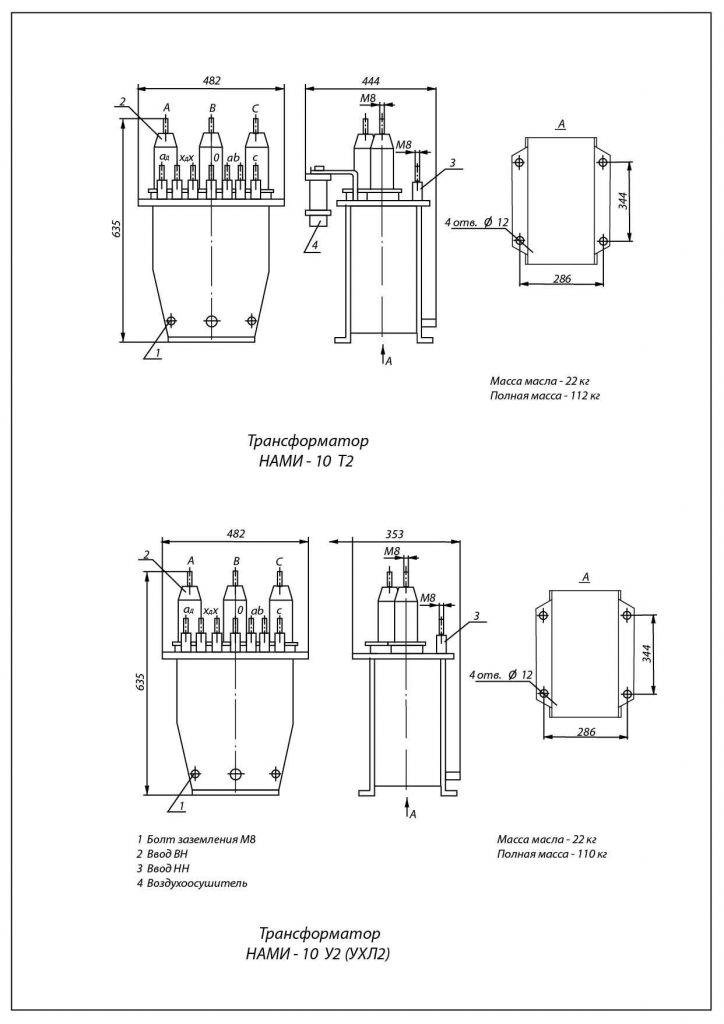
Как и большинство нейронных сетей, модели трансформеров представляют собой большие блоки кодировщика/декодера, которые обрабатывают данные.
Небольшие, но важные дополнения к этим блокам (показаны на диаграмме ниже) делают трансформаторы уникально мощными.
Заглянуть под капот из презентации Эйдана Гомеса, одного из восьми соавторов статьи 2017 года, в которой даны определения трансформаторов. Трансформаторыиспользуют позиционные энкодеры для маркировки элементов данных, входящих и исходящих из сети. Единицы внимания следуют этим тегам, вычисляя своего рода алгебраическую карту того, как каждый элемент соотносится с другими.
Запросы на внимание обычно выполняются параллельно путем вычисления матрицы уравнений в так называемом многоголовом внимании.
С помощью этих инструментов компьютеры могут видеть те же закономерности, что и люди.
Самовнимание находит смыслНапример, в предложении:
Она наливала воду из кувшина в чашку, пока она не наполнилась.
Мы знаем, что «это» относится к чашке, а в предложении:
Она лила воду из кувшина в чашку, пока та не опустела.
Мы знаем, что «это» относится к кувшину.
«Смысл — это результат взаимосвязей между вещами, а внимание к себе — это общий способ изучения взаимосвязей», — сказал Ашиш Васвани, бывший старший научный сотрудник Google Brain, руководивший работой над основополагающей статьей 2017 года.
«Машинный перевод был хорошим средством проверки собственного внимания, потому что вам нужны были короткие и длинные отношения между словами», — сказал Васвани.
«Теперь мы видим, что внимание к себе — мощный и гибкий инструмент для обучения», — добавил он.
Как трансформеры получили свое названиеВнимание настолько важно для трансформеров, что исследователи Google почти использовали этот термин в качестве названия своей модели 2017 года. Почти.
«Attention Net звучит не очень захватывающе», — сказал Васвани, который начал работать с нейронными сетями в 2011 году9. 0003
0003
.Jakob Uszkoreit, старший инженер-программист в команде, придумал название Transformer.
«Я утверждал, что мы трансформировали представления, но это была просто игра в семантику», — сказал Васвани.
Рождение трансформеровВ статье для конференции NeurIPS 2017 команда Google описала свой трансформер и рекорды точности, которые он установил для машинного перевода.
Благодаря набору методов они обучили свою модель всего за 3,5 дня на восьми графических процессорах NVIDIA, что составляет небольшую часть времени и стоимости обучения предыдущих моделей. Они обучили его на наборах данных, содержащих до миллиарда пар слов.
«Это был интенсивный трехмесячный спринт до даты подачи статьи», — вспоминает Эйдан Гомес, стажер Google в 2017 году, который участвовал в работе.
«В ту ночь, когда мы отправляли заявку, мы с Ашишем всю ночь работали в Google, — сказал он. «Я успел поспать пару часов в одном из небольших конференц-залов и проснулся как раз вовремя для представления, когда кто-то, пришедший рано на работу, открыл дверь и ударил меня по голове».
Это был тревожный звонок во многих смыслах.
«Той ночью Ашиш сказал мне, что он был убежден, что это будет иметь большое значение, что-то, что изменит правила игры. Я не был убежден, я думал, что это будет скромный выигрыш в тесте, но оказалось, что он был очень прав», — сказал Гомес, который сейчас является генеральным директором стартапа Cohere, предоставляющего услуги языковой обработки на основе трансформеров.
Момент для машинного обученияВасвани вспоминает волнение, когда увидел, что результаты превосходят аналогичную работу, опубликованную командой Facebook с использованием CNN.
«Я понимаю, что это может стать важным моментом в машинном обучении», — сказал он.
Год спустя другая команда Google пыталась обрабатывать текстовые последовательности как в прямом, так и в обратном направлении с помощью преобразователя. Это помогло зафиксировать больше взаимосвязей между словами, улучшив способность модели понимать значение предложения.
Их модель Bidirectional Encoder Representations from Transformers (BERT) установила 11 новых рекордов и стала частью алгоритма поиска Google.
В течение нескольких недель исследователи по всему миру адаптировали BERT для вариантов использования во многих языках и отраслях, «потому что текст — это один из самых распространенных типов данных, которые есть в компаниях», — сказал Андерс Арптег, 20-летний ветеран исследований в области машинного обучения.
Внедрение трансформаторов в работуВскоре модели трансформаторов стали адаптировать для науки и здравоохранения.
Компания DeepMind в Лондоне углубила свои знания о белках, строительных кирпичиках жизни, используя преобразователь под названием AlphaFold2, описанный в недавней статье в Nature. Он обрабатывал цепочки аминокислот, как текстовые строки, чтобы установить новый водяной знак для описания того, как укладываются белки, работа, которая может ускорить открытие лекарств.
AstraZeneca и NVIDIA разработали MegaMolBART, преобразователь, предназначенный для разработки лекарств. Это версия трансформатора MolBART фармацевтической компании, обученная на большой немаркированной базе данных химических соединений с использованием платформы NVIDIA Megatron для создания крупномасштабных моделей трансформаторов.
Это версия трансформатора MolBART фармацевтической компании, обученная на большой немаркированной базе данных химических соединений с использованием платформы NVIDIA Megatron для создания крупномасштабных моделей трансформаторов.
«Точно так же, как языковые модели ИИ могут изучать отношения между словами в предложении, наша цель состоит в том, чтобы нейронные сети, обученные на данных о молекулярной структуре, могли изучать отношения между атомами в реальном времени. молекулы мира», — сказал Ола Энгквист, глава отдела молекулярного ИИ, научных открытий и исследований и разработок в AstraZeneca, когда в прошлом году было объявлено о работе.
Отдельно академический медицинский центр Университета Флориды сотрудничал с исследователями NVIDIA для создания GatorTron.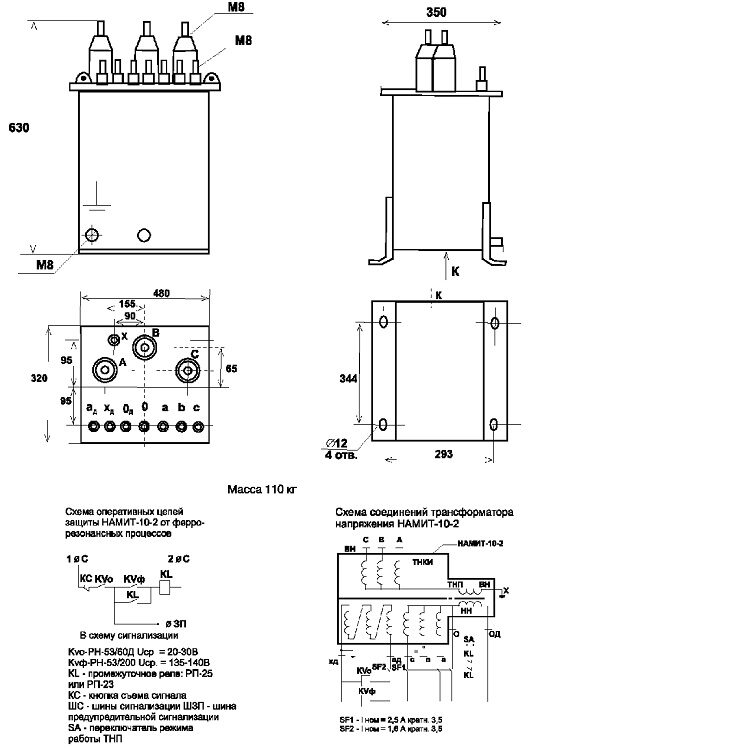 Модель преобразователя направлена на извлечение информации из огромных объемов клинических данных для ускорения медицинских исследований.
Модель преобразователя направлена на извлечение информации из огромных объемов клинических данных для ускорения медицинских исследований.
Попутно исследователи обнаружили, что большие трансформаторы работают лучше.
Например, исследователи из Ростлаборатории Технического университета Мюнхена, которые помогли первопроходцам в работе на стыке ИИ и биологии, использовали обработку естественного языка для понимания белков. Через 18 месяцев они закончили использовать RNN с 90 миллионов параметров для моделей трансформаторов с 567 миллионами параметров.
Исследователи Ростлаба показывают, что языковые модели, обученные без меченых образцов, улавливают сигнал последовательности белка.Лаборатория OpenAI показала, что чем больше, тем лучше с помощью генеративного предварительно обученного преобразователя (GPT). Последняя версия GPT-3 , имеет 175 миллиардов параметров по сравнению с 1,5 миллиардами для GPT-2.
Обладая дополнительным весом, GPT-3 может отвечать на запрос пользователя даже в тех задачах, для решения которых он не был специально обучен. Его уже используют такие компании, как Cisco, IBM и Salesforce.
Его уже используют такие компании, как Cisco, IBM и Salesforce.
В ноябре NVIDIA и Microsoft достигли высшей отметки, объявив о модели Megatron-Turing Natural Language Generation (MT-NLG) с 530 миллиардами параметров. Он дебютировал вместе с новой структурой NVIDIA NeMo Megatron, цель которой — позволить любому бизнесу создавать свои собственные преобразователи с параметрами в миллиард или триллион для обеспечения работы пользовательских чат-ботов, личных помощников и других приложений ИИ, понимающих язык.
MT-NLG публично дебютировал в качестве мозга для TJ, аватара Той Дженсен, который выступил с основным докладом на GTC NVIDIA в ноябре 2021 года.
«Когда мы увидели, как TJ отвечает на вопросы — мощность нашей работы продемонстрировал наш генеральный директор — это было захватывающе», — сказал Мостофа Патвари, возглавлявший команду NVIDIA, занимавшуюся обучением модели.
«Мегатрон помогает мне ответить на все эти трудные вопросы, которые Дженсен задает мне», — сказал TJ на GTC 2022.
Создание таких моделей не для слабонервных. MT-NLG обучался с использованием сотен миллиардов элементов данных, процесс, который требовал, чтобы тысячи графических процессоров работали в течение нескольких недель.
«Обучение больших моделей трансформеров дорого и требует много времени, поэтому, если вы не добьетесь успеха в первый или во второй раз, проекты могут быть отменены», — сказал Патвари.
Трансформаторы с триллионами параметровСегодня многие инженеры ИИ работают над трансформаторами с триллионами параметров и приложениями для них.
«Мы постоянно изучаем, как эти большие модели могут улучшить работу приложений. Мы также изучаем, в каких аспектах они терпят неудачу, поэтому мы можем создавать еще более совершенные и большие», — сказал Патвари.
Чтобы обеспечить вычислительную мощность, необходимую этим моделям, наш новейший ускоритель — графический процессор NVIDIA h200 с тензорными ядрами — включает в себя Transformer Engine и поддерживает новый формат FP8.![]() Это ускоряет обучение, сохраняя при этом точность.
Это ускоряет обучение, сохраняя при этом точность.
Благодаря этим и другим достижениям «обучение моделей-трансформеров можно сократить с недель до дней», — сказал Хуан из GTC.
MoE означает больше для трансформаторов
В прошлом году исследователи Google описали Switch Transformer, одну из первых моделей с триллионом параметров. Он использует разреженность ИИ, сложную архитектуру, состоящую из нескольких экспертов (MoE), и другие усовершенствования для повышения производительности при обработке языка и до 7-кратного увеличения скорости перед обучением.
Энкодер для Switch Transformer, первая модель с триллионом параметров.Со своей стороны, Microsoft Azure работала с NVIDIA над внедрением преобразователя MoE для своей службы Translator.
Решение проблем, связанных с трансформаторами Теперь некоторые исследователи стремятся разработать более простые трансформаторы с меньшим количеством параметров, которые обеспечивают производительность, аналогичную самым большим моделям.![]()
«Я вижу многообещающие модели, основанные на поиске, которые меня очень волнуют, потому что они могут изменить кривую», — сказал Гомес из Cohere, упомянув в качестве примера модель Retro от DeepMind.
Модели, основанные на поиске, обучаются, отправляя запросы в базу данных. «Это круто, потому что вы можете выбирать, что добавлять в эту базу знаний», — сказал он.
В гонке за более высокой производительностью модели-трансформеры стали крупнее.Конечная цель состоит в том, чтобы «заставить эти модели учиться так же, как люди, из контекста в реальном мире с очень небольшим количеством данных», — сказал Васвани, ныне соучредитель стартапа в области искусственного интеллекта.
Он представляет будущие модели, которые будут выполнять больше предварительных вычислений, поэтому им потребуется меньше данных, и у них будут лучшие способы обратной связи с пользователями.
«Наша цель — создавать модели, которые помогут людям в их повседневной жизни», — сказал он о своем новом предприятии.![]()
Другие исследователи изучают способы устранения предвзятости или токсичности, если модели усиливают неправильный или вредный язык. Например, Стэнфорд создал Центр исследований базовых моделей для изучения этих вопросов.
«Это важные проблемы, которые необходимо решить для безопасного развертывания моделей», — сказал Шримаи Прабхумо, научный сотрудник NVIDIA, один из многих представителей отрасли, работающих в этой области.
«Сегодня большинство моделей ищут определенные слова или фразы, но в реальной жизни эти проблемы могут проявляться незаметно, поэтому мы должны учитывать весь контекст», — добавил Прабхумо.
«Это главная забота Cohere, — сказал Гомес. «Никто не будет использовать эти модели, если они навредят людям, поэтому ставка на стол — сделать самые безопасные и ответственные модели».
За горизонтом Васвани представляет себе будущее, в котором самообучающиеся, управляемые вниманием трансформеры приближаются к священному Граалю искусственного интеллекта.![]()