Расшифровка 12хн3а: Сталь 12ХН3А – расшифровка марки стали, ГОСТ, характеристика материала
alexxlab | 02.03.2023 | 0 | Разное
Сталь 12ХН3А – расшифровка марки стали, ГОСТ, характеристика материала
- Нелегированные стали
- Легированные стали
- Нержавеющие стали
- 65Г
- ШХ15
- Р18
- Р6М5
- 9ХС
- ХВГ
- 09Г2С
- Х12МФ
- 12Х1МФ
- 12ХН3А
- 20Х
- 30ХМА
- 30ХГСА
- 40Х
- 40ХН
- 45Х
Марка стали – 12ХН3А
Стандарт – ГОСТ 4543
Заменитель – 12ХН2, 20ХН3А, 25ХГТ, 12Х2Н4А, 20ХНР
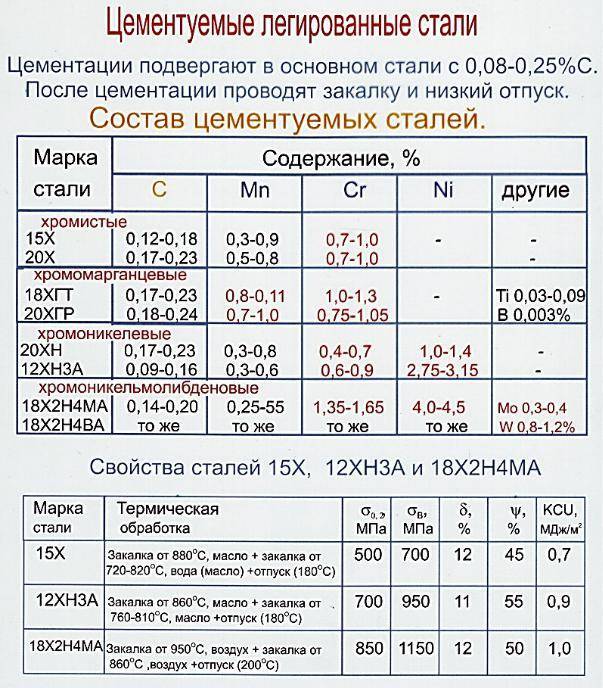
Сталь 12ХН3А содержит в среднем 0,12% углерода, Х – указывает содержание хрома в стали примерно 1%, Н3 – указывает содержание никеля в стали около 3%, буква А в конце марки означает, что сталь относится к категории высококачественной.
Сталь 12ХН3А применяется для изготовления крупных ответственных деталей. Изделия из стали подвергаются цементации с последующей термической обработкой, иногда эта сталь применяется для нецементируемых деталей. Сталь с высокими прочностью, вязкостью и прокаливаемостью.
Сталь с высокими прочностью, вязкостью и прокаливаемостью.
Из стали 12ХН3А изготовляют шестерни, оси, валы, червяки, кулачковые муфты, поршневые пальцы и другие детали.
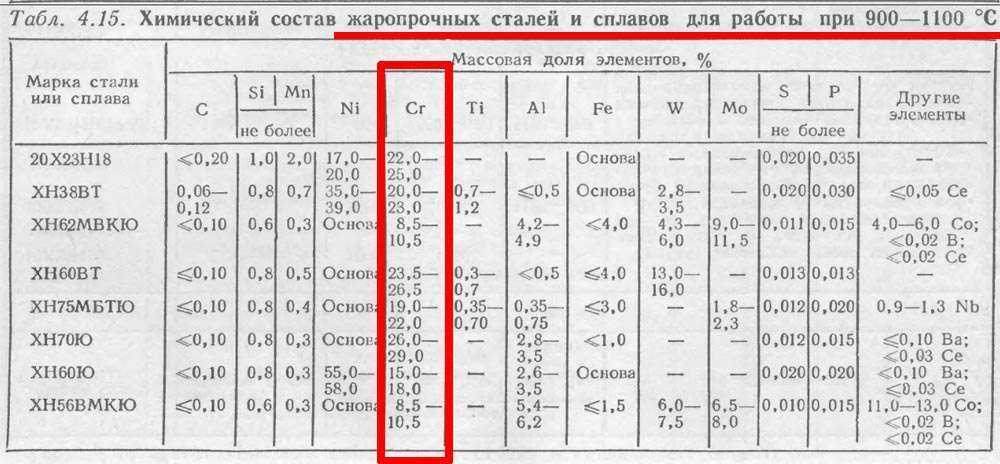
| Массовая доля основных химических элементов, % | ||||
|---|---|---|---|---|
| C – углерода | Si – кремния | Mn – марганца | Cr – хрома | Ni – никеля |
| 0,09-0,16 | 0,17-0,37 | 0,30-0,60 | 0,60-0,90 | 2,75-3,15 |
| Температура критических точек, °С | |||
|---|---|---|---|
| Ac1 | Ac3 | Ar1 | Ar3 |
| 715 | 773 | 659 | 726 |
| Технологические свойства | |
|---|---|
| Ковка | Температура ковки, °С: начала 1220, конца 800.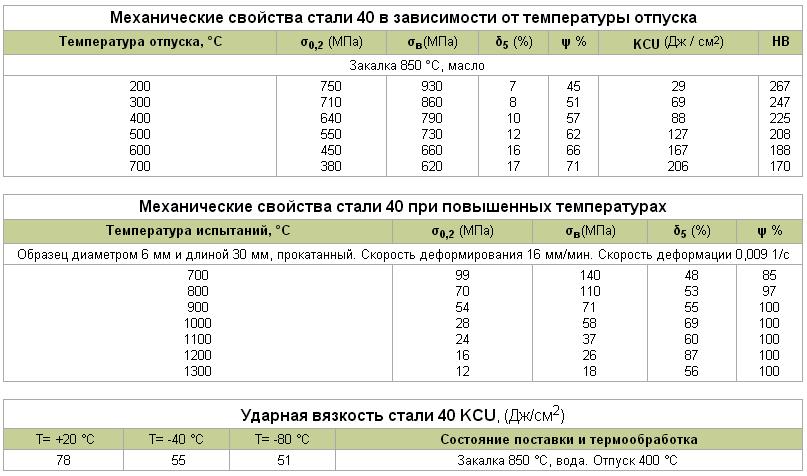 Сечения до 100 мм охлаждаются на воздухе, сечения 101-300 мм – в яме. Сечения до 100 мм охлаждаются на воздухе, сечения 101-300 мм – в яме. |
| Свариваемость | Ограниченно свариваемая. Способы сварки: ручная дуговая сварка, автоматическая дуговая сварка, контактная сварка. |
| Обрабатываемость резанием | В горячекатанном состоянии при HB 183-187 и σв = 590 МПа: Kv твердый сплав = 1,25 Kv быстрорежущая сталь = 0,95 |
| Флокеночувствительность | Чувствительна |
| Склонность к отпускной хрупкости | Склонна |
| Физические свойства | Температура испытаний, °С | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 20 | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | |
| 200 | – | – | – | – | – | – | – | – | – | |
| Модуль упругости при сдвиге кручением G, ГПа | – | – | – | – | – | – | – | – | – | – |
| Плотность ρn, кг/м3 | 7850 | 7830 | 7800 | 7760 | 7720 | 7680 | 7640 | – | – | – |
| Коэффициент теплопроводности λ, Вт/(м*К) | – | 31 | – | – | 26 | – | – | – | – | – |
| Удельное электросопротивление ρ, нОм*м | – | – | – | – | – | – | – | – | – | – |
| 20-100 | 20-200 | 20-300 | 20-400 | 20-500 | 20-600 | 20-700 | 20-800 | 20-900 | 20-1000 | |
| Коэффициент линейного расширения α*106, K-1 | 11,8 | 13,0 | 14,0 | 14,7 | 15,3 | 15,6 | – | – | – | – |
| Удельная теплоемкость c, Дж/(кг*К) | – | – | – | 528 | 540 | 565 | – | – | – | – |
характеристики и расшифовка, применение и свойства стали
- Стали
- Стандарты
Всего сталей
| Страна | Стандарт | Описание | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Россия | ГОСТ 4543-2016 | Металлопродукция из конструкционной легированной стали. Технические условия | ||||||||||
| Россия | ТУ 14-1-950-86 | Прутки и полосы из конструкционной легированной высококачественной стали размером до 200 мм включительно | ||||||||||
 js_elem_319694″>
js_elem_319694″>Химический состав 12ХН3А
Массовая доля элементов стали 12ХН3А по ГОСТ 4543-2016
| C (Углерод) | Si (Кремний) | (Марганец) | P (Фосфор) | S (Сера) | Cr (Хром) | Mo (Молибден) | Ni (Никель) | V (Ванадий) | Ti (Титан) | Cu | N (Азот) | W (Вольфрам) | Fe (Железо) |
| 0,09 – 0,16 | 0,17 – 0,37 | 0,3 – 0,6 | 0,6 – 0,9 | 2,75 – 3,15 | остальное |
Химический состав может быть изменён по договорённости с поставщиком: содержание кальция не должно превышать 0,003, также, как и содержание алюминия для цементируемых сталей не должно быть ниже 0,02.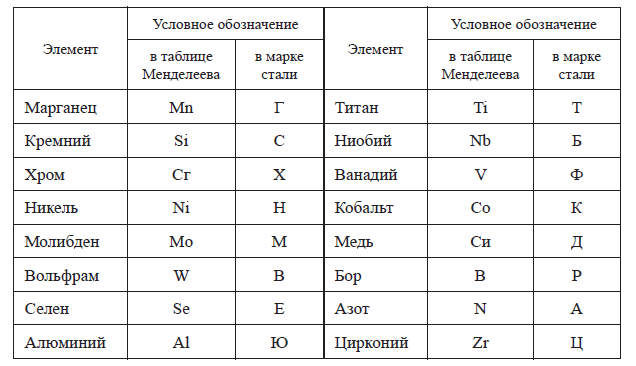 Эм = 0,3Cr + 0,5Ni + 0,7Cu.
Эм = 0,3Cr + 0,5Ni + 0,7Cu.
Массовая доля элементов стали 12ХН3А по ТУ 14-1-950-86
| C (Углерод) | Si (Кремний) | Mn (Марганец) | P (Фосфор) | S (Сера) | Cr (Хром) | Mo (Молибден) | Ni (Никель) | V (Ванадий) | Ti (Титан) | Cu (Медь) | W (Вольфрам) | Fe (Железо) |
| 0,10 – 0,16 | 0,17 – 0,37 | 0,3 – 0,6 | 0,6 – 0,9 | 2,75 – 3,18 | остальное |
Механические свойства стали 12ХН3А
Свойства по стандарту ГОСТ 4543-2016
| Предел текучести, σ0,2, МПа | Временное сопротивление разрыву, σв, МПа | Относительное удлинение при разрыве, δ5, % | Относительное сужение, ψ, % | Ударная вязкость, KCU при 20°С, Дж/см2 |
| > 685 | > 930 | > 11 | > 55 | > 88 |
| Твердость, HB | ||||
| Нагартованное состояние | ||||
|
Диаметр/Толщина >5 мм |
||||
| < 269 | ||||
Свойства по стандарту ТУ 14-1-950-86
| Предел текучести, σ0,2, МПа | Временное сопротивление разрыву, σв, МПа | Относительное удлинение при разрыве, δ5, % | Относительное сужение, ψ, % | Ударная вязкость, KCU при 20°С, Дж/см2 | |
| > 685 | > 930 | > 11 | > 55 | > 108 |
|
| Диаметр отпечатка, мм | |||||
| Термически обработанные образцы | Калиброванные или со специальной отделкой поверхности | ||||
| 3,2 – 3,7 | > 4 | ||||
×
Отмена Удалить
×
Выбрать тариф
×
Подтверждение удаления
Отмена Удалить
×
Выбор региона будет сброшен
Отмена
×
×
Оставить заявку
×
| Название | |||
Отмена
×
К сожалению, данная функция доступна только на платном тарифе
Выбрать тариф
Стратегии декодирования в моделях последовательности
В этой статье рассказывается о различных стратегиях декодирования, а также иллюстрируются распределения вероятностей посредством визуализации скрытых состояний с использованием пакета ecco для Python, что обеспечивает большую объяснимость генерации языковой модели.
О генерации языка
Архитектура кодер-декодер использует LSTM и RNN в качестве строительных блоков. Авторегрессионная модель основана на предположении, что вероятность следующего слова зависит от прошлых скрытых состояний.
Кодер кодирует исходную информацию и передает ее декодеру¹. В конце декодера вы передаете определенный токен в качестве входных данных, а полученные выходные данные передаются в следующую ячейку. Этот процесс повторяется до тех пор, пока вы не достигнете маркера (конца предложения)
Выходные данные на каждом временном шаге генерируют распределение вероятностей softmax словарных слов, а выходные данные контролируются на основе используемой стратегии декодирования.
Ecco
Ecco можно установить, просто используя
!pip install ecco
import ecco
lm = ecco.from_pretrained('gpt2',activations=True) Жадный поиск
Жадный поиск возвращает слово с максимальной вероятностью на каждом временном шаге
2 #возвращает выходные данные используя жадный подход. do_sample is False
do_sample is False greedy_output = lm.generate(‘Розы красные’, max_length=50, do_sample=False)
# возвращает распределение вероятностей на временном шаге greedy_output.layer_predictions(position=4, topk=10, layer=11)
Стратегия имеет некоторые недостатки:
- Модель не учитывает слова высокой вероятности, скрытые за словами низкой вероятности
- Похоже, что вывод модели повторяется, что является очень распространенной проблемой при жадном поиске²
Поиск луча
На каждом временном шаге вы проходите n количество путей, называемых лучами, генерирующими слова¹. Вероятность предложения берется для выбора слов, а не отдельных токенов.
На 1-м шаге вы выбираете верхние n слов в зависимости от ширины луча.
На 2-м шаге запустить n параллельных моделей декодеров с входными префиксами 3-х слов, из которых выбираются n лучших пар для 3-го шага.
На 3-м шаге выполните тот же шаг, что и выше, с n парами слов в качестве префикса, и продолжайте
давайте проверим, как это работает…
К сожалению, ecco пока не поддерживает поиск луча, поэтому пошли с обычными трансформаторами для просмотра вывода.
импортировать тензорный поток как tf
из трансформаторов импортировать TFGPT2LMHeadModel, GPT2Tokenizer
Tokenizer = gpt2tokenizer.from_pretraind ("gpt2")
# Добавить токен EOS в качестве токена PAD, чтобы избежать предупреждений
Model = tfgpt2lmheadmodel.from_pretrention ("gpt2", pad_tken_dizer = token_dizer. text = 'Розы красные'
input_ids = tokenizer.encode(text, return_tensors='tf')
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences= 5,
Early_stopping=True
)
print("Вывод:\n" + 100 * '-')
для i, beam_output in enumerate(beam_outputs):
print("{}: {}". format(i , tokenizer.decode(beam_output, skip_special_tokens=True)))
format(i , tokenizer.decode(beam_output, skip_special_tokens=True)))
Вывод:
———————————————————————————— ————-
0 : Розы красные, но не белые.
«Я не уверен, то ли это из-за цвета моей кожи, то ли я просто пытаюсь выглядеть получше», — сказал он. "Я не знаю.
1 : Розы красные, но не белые.
«Я не уверен, то ли это из-за цвета моей кожи, то ли я просто пытаюсь сделать так, чтобы она выглядела лучше», — сказал он. "Я не знаю.
2: Розы красные, но они не белые.
"Я не уверен, что это из-за цвета моей кожи, или я просто пытаюсь чтобы лучше рассмотреть, — сказал он. — Не знаю.
3: Розы красные, но не белые.
"Я не уверен, то ли это из-за цвета моей кожи, то ли я просто пытаюсь выглядеть получше", - сказал он. "Я не знаю,
4: Розы красные, но они не белые.
"Я не уверен, что это из-за цвета моей кожи, или я просто пытаюсь чтобы это выглядело лучше, — сказал он. — Я не знаю. у этого есть один недостаток. Генерация не работает для открытой генерации, так как выходные данные не имеют большой дисперсии⁴, поскольку люди не склонны всегда выбирать слова с наибольшей вероятностью. Как видно из рисунка ниже, нормальный язык может часто содержат маловероятностные слова
Стратегия по-прежнему работает в случаях, когда выходные данные тесно связаны с входными данными, а повторение и универсальность не вызывают таких проблем.
Выборка
Чтобы получить дисперсию в выходных данных, выборка также выполняется из словарных слов на основе вероятностного распределения. Это приведет к непоследовательности, так как будет выбрано много слов, которые не будут соответствовать тексту, который вы хотите создать.
вывод выборки, вывод вообще не имеет смысла
выборка с температурой
Это изменяет распределение softmax на основе температурного фактора, таким образом преувеличивая/уменьшая вероятность слова. Температура колеблется от 0–1, при t=1 от отсутствия эффекта до t=0, что эквивалентно жадному поиску. При уменьшении t распределение переходит от плоского к косому, что улучшает качество генерации.
Температура колеблется от 0–1, при t=1 от отсутствия эффекта до t=0, что эквивалентно жадному поиску. При уменьшении t распределение переходит от плоского к косому, что улучшает качество генерации.
матрица ранжирования с температурой
Очевидно, что эта модель начинает выборку более высокоранговых токенов, предоставляя температуру в качестве входных данных, в отличие от выборки, которая могла возвращать нишевые токены также и на выходе.
Выборка с верхним k
Выборка Top k фильтрует верхние k слов из выходного распределения поверх стратегии выборки, таким образом, модели получают возможность генерировать множество слов, в то же время контролируя тарабарщину
Распределение разнообразно, но обрезается в верхней части 20
Верхний вывод выборки k имеет больше смысла. Но есть и недостаток, поскольку окно контекста фиксировано для каждого токена, что приводит к тому, что маргинальные слова выбираются из сильно искаженного распределения. Кроме того, в случае более плоского распределения ценные слова будут потеряны.
Кроме того, в случае более плоского распределения ценные слова будут потеряны.
Выборка Top-p (nucleus)
Вместо выбора фиксированного числа слова также можно фильтровать по кумулятивной вероятности. Top-p выборка выбирает минимальное число слов, которое должно превысить вместе p вероятностной массы.
top-p принимает только слова с кумулятивной вероятностью чуть более 50% подходят для открытых языковых проблем, а там, где универсальность не является проблемой, лучше использовать лучевой поиск. Как правило, модели по-прежнему страдают от проблемы повторения граммов, которая решается с помощью repeat_penalty в модуле трансформатора.
Ссылка на мой блокнот: https://github.com/Nempickaxe/mini_projects/blob/master/Language_model_decoding_parameters.ipynb (PS: чтобы просмотреть некоторые функции ecco, вам нужно открыть блокнот в google colab)
[1] Интуитивное объяснение поиска луча, Рену Хандельвал,
https://towardsdatascience. com/an-intuitive-explanation-of-beam-search-9b1d744e7a0f
com/an-intuitive-explanation-of-beam-search-9b1d744e7a0f
[2] Патрик фон Платен, Huggingface,
https: //huggingface.co/blog/how-to-generate
[3] Nucleus Sampling: The Curious Case of Neural Text Degeneration (Прохождение исследовательской работы), TechViz — The Data Science Guy,
https://www.youtube.com/watch?v=dCORspO2yVY&ab_channel=TechViz-TheDataScienceGuy
[4] ЛЮБОПЫТНЫЙ СЛУЧАЙ ДЕГЕНЕРАЦИИ НЕЙРОННОГО ТЕКСТА, Ари Хольцман,
https://arxiv.org/pdf/1904.09751.pdf
Декодер NMX-DEC-N1233A | AMX Audio Video Control Systems
Новая модель NMX-DEC-N1233A отличается улучшенным цифровым воспроизведением пикселей и уменьшенной задержкой до лучших в отрасли 10 мс для гигабитных каналов. Пакетные видеопотоки не только остаются без визуальных потерь во время распространения, но и поступают мгновенно. Он имеет отдельные входы HDMI и VGA/RGB, поддерживает PoE, AES67 и имеет отдельный порт SFP. Оптоволоконный тракт SFP позволяет маршрутизировать видео без визуальных потерь в оптоволоконной сети и распространять сигналы за пределы досягаемости кабеля категории. Добавленное USB-подключение позволит пользователям расширять USB через IP для приложений с сенсорным экраном и KVM.
Оптоволоконный тракт SFP позволяет маршрутизировать видео без визуальных потерь в оптоволоконной сети и распространять сигналы за пределы досягаемости кабеля категории. Добавленное USB-подключение позволит пользователям расширять USB через IP для приложений с сенсорным экраном и KVM.
Кодировщики и декодеры серии N1000 — это доступное локальное решение для коммутации AV over IP, которое пакетирует видео в IP-формат с минимальным сжатием для создания любого устройства — от небольшого бесшовного презентационного коммутатора 2×1 до матричного коммутатора среднего размера путем их прямого подключения. к готовым сетевым коммутаторам.
| Версия | Язык | Размер | Загружено | |
Чертежи САПР | ||||
| Графический рисунок (PDF) — N1000, N2000, N3000 обновлено: 24 июля 2020 г. | 111 КБ | 24 июля 2020 г. | ||
| Графический чертеж (DWG) — N1000, N2000, N3000 обновлено: 24 июля 2020 г. | 161 КБ | 24 июля 2020 г. | ||
Объекты BIM | ||||
| NMX-DEC-N1233A — Объект BIM обновлено: 12 августа 2019 г. | 12 августа 2019 г. | |||
Программное обеспечение | ||||
| SVSI N-способный Mac версия 2021-12-13,
обновлено: 07 января 2022 г. | 2021-12-13 | 90,5 МБ | 07 января 2022 г. | |
| SVSI N-совместимый ПК версия 2022-12-29, обновлено: 09 января 2023 г. | 2022-12-29 | 9 января 2023 г. | ||
Прошивка | ||||
| Средство обновления прошивки кодировщика и декодера SVSI N1x33A версия 1.15.45, обновлено: 11 ноября 2021 г. | 1.15.45 | 42,9 МБ | 11 ноября 2021 г. | |
Руководства по продуктам | ||||
| Руководство по продукту — Руководство по совместимости N-Series Stream обновлено: 14 сентября 2022 г. | 380 КБ | 14 сентября 2022 г. | ||
| NET-SVSI-MIB.txt обновлено: 04 августа 2021 г. | 94,5 КБ | 04 августа 2021 г. | ||
Руководства по программированию | ||||
| Zoom Room Controls — пример конфигурации декодера SVSI версия 0.1.5, обновлено: 9 сентября 2021 г. | 0.1.5 | 132 КБ | 9 сентября 2021 г. | |

Если какая-либо из приведенных выше ссылок приводит к появлению странных символов в вашем браузере, щелкните файл правой кнопкой мыши.