Трансформатор трдн: Расшифровка наименований масляных трансформаторов
alexxlab | 31.07.2023 | 0 | Разное
Силовые трансформаторы, КТП и кабельная продукция
Перевести страницу
Поиск по каталогу
Каталог оборудования / Силовые трансформаторы, КТП и кабельная продукция
Оформить заказТРДН – трансформатор силовой трехфазный двухобмоточный масляный с расщепленными обмотками НН, с принудительной циркуляцией воздуха и естественной циркуляцией масла, с регулированием напряжения под нагрузкой (РПН).
Данный трансформатор устанавливается на открытом воздухе и применяется для работы в электрических сетях общего назначения.
Конструкция трансформатора предусматривает наличие радиаторов и вентиляторов, приборов контроля и защиты (стрелочных маслоуказателей, трансформаторов тока, датчика контроля температуры масла, газового и струйного реле, предохранительного клапана), воздухоосушителей, термосифонного фильтра для удаления влаги из масла.
У1 – климатическое исполнение и категория размещения по ГОСТ 15150 (от + 40°С до – 45°С).
Окружающая среда не должна быть химически активной, взрывоопасной; не должна содержать высокую концентрацию пыли, не должно быть тряски, вибрации и ударов. Высота установки – не более 1000 м над уровнем моря.
| Трансформаторы сухие трехфазные с воздушно-барьерной и литой изоляцией 6(10) кВ (Y/Y-0,12 гр., Δ/Y-11 гр.) | |
ТСЗ,ТСЛ-25/6(10)/0,4 | ТСЗ,ТСЛ-400/6(10)/0,4 |
ТСЗ,ТСЛ-40/6(10)/0,4 | ТСЗ,ТСЛ-630/6(10)/0,4 |
ТСЗ,ТСЛ-63/6(10)/0,4 | ТСЗ,ТСЛ-1000/6(10)/0,4 |
ТСЗ,ТСЛ-100/6(10)/0,4 | ТСЗ,ТСЛ-1250/6(10)/0,4 |
ТСЗ,ТСЛ-160/6(10)/0,4 | ТСЗ,ТСЛ-1600/6(10)/0,4 |
ТСЗ,ТСЛ-250/6(10)/0,4 | ТСЗ,ТСЛ-2500/6(10)/0,4 |
Трансформаторы сухие трехфазные преобразовательные с воздушно-барьерной изоляцией 6(10) кВ (Y/Y-0,12 гр. , Δ/Y-11 гр.) , Δ/Y-11 гр.) | |
ТСЗП-100/6(10)/0,4 | ТСЗП-630/6(10)/0,4 |
ТСЗП-160/6(10)/0,4 | ТСЗП-1000/6(10)/0,4 |
ТСЗП-250/6(10)/0,4 | ТСЗП-1250/6(10)/0,4 |
ТСЗП-400/6(10)/0,4 | ТСЗП-1600/6(10)/0,4 |
| Трансформаторы трехфазные масляные напряжением 6(10) кВ (Y/Y-0,12 гр., Δ/Y-11 гр.) | |
ТМ, ТМГ-25/6(10)/0,4 | ТМ, ТМГ-400/6(10)/0,4 |
ТМ, ТМГ-40/6(10)/0,4 | ТМ, ТМГ-630/6(10)/0,4 |
ТМ, ТМГ-1000/6(10)/0,4 | |
ТМ, ТМГ-100/6(10)/0,4 | ТМ, ТМ-1250/6(10)/0,4 |
ТМ, ТМГ-160/6(10)/0,4 | ТМ, ТМГ-1600/6(10)/0,4 |
ТМ, ТМГ-250/6(10)/0,4 | ТМ, ТМГ-2500/6(10)/0,4 |
| Трансформаторы трехфазные масляные напряжением 6(10) кВ (Y/Z, Δ/Z) | |
ТМ, ТМГ-25/6(10)/0,4 | ТМ, ТМГ-400/6(10)/0,4 |
ТМ, ТМГ-40/6(10)/0,4 | ТМ, ТМГ-630/6(10)/0,4 |
ТМ, ТМГ-63/6(10)/0,4 | ТМ, ТМГ-1000/6(10)/0,4 |
ТМ, ТМГ-100/6(10)/0,4 | ТМ, ТМГ-1250/6(10)/0,4 |
ТМ, ТМГ-160/6(10)/0,4 | ТМ, ТМГ-1600/6(10)/0,4 |
ТМ, ТМГ-250/6(10)/0,4 | ТМ, ТМГ-2500/6(10)/0,4 |
Трансформаторы трехфазные масляные с боковым вводом (Y/Y-0,12 гр. , Δ /Y-11 гр.) , Δ /Y-11 гр.) | |
ТМЗ, ТМФ, ТМГФ-250/6(10)/0,4 | ТМЗ, ТМФ, ТМГФ-1250/6(10)/0,4 |
ТМЗ, ТМФ, ТМГФ-400/6-10 | ТМЗ, ТМФ, ТМГФ-1600/6(10)/0,4 |
ТМЗ, ТМФ, ТМГФ-630/6-10 | ТМЗ, ТМФ, ТМГФ-2500/6(10)/0,4 |
ТМЗ, ТМФ, ТМГФ-1000/6-10 | |
| Трансформаторы трехфазные масляные с регулированием напряжения без возбуждения (ПБВ) 35 кВ | |
ТМ-100/35/6,10 | ТМ-1000/35/6,10 |
ТМ-160/35/6,10 | ТМ-1600/35/6,10 |
ТМ-250/35/6,10 | ТМ-2500/35/6,10 |
ТМ-400/35/6,10 | ТМ-4000/35/6,10 |
ТМ-630/35/6,10 | ТМ-6300/35/6,10 |
| Трансформаторы трехфазные масляные с регулированием напряжения под нагрузкой (РПН) напряжением 35 кВ | |
ТМН-1000/35/6,10 | ТДН-10000/35/6,10 |
ТМН-1600/35/6,10 | ТДН-16000/35/6,10 |
ТМН-2500/35/6,10 | ТДН-25000/35/6,10 |
ТМН-4000/35/6,10 | ТДНС-10000/35/6,10 |
ТМН-6300/35/6,10 | ТДНС-16000/35/6,10 |
| Трансформаторы трехфазные масляные, класса напряжения 110 кВ | |
ТДЦ-180000/110 | ТД-80000/110 |
ТДЦ-160000/110 | ТД-63000/110 |
ТДЦ-125000/110 | ТДЦ-21000/110 |
ТДЦ-100000/110 | ТДН-10000/110 |
ТРДН-40000/110 | ТДН-16000/110 |
ТРДН-63000/110 | ТДН-25000/110 |
ТРДЦН-63000/110 | ТРДН-25000/110 |
ТРДН-80000/110 | ТРДН-32000/110* |
ТРДЦН-80000/110 | ТДН-40000/110 |
| Трансформаторы трехфазные масляные, двух- и трехобмоточные класса напряжения 220 кВ | |
ТДЦТН-100000/220 | ТРДЦН-80000/220 |
ТДЦТН-125000/220 | ТРДЦН-100000/220 |
ТРДНМ-63000/100000/220 | ТРДНС-25000/220 |
ТДЦНМ-100000/200000/220 | ТРДН-32000/220 |
ТДЦНМ-160000/250000/220 | ТРДНС-40000/220 |
ТРДЦН-63000/220 | ТРДН-63000/220 |
| Трансформаторы трехфазные масляные класса напряжения 330 кВ | |
ТДЦ-250000/330 | ТРДНС-63000/330 |
ТДЦ-150000/330 | ТРДЦН-63000/330 |
ТДЦ-100000/330 | ТРДЦН-80000/330 |
ТРДНС-40000/330 | ТРДЦН-100000/330 |
Трансформаторы силовые масляные класса напряжения 220 кВ
Трансформаторы стационарные силовые масляные трехфазные двухобмоточные общего назначения
| Тип изделия, обозначение нормативного документа | Номинальное напряжение, кВ | Схема и группа соединения обмоток | Потери, кВт | Масса, кг полная | ||
| ВН | НН | холостого хода | короткого замыкания | |||
| ТД-25000/220-У1, УХЛ1 СТО 15352615-024-2012 | 230 | 6,30; 11,00 | YH/D-11 | 25,0 | 130,0 | *** |
| ТД-40000/220-У1,УХЛ1 СТО 15352615-024-2012 | 230 | 6,30; 11,00 | YH/D-11 | 40,0 | 170,0 | *** |
| ТДЦ-80000/220- У1, ХЛ1 СТО 15352615-024-2012 | 242 | 6,30; 10,50; 13,80 | YH/D-11 | 60,0 | 280,0 | *** |
| ТДЦ-125000/220-У1, УХЛ1 СТО 15352615-024-2012 | 242 | 10,50; 13,80 | YH/D-11 | 90,0 | 380,0 | 157400 |
| ТДЦ-80000/220- У1, ХЛ1 СТО 15352615-024-2012 | 242 | 13,80; 15,75; 18,00 | YH/D-11 | 90,0 | 580,0 | *** |
| ТДЦ-225000/220-У1, УХЛ1 СТО 15352615-024-2012 | 225 | 15,75 | YH/D-11 | 110,0 | 530,0 | 215000 |
| Тип изделия, обозначение нормативного документа | Номинальное напряжение, кВ | Схема и группа соединения обмоток | Потери, кВт | Масса, кг полная | ||
| ВН | НН | холостого хода | короткого замыкания | |||
| ТДЦ-125000/220-У1, УХЛ1 СТО 15352615-024-2012 | 242 | 10,50; 11,00; 11,50; 13,80 | Yн/D- 11 | 90 | 380 | 157400 |
| ТДЦ-250000/220-У1, УХЛ1 СТО 15352615-024-2012 | 242 | 13,80; 15,75 | Yн/D- 11 | 150 | 600 | 242000 |
| ТДЦ-400000/220-У1, УХЛ1 СТО 15352615-024-2012 | 242 | 15,75; 20,00 | Yн/D- 11 | 200 | 850 | *** |
| Тип изделия, обозначение нормативного документа | Номинальное напряжение, кВ | Схема и группа соединения обмоток | Потери, кВт | Масса, кг полная | ||
| ВН | НН | холостого хода | короткого замыкания | |||
| ТДН-25000/220-У1, УХЛ1 СТО 15352615-024-2012 | 230 | 6,6; 11,0; 38,5 | YH/D-11 | 22 | 120 | 82500 |
| ТРДН-25000/220-У1, УХЛ1 СТО 15352615-024-2012 | 230 | 6,6-6,6; 11,0-11,0 | YH/D-D-11-11 | 22 | 120 | 82500 |
| ТРДН- 40000/220- У1, УХЛ1 СТО 15352615-024-2012 | 230 | 6,3-6,3; 6,6-6,6; 11,0-11,0; 11,0-6,6 | YH/D-D-11-11 | 50 | 170 | 99000 |
| ТРДНС- 40000/220- У1, УХЛ1 СТО 15352615-024-2012 | 230 | 6,3-6,3; 6,6-6,6; 11,0-11,0; 11,0-6,6 | YH/D-D-11-11 | 50 | 170 | 99000 |
| ТДН- 63000/220- У1, УХЛ1 СТО 15352615-024-2012 | 242 | 10,5 | YH/D-11 | 45 | 265 | 120000 |
| ТРДНС- 63000/220- У1, УХЛ1 СТО 15352615-024-2012 | 230 | 6,3-6,3; 6,6-6,6; 11,0-11,0; 11,0-6,6 | YH/D-D-11-11 | 45 | 265 | 120000 |
| ТРДН-63000/220-У1, УХЛ1 СТО 15352615-024-2012 | 230 | 6,3-6,3; 6,6-6,6; 11,0-11,0; 11,0-6,6 | YH/D-D-11-11 | 45 | 265 | 120000 |
| ТРДЦН- 63000/220- У1, УХЛ1 СТО 15352615-024-2012 | 230 | 6,3-6,3; 6,6-6,6; 11,0-11,0; 11,0-6,6 | YH/D-D-11-11 | 45 | 265 | *** |
| ТРДЦН-100000/220-У1, УХЛ1* СТО 15352615-024-2012 | 230 | 11,0-11,0 | YH/D-D-11-11 | 102 | 340 | *** |
| ТРДЦН-160000/220-У1, УХЛ1 СТО 15352615-024-2012 | 230 | 11,0-11,0 | YH/D-D-11-11 | 155 | 500 | *** |
| ТРДЦН-200000/220-У1, УХЛ1 СТО 15352615-024-2012 | 230 | 11,0-11,0 | YH/D-D-11-11 | 100 | 630 | *** |
Трансформаторы стационарные силовые масляные трехфазные трехобмоточные общего назначения
| Тип изделия, обозначение нормативного документа | Номинальное напряжение, кВ | Схема и группа соединения обмоток | Потери, кВт | Масса, кг полная | |||
| ВН | CН | НН | холостого хода | короткого замыкания | |||
| ТДТН-25000/220-У1, УХЛ1 СТО 15352615-024-2012 | 230 | 27,5; 38,5 | 6,6; 10,5; 11,0; 27,5 | Yн/Yн/D-0-11 | 30 | 130 | 94000 |
| ТДТН-40000/220-У1* СТО 15352615-024-2012 | 230 | 38,5 | 6,6; 11,0 | YH / YH /D-0-11 | 54 | 220 | *** |
| ТДТН-63000/220-У1; УХЛ1 СТО 15352615-024-2012 | 230 | 38,5 | 6,6; 11,0 | Yн/Yн/D-0-11 | 60 | 270 | 155000 |
* Трансформаторы подлежат разработке и постановке на производство по заказам потребителей в установленном порядке.![]()
*** В соответствии с конструкторской документацией по результатам приемочных испытаний
Прогнозы акций с помощью Transformer и Time Embeddings. 6, 2020
Фото Morning Brew на Unsplash В моем предыдущем посте я поделился своими первыми результатами исследования по прогнозированию цен на акции, которые впоследствии будут использоваться в качестве входных данных для торгового бота с глубоким обучением. При масштабировании моих наборов данных до тысяч тикеров акций, что соответствует почти 1 терабайт историй цен на акции и новостных статей , я понял, что мой первоначальный подход к работе с нейронными сетями состоял из LSTM ( L ong- S hort T erm M 9001 6 emory Models) и CNN ( C onvolutional N eural N network) имеет свои ограничения. Таким образом, для преодоления ограничений мне пришлось реализовать Трансформатор , , специализированный на запас временной ряд .
В последние годы Трансформеры завоевали популярность благодаря своим выдающимся характеристикам. Объединение механизма самоконтроля , распараллеливания и позиционного кодирования под одним капотом обычно дает преимущество над классическими моделями LSTM и CNN при работе над задачами, где требуется извлечение семантических признаков и большие наборы данных [1].
Поскольку мне не удалось найти простую реализацию Transformer, адаптированную для последовательностей временных рядов, имеющих несколько функций, например. (Открытие, Максимум, Минимум, Закрытие, Объем) функций наших биржевых данных, которые мне пришлось реализовывать самостоятельно. В этом посте я расскажу о своей архитектуре Transformer для биржевых данных, а также о том, что такое Time Embeddings и почему важно использовать их в сочетании с временными рядами.
В целях пояснения этой статьи мы будем использовать историю цен на акции IBM как упрощенную версию набора данных по акциям объемом 1 терабайт.![]() Тем не менее, вы можете легко применить код в этой статье к значительно большему набору данных. Набор данных IBM начинается с 1962–01–02, заканчивается датой 2020–05–24 и содержит всего 14699 торговых дней . Кроме того, для каждого тренировочного дня у нас есть цена Open , High , Low, и Close , а также торговый объем (OHLCV) акций IBM.
Тем не менее, вы можете легко применить код в этой статье к значительно большему набору данных. Набор данных IBM начинается с 1962–01–02, заканчивается датой 2020–05–24 и содержит всего 14699 торговых дней . Кроме того, для каждого тренировочного дня у нас есть цена Open , High , Low, и Close , а также торговый объем (OHLCV) акций IBM.
Подготовка данных
Характеристики цены и объема преобразуются в ежедневные доходности акций и ежедневные изменения объема , применяется мин-макс, нормализованное , и временной ряд разбивается на обучающий, проверочный и тестовый наборы. Преобразование цен акций и объемов в ежедневные темпы изменения увеличивает стационарность нашего набора данных. Таким образом, выводы, полученные моделью из нашего набора данных, имеют более высокую достоверность для будущих прогнозов. Вот обзор того, как выглядят преобразованные данные.
Вот обзор того, как выглядят преобразованные данные.
Наконец, наборы для обучения, проверки и тестирования разделены на отдельные последовательности продолжительностью 128 дней каждая. Для каждого дня последовательности присутствуют 4 ценовые функции (открытие, максимум, минимум, закрытие) и функция объема, что дает 5 функций в день. За один шаг обучения наша модель Transformer получит 32 последовательности (batch_size = 32) длиной 128 дней (seq_len=128) и 5 функций в день в качестве входных данных.
Размер входной матрицы моделиВ качестве первого шага нашей реализации Transformer мы должны рассмотреть, как закодировать понятие времени, которое скрыто в наших ценах на акции, в нашу модель.
При обработке данных временных рядов время является важной характеристикой. Однако при обработке временных рядов/последовательных данных с помощью Transformer все последовательности передаются одновременно через архитектуру Transformer, что затрудняет извлечение временных/последовательных зависимостей. Таким образом, Transformers, которые используются в сочетании с данными на естественном языке, имеют тенденцию к используют позиционное кодирование для предоставления модели понятия порядка слов . В деталях, позиционное кодирование — это представление значения слова и его положения в предложении, позволяющее Преобразователю получить знания о структуре предложения и взаимозависимости слов. Пример позиционного кодирования можно найти, заглянув под капот модели BERT [2] , в которой достигнута современная производительность для многих языковых задач.
Таким образом, Transformers, которые используются в сочетании с данными на естественном языке, имеют тенденцию к используют позиционное кодирование для предоставления модели понятия порядка слов . В деталях, позиционное кодирование — это представление значения слова и его положения в предложении, позволяющее Преобразователю получить знания о структуре предложения и взаимозависимости слов. Пример позиционного кодирования можно найти, заглянув под капот модели BERT [2] , в которой достигнута современная производительность для многих языковых задач.
Точно так же Преобразователь требует понятия времени при обработке наших цен на акции. Без временных вложений наш Преобразователь не получил бы никакой информации о временном порядке цен наших акций. Следовательно, цена акции с 2020 года может иметь то же влияние на прогноз завтрашней цены , что и цена с 1990 года. И это, конечно, было бы нелепо.
И это, конечно, было бы нелепо.
Time2Vector
Для преодоления временных безразличий Трансформера мы реализуем подход, описанный в статье Time2Vec: изучение векторного представления времени [2] . Авторы статьи предлагают « независимое от модели векторное представление времени, называемое Time2Vec » . Вы можете думать о векторном представлении так же, как о обычном слое внедрения , который можно добавить в архитектуру нейронной сети для повышения производительности модели.
Если свести статью к сути, то есть две основные идеи рассмотреть. Во-первых, авторы определили, что осмысленное представление времени должно включать как периодических, так и непериодических моделей . Примером периодической модели является погода, которая меняется в разные сезоны. Напротив, примером непериодического паттерна может быть заболевание, которое возникает с большей вероятностью, чем старше пациент.
Во-вторых , представление времени должно иметь инвариантность к изменению масштаба времени, означает, что на представление времени не влияют различные приращения времени, например. (дни, часы или секунды) и длительные временные горизонты.
Объединяя идеи периодических и непериодических паттернов, а также инвариантность к изменению масштаба времени, мы получаем следующее математическое определение. Не беспокойтесь, это проще, чем кажется, и я объясню это подробно. 😉
Математическое представление вектора времени — Time2Vec: Изучение векторного представления времени [3] Вектор/представление времени t2v состоит из двух компонентов, где ωᵢτ + φᵢ представляет непериодический/линейный, а 90 121 F(ωᵢτ + φᵢ) периодическая характеристика вектора времени .
Переписав t2v(τ) = ωᵢτ + φᵢ более простым способом, новая версия y = mᵢx + bᵢ 900 16 должен выглядеть знакомо, так как это ванильная версия линейная функция, которую вы знаете из средней школы.
ω in ωᵢτ + φᵢ — матрица, определяющая наклон нашего временного ряда τ и φ простыми словами матрица, которая определяет, где наш временной ряд τ пересекается с осью Y. Следовательно, ωᵢτ + φᵢ есть не что иное, как линейная функция.
Второй компонент F(ωᵢτ + φᵢ) представляет периодический признак временного вектора. Как и раньше, у нас снова есть линейный член ωᵢτ + φᵢ , однако на этот раз линейная функция заключена в дополнительную функцию F() . Авторы экспериментировали с различными функциями, чтобы лучше всего описать периодическую зависимость (сигмовидная, тангенциальная, ReLU, мод, треугольник и т. д.). В итоге 9Синусоидальная функция 0015 показала наилучшие и наиболее стабильные результаты (косинус дал аналогичные результаты). При объединении линейной функции
д.). В итоге 9Синусоидальная функция 0015 показала наилучшие и наиболее стабильные результаты (косинус дал аналогичные результаты). При объединении линейной функции ωᵢτ + φᵢ с синусоидальной функцией двумерное представление выглядит следующим образом. φ смещает синусоидальную функцию по оси x и ω определяет длину волны синусоидальной функции.
Давайте посмотрим, как изменяется точность сети LSTM в сочетании с различными нелинейными функциями вектора времени (Time2vec). Мы можем ясно видеть, что функция ReLU выполняет худшее , в отличие от синусоидальной функции , которая превосходит любую другую нелинейную функцию. Причина, по которой функция ReLU дает такие неудовлетворительные результаты, заключается в том, что функция ReLU не инвариантна к изменению масштаба времени. Чем выше инвариант функции к изменению масштаба времени, тем выше производительность.
Чем выше инвариант функции к изменению масштаба времени, тем выше производительность.
Повышение производительности Time2Vector
Прежде чем мы начнем внедрять встраивание времени, давайте посмотрим на разницу в производительности обычной сети LSTM (синяя) и Сеть LSTM+Time2Vec (красный). Как видите, предлагаемый вектор времени для нескольких наборов данных никогда не приводит к ухудшению производительности и почти всегда повышает производительность модели. Вооружившись этими знаниями, мы переходим к реализации.
Сравнение производительности сети LSTM с вектором времени и без него — Time2Vec: Изучение векторного представления времени [3]Реализация Time2Vector Keras
Хорошо, мы обсудили, как периодические и непериодические компоненты нашего вектора времени работают в теории, теперь мы реализуем их в коде. Чтобы вектор времени можно было легко интегрировать в любую архитектуру нейронной сети, мы определим вектор как слой Keras. Наш пользовательский слой Time2Vector имеет две подфункции
Наш пользовательский слой Time2Vector имеет две подфункции def build(): и def call(): . В def build(): мы инициируем 4 матрицы, 2 для ω и 2 для φ так как нам нужен ω и φ матрица как для непериодических (линейных), так и для периодических (синусоидальных) признаков.
seq_len = 128def build(input_shape):
weights_linear = add_weight(shape=(seq_len), trainable=True)
bias_linear = add_weight(shape=(seq_len), trainable=True) weights_periodic = add_weight(shape=(seq_len), trainable=True)
bias_periodic = add_weight(shape =(seq_len), trainable=True)
После запуска наших 4 матриц мы определяем шаги расчета, которые будут выполняться после вызова слоя, следовательно, функция def call(): .
Ввод, который будет получен слоем Time2Vector, имеет следующую форму (batch_size, seq_len, 5) → (32, 128, 5) . Параметр batch_size определяет, сколько последовательностей цен акций мы хотим передать в модель/уровень одновременно. Параметр seq_len определяет длину одной последовательности цен акций. Наконец, число 5 получено из того факта, что у нас есть 5 характеристик ежедневной записи акций IBM (цена открытия, высокая цена, низкая цена, цена закрытия, объем).
Первый шаг вычисления исключает объем и берет среднее значение по ценам открытия, максимума, минимума и закрытия, в результате получается форма (размер_пакета, длина_последовательности) .
x = tf.math.reduce_mean(x[:,:,:4], axis=-1)
Затем мы вычисляем непериодическую (линейную) характеристику времени и снова увеличиваем измерение на 1. (batch_size, seq_len, 1)
time_linear = weights_linear * x +bias_lineartime_linear = tf.expand_dims(time_linear, axis=-1)
Тот же процесс повторяется для периодического временного признака, что также приводит к той же форме матрицы . (размер_пакета, длина_последовательности, 1)
time_periodic = tf.math.sin(tf.multiply(x, weights_periodic) +bias_periodic)time_periodic = tf.expand_dims(time_periodic, axis=-1)
Последний шаг, который необходим для завершения расчета вектора времени, это конкатенация линейная и периодическая функция времени. (batch_size, seq_len, 2)
time_vector = tf.concat([time_linear, time_periodic], axis=-1)
Time2Vector layer
Объединив все шаги в одну функцию слоя, код выглядит следующим образом.
Теперь мы знаем, что важно дать представление о времени и как реализовать вектор времени, следующим шагом будет Преобразователь. Преобразователь представляет собой архитектуру нейронной сети, которая использует механизм самоконтроля , позволяя модели сосредоточиться на соответствующих частях временного ряда для улучшения качества предсказания. Механизм самоконтроля состоит из слоев Single-Head Attention и Multi-Head Attention . внимание к себе механизм способен соединить все шаги временного ряда друг с другом одновременно, что приводит к созданию долгосрочных взаимопониманий зависимостей. Наконец, все эти процессы распараллелены в архитектуре Transformer, что позволяет ускорить процесс обучения.
Механизм самоконтроля состоит из слоев Single-Head Attention и Multi-Head Attention . внимание к себе механизм способен соединить все шаги временного ряда друг с другом одновременно, что приводит к созданию долгосрочных взаимопониманий зависимостей. Наконец, все эти процессы распараллелены в архитектуре Transformer, что позволяет ускорить процесс обучения.
Объединение функций данных и времени IBM — питание преобразователя
После внедрения временных вложений мы будем использовать вектор времени в сочетании с ценовыми и объемными характеристиками IBM в качестве входных данных для нашего преобразователя. Слой Time2Vector получает характеристики IBM цена и объем в качестве входных данных и вычисляет непериодические и периодические временные характеристики . На следующем шаге модели рассчитанные временные характеристики объединяются с ценовыми и объемными характеристиками, образуя матрицу формы
На следующем шаге модели рассчитанные временные характеристики объединяются с ценовыми и объемными характеристиками, образуя матрицу формы (32, 128, 7) .
Одноголовое внимание
Временные ряды IBM плюс характеристики времени , которые мы только что вычислили, образуют исходный ввод для первого уровня внимания с одной головкой. Слой внимания с одной головкой принимает 3 входа (запрос, ключ, значение), всего . Для нас каждый входной запрос, ключ и значение представляют характеристики цены, объема и времени IBM. Каждый ввод Query, Key и Value получает отдельное линейное преобразование , проходя через отдельные плотные слои. Обеспечение плотных слоев с 96 выходных ячеек были личным архитектурным выбором.
Одноголовое внимание — Линейные преобразования входных данных запроса, ключа и значения После начального линейного преобразования мы рассчитаем оценку/веса внимания.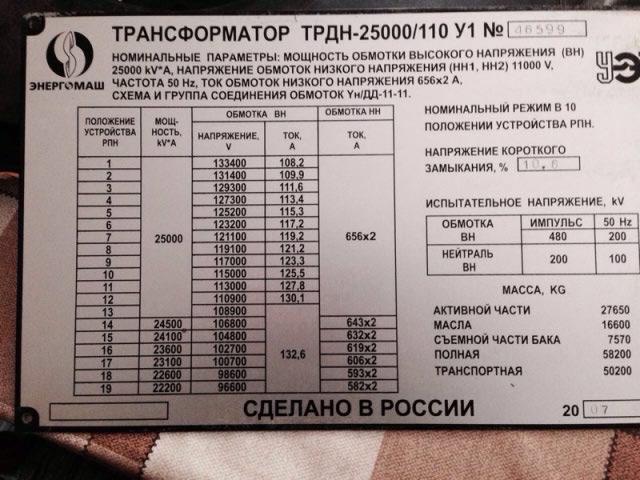 Веса внимания определяют , насколько большое внимание уделяется отдельным шагам временного ряда при прогнозировании будущей цены акции. Веса внимания рассчитываются путем взятия скалярного произведения линейно преобразованных входных данных Запроса и Ключа, тогда как преобразованный входной Ключ был транспонирован, чтобы сделать возможным умножение скалярного произведения. Затем 9Скалярное произведение 0015 делится на на размерность предыдущих плотных слоев (96), чтобы избежать взрыва градиентов. Разделенное скалярное произведение затем проходит через функцию softmax , чтобы получить набор из весов, которые в сумме составляют 1 . В качестве последнего шага вычисленная матрица softmax, которая определяет фокус каждого временного шага, умножается на преобразованную матрицу v , которая завершает механизм внимания с одной головкой.
Веса внимания определяют , насколько большое внимание уделяется отдельным шагам временного ряда при прогнозировании будущей цены акции. Веса внимания рассчитываются путем взятия скалярного произведения линейно преобразованных входных данных Запроса и Ключа, тогда как преобразованный входной Ключ был транспонирован, чтобы сделать возможным умножение скалярного произведения. Затем 9Скалярное произведение 0015 делится на на размерность предыдущих плотных слоев (96), чтобы избежать взрыва градиентов. Разделенное скалярное произведение затем проходит через функцию softmax , чтобы получить набор из весов, которые в сумме составляют 1 . В качестве последнего шага вычисленная матрица softmax, которая определяет фокус каждого временного шага, умножается на преобразованную матрицу v , которая завершает механизм внимания с одной головкой.
Так как иллюстрации отлично подходят для первых начальных занятий, но им не хватает аспекта реализации, я подготовил для вас чистую функцию слоя SingleAttention Keras 🙂.
Мультиголовное внимание
Для дальнейшего совершенствования механизма самоконтроля авторы статьи Attention Is All You Need [4] предложили реализовать мультиголовное внимание. Функциональность слоя внимания с несколькими головками состоит в том, чтобы c объединить веса внимания из n слои внимания с одной головкой , а затем применить нелинейное преобразование с плотным слоем. На приведенном ниже рисунке показано объединение трех слоев с одной головкой.
Наличие выходных данных n слоев с одной головкой позволяет кодировать преобразование нескольких независимых слоев с одной головкой в модель. Следовательно, модель может сосредоточиться на нескольких шагах временного ряда одновременно. Увеличение количества головок внимания положительно влияет на способность модели фиксировать удаленные зависимости. [1]
[1]
То же, что и выше, чистая реализация уровня внимания с несколькими головками.
Уровень преобразователя кодирования
Механизмы внимания с одной и несколькими головками (самовнимание) теперь объединены в уровень преобразователя кодирования. Каждый уровень кодера включает в себя подуровень самоконтроля и подуровень прямой связи. Подуровень прямой связи состоит из двух плотных слоев с активацией ReLU между ними.
Кстати, плотные слои можно заменить одномерными сверточными слоями, если свёрточные слои имеют размер ядра и шаг, равный 1. Математика плотного слоя и свёрточного слоя с описанной конфигурацией одинакова. .
За каждым подслоем следует отсеваемый слой, после отсева остаточное соединение формируется путем добавления начального ввода Query к обоим выходам подуровня. Завершение каждого подслоя слоем нормализации, размещенным после добавления остаточной связи, для стабилизации и ускорения процесса обучения.
Теперь у нас есть готовый к использованию слой Transformer, который можно легко комбинировать для повышения производительности модели. Поскольку нам не нужны какие-либо слои декодера Transformer, наша реализованная архитектура Transformer очень похожа на архитектуру BERT [2]. Хотя различия заключаются во временных вложениях, и наш преобразователь может обрабатывать трехмерные временные ряды вместо простой двумерной последовательности.
Слой кодировщика трансформатораЕсли вы хотите вместо этого погрузиться в код, поехали.
Архитектура модели со слоями Time Embeddings и Transformer
В заключение, мы сначала инициализируем слой Time Embeddings, а также 3 слоя Transformer encoder. После инициализации мы накладываем головку регрессии на последний слой преобразователя, и начинается процесс обучения.
Всего в тренировочном процессе 35 эпох. После обучения мы видим, что наша модель преобразования просто предсказывает плоскую линию, которая находится в центре между ежедневными изменениями цен на акции. При использовании только истории акций IBM даже модель трансформатора способна просто предсказать линейный тренд развития акции. Делаем вывод о том, что исторические данные о цене и объеме акции содержат достаточно пояснительной ценности только для предсказания линейного тренда. Однако при масштабировании набора данных до тысяч биржевых тикеров (набор данных в 1 терабайт) результаты выглядят совсем по-другому 🙂.
При использовании только истории акций IBM даже модель трансформатора способна просто предсказать линейный тренд развития акции. Делаем вывод о том, что исторические данные о цене и объеме акции содержат достаточно пояснительной ценности только для предсказания линейного тренда. Однако при масштабировании набора данных до тысяч биржевых тикеров (набор данных в 1 терабайт) результаты выглядят совсем по-другому 🙂.
Применение скользящего среднего к биржевым данным — разработка признаков
Как показано выше, даже самые передовые архитектуры моделей не способны извлекать нелинейные прогнозы акций из исторических цен и объемов акций. Однако при применении простого эффекта сглаживания скользящего среднего к данным (размер окна = 10) модель способна давать значительно лучшие прогнозы (зеленая линия). Вместо того, чтобы предсказывать линейный тренд акций IBM, модель также способна предсказывать взлеты и падения. Однако при внимательном наблюдении вы все же можете увидеть, что модель имеет большую дельту прогноза в дни с экстремальной скоростью ежедневных изменений, поэтому мы можем сделать вывод, что у нас все еще есть проблемы с выбросами.
Недостатком применения эффекта скользящего среднего является то, что новый набор данных больше не отражает исходные данные. Следовательно, прогнозы с эффектом скользящей средней не могут использоваться в качестве входных данных для нашего торгового бота.
Функции скользящего среднего — набор данных проверки и тестирования + прогнозыПовышение производительности за счет сглаживания эффекта скользящего среднего может быть достигнуто, однако, без применения скользящего среднего. Мое последнее исследование показало, что при расширении набора данных до большого количества акций можно получить ту же производительность.
Весь код, представленный в этой статье, является частью записной книжки, которую можно запустить от начала до конца. Блокнот можно найти на GitHub .
Примечание редакторов Towards Data Science: Хотя мы разрешаем независимым авторам публиковать статьи в соответствии с нашими правилами и рекомендациями , мы не поддерживаем вклад каждого автора. Не стоит полагаться на авторские работы, не обратившись за профессиональной консультацией. Смотрите наши Условия для чтения для получения подробной информации.
Не стоит полагаться на авторские работы, не обратившись за профессиональной консультацией. Смотрите наши Условия для чтения для получения подробной информации.
Отредактировано 1 июня 2022 г.:
В прошлом я получал массу отзывов и просьб сделать мои модели прогнозирования финансовых активов доступными и удобными в использовании. Это помогло бы людям ответить на такие вопросы, как:
В какие активы стоит инвестировать? Что я вкладываю в свой финансовый портфель?
Позвольте представить вам PinkLion www.pinklion.xyz
PinkLion
Мы избавим вас от утомительной и раздражающей части вашей работы. Больше не нужно очищать данные, тестировать модели и…
www.pinklion.xyz
PinkLion — это продукт, созданный на основе моей кодовой базы, чтобы сделать ежедневные данные об активах доступными для тысяч акций, фондов/ETF и криптовалют. Кроме того, он позволяет оперативно анализировать активы и оптимизировать портфель, предоставляя доступ к базовым моделям прогнозирования.
На данный момент количество регистраций по-прежнему ограничено из-за огромного количества серверных ресурсов, необходимых для отдельных расчетов.
Не стесняйтесь попробовать и оставить отзыв. (Он все еще находится в грубом состоянии) www.pinklion.xyz
Ничто из содержания, представленного в этой статье, не является рекомендацией о том, что какая-либо конкретная ценная бумага, портфель ценных бумаг, сделка или инвестиционная стратегия подходят для любого конкретного человека. Торговля фьючерсами, акциями и опционами сопряжена со значительным риском убытков и подходит не каждому инвестору. Оценка фьючерсов, акций и опционов может колебаться, и в результате клиенты могут потерять больше, чем их первоначальные инвестиции.
[1] Почему внимание к себе? Целевая оценка архитектур нейронного машинного перевода https://arxiv.org/abs/1808.08946
[2] BERT: предварительное обучение глубоких двунаправленных преобразователей для понимания языка https://arxiv. org/abs/1810.04805
org/abs/1810.04805
[ 3] Time2Vec: Изучение векторного представления времени https://arxiv.org/abs/1907.05321
[4] Внимание — это все, что вам нужно https://arxiv.org/abs/1706.03762
Тенденции рынка трансформаторов
Рынок трансформаторов ТенденцииОжидается, что распределительные трансформаторы будут доминировать на рынке
- Окончательный переход напряжения в системе распределения электроэнергии осуществляется распределительными трансформаторами (РТ). ДТ используются для снижения напряжения распределительных сетей, которое часто достигает 36 кВ, до уровня, который использует клиент.
- Во многих странах расширение проектов по передаче и распределению электроэнергии в последнее время привело к постоянному увеличению мощности трансформаторов. Например, трансформаторная мощность распределительной сети в Мексике достигла 1 14 807 МВА в 2021 году. Расширение передающих сетей многих других стран привело к широкому использованию распределительных трансформаторов.

- В дополнение к удовлетворению потребности в электроэнергии в часы пик коммунальные предприятия строят регуляторы напряжения распределения для увеличения энергопотребления в непиковые часы. Например, дистрибьютор дискретных полупроводниковых компонентов Diotec Semiconductor и Mouser Electronics Inc. в соответствии с контрактом заключили дистрибьюторскую сделку в июне 2022 года. Mouser предоставит клиентам выбор регуляторов напряжения, выпрямителей, полевых транзисторов и диодов от Diotec Semiconductor для коммерческого и промышленного применения.
- В апреле 2021 года итальянская энергетическая компания Enel объявила о планах войти в бизнес по распределению электроэнергии в США. Компания планирует инвестировать около 19,52 млрд долларов США в распределительные сети в течение следующих двух лет и 72,23 млрд долларов США к 2030 году.
- Такое развитие событий сильно способствует быстрому росту рынка распределительных трансформаторов в ближайшем будущем.
Чтобы понять основные тенденции, загрузите образец Отчет
Ожидается, что Азиатско-Тихоокеанский регион будет доминировать на рынке
- В последние годы во многих азиатских странах наблюдается постоянное расширение сетей распределения электроэнергии, чтобы обеспечить доступ к лишенным электричества населенным пунктам и развить существующую энергетическую инфраструктуру в полугородских районах.

- Страны с самым высоким спросом на электроэнергию — Китай и Индия. Потребление электроэнергии в Индии в 2021 году составляло около 1191 ТВтч, тогда как в Китае – 6752 ТВтч. Страны планируют еще больше расширить свои электрические сети в ближайшие годы.
- В январе 2022 года компания Madhya Pradesh Poorv Kshetra Vidyut Vitaran Co Ltd. объявила новый тендер на поставку цифрового трехфазного распределительного трансформатора для государственной распределительной сети штата Мадхья-Прадеш.
- По состоянию на май 2022 года, по данным Центрального управления электроэнергетики (CEA), общая установленная мощность возобновляемых источников энергии в Индии составляла 159,94 ГВт. К 2022 г. страна готова достичь своей цели – 175 ГВт возобновляемых источников энергии. В ноябре 2021 г. правительство Индии объявило о новой цели по неископаемым источникам энергии – 500 ГВт к 2030 г.
- В январе 2022 года Государственная электросетевая компания Китая объявила о строительстве 13 линий сверхвысокого напряжения (10 переменного тока и 3 постоянного тока) с мощностью преобразования 340 млн кВА и общим объемом инвестиций 55 млрд долларов США.
