Трансформатор тскс 40: Трансформатор ТСКС-40 | ТСКС-25 | ТСКС-16 | ТСКС-10
alexxlab | 17.03.2023 | 0 | Разное
Трансформаторы ТСКС-10 / ТСКС-16 / ТСКС-25 / ТСКС-40 — Силектра
Описание
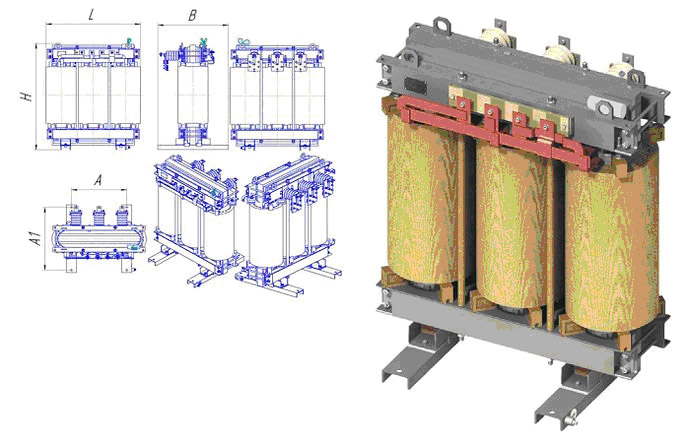
Трансформаторы ТСКС-10 / ТСКС-16 / ТСКС-25 / ТСКС-40Трехфазные сухие трансформаторы специального назначения типа ТСКС мощностью 10; 16; 25 и 40 кВА предназначены для собственных нужд шкафов (ячеек) КРУ класса напряжения 6 и 10 кВ.
Трансформаторы силовые типа ТСКС имеют высокую надежность, пожаробезопасны, т.к обмотки и изоляционные детали активной части трансформаторов выполнены из материалов, не поддерживающих горения. Трансформаторы требуют минимальных затрат на обслуживание, экономичны и просты в эксплуатации.
Трансформаторы ТСКС незащищенного исполнения (степень защиты IP00), выполнены с облегченной изоляцией.
Класс нагревостойкости – F.
Вид климатического исполнения – УХЛ.
Категория размещения – 4.
Режим работы – продолжительный.
Температура окружающего воздуха – от +1ºС до + 40ºС.
Относительная влажность воздуха при +25ºС – не более 80%.
Корректированный уровень звуковой мощности не более 60 дБА.
Трансформаторы должны эксплуатироваться в следующих условиях:
а) высота над уровнем моря не более 1000 м;
в) трансформаторы не предназначены для работы в условиях тряски, вибрации, ударов, взрывоопасной и химически агрессивной среды.
Частота питающей сети – 50Гц.
Напряжение на стороне ВН – 6; 6,3; 10; 10,5 кВ.
Напряжение на стороне НН – 0,4; 0,23 кВ.
По требованию заказчика завод может изготовить трансформаторы на сторонах ВН и НН с иными значениями напряжений.
Готовы изготовить нестандартные трансформаторы. Вся продукция сертифицирована по системе сертификации ГОСТ Р Госстандарта России и имеет сертификаты соответствия.
Материал обмоток – медь.
По требованию заказчика трансформаторы комплектуются блоком контроля температуры (за дополнительную плату).
Схема и группа соединения – Y/Yн-0; Д/Yн-11; Y/Д-11.
ОСНОВНЫЕ ТЕХНИЧЕСКИЕ ХАРАКТЕРИСТИКИ
| Тип трансформатора | Мощность, кВА | Напряжение к. | Потери, Вт | Габаритные размеры, мм | Масса, кг | |||||
| х.х. | к.з. при 75ºС | L | В | Н | А | А1 | ||||
| ТСКС-10 | 10 | 2,5 | 80 | 300 | 610 | 260 | 635 | 220 | 240 | |
| ТСКС-16 | 16 | 120 | 500 | 270 | ||||||
| ТСКС-25 | 25 | 160 | 700 | 645 | 455 | 740 | 450 | 360 | 270 | |
| ТСКС-40 | 38 | 1,5 | 360 | 500 | 695 | 290 | 760 | 480 | 250 | 370 |
Трансформаторы собственных нужд серий ТСКС-40/145/10-10(6)/0,4.
 ..
..100 р.
Купить
ООО ПКФ “Контакт” производит и поставляет трансформаторы собственных нужд серий ТСКС-40/145/10-10(6)/0,4, ТСКС 40/145/10-6(10)/0,23 ТСКС-25-6(10)/0,23, ТСКС-25-10(6)/0,4 для высоковольтных ячеек.
ООО ПКФ “Контакт” производит и поставляет трансформаторы собственных нужд серий ТСКС-40/145/10-10(6)/0,4, ТСКС 40/145/10-6(10)/0,23 ТСКС-25-6(10)/0,23, ТСКС-25-10(6)/0,4 для высоковольтных ячеек. Вся продукция сертифицирована. Доставка в любой регион РФ. Трансформаторы типа ТСКС-40/145/10(6)/0,4(0,23) трехфазные сухие специального назначения предназначены для питания собственных нужд шкафов КРУ класса напряжения 6 и 10 кВ, изготовляются для нужд народного хозяйства и для поставок на экспорт как комплектующие изделия. Частота напряжения питающей сети 50 Гц, допускается работа при 60 Гц. Структура условного обозначения ТСКС-40/145/10-Х3: Т – трехфазный; С – естественное воздушное охлажление при открытом исполнении; К – для КРУ; С – специальный; 40 – типовая мощность, кВ·А; 145 – мощность при броске тока, кВ·А; 10 – класс напряжения обмотки ВН, кВ; Х3 – климатическое исполнение (У, Т) и категория размещения по ГОСТ 15150-69.
Как работают трансформеры? – Hugging Face Course
В этом разделе мы подробно рассмотрим архитектуру моделей Transformer.![]()
Немного истории Трансформера
Вот некоторые ориентиры в (краткой) истории моделей Transformer:
Архитектура Transformer была представлена в июне 2017 года. В центре внимания первоначального исследования были задачи перевода. За этим последовало введение нескольких влиятельных моделей, в том числе:
Июнь 2018 г. : GPT, первая предварительно обученная модель Transformer, используемая для тонкой настройки различных задач НЛП и позволяющая получить самые современные результаты
Октябрь 2018 г. : BERT, еще одна большая предварительно обученная модель, предназначенная для создания более качественных сводок предложений (подробнее об этом в следующей главе!)
Февраль 2019 г. : GPT-2, улучшенная (и увеличенная) версия GPT, которая не была сразу опубликована из соображений этики
Октябрь 2019 г. : DistilBERT, очищенная версия BERT, которая на 60 % быстрее, на 40 % меньше памяти и при этом сохраняет 97 % производительности BERT
Октябрь 2019 г.
 : BART и T5, две большие предварительно обученные модели, использующие ту же архитектуру, что и исходная модель Transformer (первая, которая сделала это)
: BART и T5, две большие предварительно обученные модели, использующие ту же архитектуру, что и исходная модель Transformer (первая, которая сделала это)Май 2020 г. , GPT-3, еще более крупная версия GPT-2, способная хорошо выполнять различные задачи без необходимости тонкой настройки (называется обучение нулевому выстрелу )
Этот список далеко не исчерпывающий и предназначен только для выделения нескольких различных типов моделей Transformer. В целом их можно разделить на три категории:
- GPT-подобные модели (также называемые авторегрессивными моделями Transformer)
- BERT-подобные (также называемые моделями с автоматическим кодированием Transformer)
- BART/T5-подобные (также называемые моделями последовательного преобразования Transformer)
Позже мы более подробно рассмотрим эти семьи.
Трансформеры — это языковые модели
Все упомянутые выше модели Transformer (GPT, BERT, BART, T5 и т. д.) были обучены как языковые модели . Это означает, что они были обучены работе с большими объемами необработанного текста под самоконтролем. Самоконтролируемое обучение — это тип обучения, при котором цель автоматически вычисляется на основе входных данных модели. Это означает, что люди не нужны для маркировки данных!
д.) были обучены как языковые модели . Это означает, что они были обучены работе с большими объемами необработанного текста под самоконтролем. Самоконтролируемое обучение — это тип обучения, при котором цель автоматически вычисляется на основе входных данных модели. Это означает, что люди не нужны для маркировки данных!
Этот тип модели развивает статистическое понимание языка, на котором он был обучен, но он не очень полезен для конкретных практических задач. Из-за этого общая предварительно обученная модель затем проходит процесс, называемый трансферным обучением . В ходе этого процесса модель настраивается контролируемым образом, то есть с использованием аннотированных человеком меток, для данной задачи.
Пример задания – угадать следующее слово в предложении, прочитав n предыдущих слов. Это называется каузальным языковым моделированием , потому что результат зависит от прошлых и настоящих входных данных, но не от будущих.
Другим примером является моделирование маскированного языка , в котором модель предсказывает замаскированное слово в предложении.
Трансформеры большие модели
За исключением нескольких выбросов (например, DistilBERT), общая стратегия повышения производительности заключается в увеличении размеров моделей, а также объема данных, на которых они предварительно обучаются.
К сожалению, для обучения модели, особенно большой, требуется большой объем данных. Это становится очень затратным с точки зрения времени и вычислительных ресурсов. Это даже приводит к воздействию на окружающую среду, как показано на следующем графике.
А это демонстрирует проект для (очень большой) модели под руководством команды, сознательно пытающейся уменьшить воздействие предварительной подготовки на окружающую среду. След от проведения множества испытаний для получения лучших гиперпараметров будет еще выше.
Представьте себе, что каждый раз, когда исследовательская группа, студенческая организация или компания хотят обучить модель, они делают это с нуля. Это привело бы к огромным, ненужным глобальным затратам!
Вот почему совместное использование языковых моделей имеет первостепенное значение: совместное использование обученных весов и построение на основе уже обученных весов снижает общую стоимость вычислений и углеродный след сообщества.
Кстати, вы можете оценить углеродный след обучения ваших моделей с помощью нескольких инструментов. Например, ML CO2 Impact или Code Carbon, которые интегрированы в 🤗 Transformers. Чтобы узнать больше об этом, вы можете прочитать этот пост в блоге, который покажет вам, как создать mission.csv файл с оценкой площади вашей тренировки, а также документация 🤗 Transformers, посвященная этой теме.
Трансферное обучение
Предварительное обучение — это процесс обучения модели с нуля: веса инициализируются случайным образом, и обучение начинается без каких-либо предварительных знаний.
Это предварительное обучение обычно выполняется на очень больших объемах данных. Поэтому для этого требуется очень большой массив данных, а обучение может занять до нескольких недель.
Тонкая настройка , с другой стороны, это обучение, выполненное после того, как модель была предварительно обучена. Чтобы выполнить точную настройку, вы сначала получаете предварительно обученную языковую модель, а затем выполняете дополнительное обучение с набором данных, специфичным для вашей задачи. Подождите — почему бы просто не тренироваться непосредственно перед последним заданием? Есть несколько причин:
Подождите — почему бы просто не тренироваться непосредственно перед последним заданием? Есть несколько причин:
- Предварительно обученная модель уже была обучена на наборе данных, который имеет некоторое сходство с набором данных тонкой настройки. Таким образом, процесс тонкой настройки может использовать знания, полученные исходной моделью во время предварительного обучения (например, для задач НЛП предварительно обученная модель будет иметь какое-то статистическое понимание языка, который вы используете для своей задачи).
- Поскольку предварительно обученная модель уже была обучена на большом количестве данных, для точной настройки требуется намного меньше данных, чтобы получить достойные результаты.
- По той же причине количество времени и ресурсов, необходимых для получения хороших результатов, намного ниже.
Например, можно использовать предварительно обученную модель, обученную английскому языку, а затем настроить ее на корпусе arXiv, в результате чего получится научно-исследовательская модель. Для точной настройки потребуется лишь ограниченный объем данных: знания, полученные предварительно обученной моделью, «передаются», отсюда и термин 9.0045 перевод обучения .
Для точной настройки потребуется лишь ограниченный объем данных: знания, полученные предварительно обученной моделью, «передаются», отсюда и термин 9.0045 перевод обучения .
Таким образом, точная настройка модели требует меньше времени, данных, финансовых и экологических затрат. Также быстрее и проще перебирать различные схемы тонкой настройки, поскольку обучение требует меньше усилий, чем полное предварительное обучение.
Этот процесс также даст лучшие результаты, чем обучение с нуля (если только у вас нет большого количества данных), поэтому вы всегда должны пытаться использовать предварительно обученную модель — модель, максимально приближенную к поставленной задаче — и хорошо -настроить его.
Общая архитектура
В этом разделе мы рассмотрим общую архитектуру модели Transformer. Не волнуйтесь, если вы не понимаете некоторые концепции; позже есть подробные разделы, посвященные каждому из компонентов.
Введение
Модель в основном состоит из двух блоков:
- Кодировщик (слева) : Кодировщик получает входные данные и строит их представление (его функции).
 Это означает, что модель оптимизирована для получения понимания из входных данных.
Это означает, что модель оптимизирована для получения понимания из входных данных. - Декодер (справа) : Декодер использует представление (функции) кодировщика вместе с другими входными данными для создания целевой последовательности. Это означает, что модель оптимизирована для получения выходных данных.
Каждая из этих частей может использоваться независимо, в зависимости от задачи:
- Модели только для кодировщика : Подходит для задач, требующих понимания входных данных, таких как классификация предложений и распознавание именованных объектов.
- Модели только с декодером : Подходит для генеративных задач, таких как генерация текста.
- Модели кодировщик-декодер или модели последовательностей последовательностей : Хорошо подходит для генеративных задач, требующих ввода, таких как преобразование или суммирование.
Мы рассмотрим эти архитектуры отдельно в следующих разделах.
Слои внимания
Ключевой особенностью моделей Transformer является то, что они состоят из специальных слоев, называемых слоями внимания . На самом деле, название документа, посвященного архитектуре Transformer, было «Внимание — это все, что вам нужно»! Мы рассмотрим детали слоев внимания позже в этом курсе; на данный момент все, что вам нужно знать, это то, что этот слой скажет модели обращать особое внимание на определенные слова в предложении, которое вы ему передали (и более или менее игнорировать другие) при работе с представлением каждого слова.
Чтобы понять это, рассмотрим задачу перевода текста с английского на французский. Учитывая ввод «Вам нравится этот курс», модель перевода должна будет также учитывать соседнее слово «Вы», чтобы получить правильный перевод слова «нравится», потому что во французском языке глагол «нравится» спрягается по-разному в зависимости от предмет. Однако остальная часть предложения бесполезна для перевода этого слова.![]() В том же духе при переводе «это» модели также необходимо будет обратить внимание на слово «курс», потому что «это» переводится по-разному в зависимости от того, является ли связанное существительное мужским или женским. Опять же, другие слова в предложении не будут иметь значения для перевода «этого». С более сложными предложениями (и более сложными грамматическими правилами) модели потребуется уделять особое внимание словам, которые могут оказаться дальше в предложении, чтобы правильно перевести каждое слово.
В том же духе при переводе «это» модели также необходимо будет обратить внимание на слово «курс», потому что «это» переводится по-разному в зависимости от того, является ли связанное существительное мужским или женским. Опять же, другие слова в предложении не будут иметь значения для перевода «этого». С более сложными предложениями (и более сложными грамматическими правилами) модели потребуется уделять особое внимание словам, которые могут оказаться дальше в предложении, чтобы правильно перевести каждое слово.
Та же концепция применима к любой задаче, связанной с естественным языком: слово само по себе имеет значение, но это значение сильно зависит от контекста, которым может быть любое другое слово (или слова) до или после изучаемого слова.
Теперь, когда у вас есть представление о том, что такое уровни внимания, давайте подробнее рассмотрим архитектуру Transformer.
Оригинальная архитектура
Архитектура Transformer изначально была разработана для трансляции. Во время обучения кодировщик получает входные данные (предложения) на определенном языке, а декодер получает те же предложения на желаемом целевом языке. В кодировщике уровни внимания могут использовать все слова в предложении (поскольку, как мы только что видели, перевод данного слова может зависеть от того, что в предложении находится после него, а также перед ним). Декодер, однако, работает последовательно и может обращать внимание только на слова в предложении, которые он уже перевел (то есть только на слова перед генерируемым в данный момент словом). Например, когда мы предсказали первые три слова переведенной цели, мы передаем их декодеру, который затем использует все входные данные кодировщика, чтобы попытаться предсказать четвертое слово.
Во время обучения кодировщик получает входные данные (предложения) на определенном языке, а декодер получает те же предложения на желаемом целевом языке. В кодировщике уровни внимания могут использовать все слова в предложении (поскольку, как мы только что видели, перевод данного слова может зависеть от того, что в предложении находится после него, а также перед ним). Декодер, однако, работает последовательно и может обращать внимание только на слова в предложении, которые он уже перевел (то есть только на слова перед генерируемым в данный момент словом). Например, когда мы предсказали первые три слова переведенной цели, мы передаем их декодеру, который затем использует все входные данные кодировщика, чтобы попытаться предсказать четвертое слово.
Чтобы ускорить процесс во время обучения (когда модель имеет доступ к целевым предложениям), декодер получает цель целиком, но ему не разрешается использовать будущие слова (если он имел доступ к слову в позиции 2 при попытке предсказать слово на позиции 2, задача будет несложной!).![]() Например, при попытке предсказать четвертое слово уровень внимания будет иметь доступ только к словам в позициях с 1 по 3.
Например, при попытке предсказать четвертое слово уровень внимания будет иметь доступ только к словам в позициях с 1 по 3.
Первоначальная архитектура Transformer выглядела так, с энкодером слева и декодером справа:
Обратите внимание, что первый уровень внимания в блоке декодера обращает внимание на все (прошлые) входные данные декодера, а второй уровень внимания использует выходные данные кодера. Таким образом, он может получить доступ ко всему входному предложению, чтобы наилучшим образом предсказать текущее слово. Это очень полезно, так как разные языки могут иметь грамматические правила, которые располагают слова в разном порядке, или некоторый контекст, предоставленный позже в предложении, может быть полезен для определения наилучшего перевода данного слова.
9Маска внимания 0045 также может использоваться в кодере/декодере, чтобы модель не обращала внимания на некоторые специальные слова — например, на специальное слово-заполнитель, используемое для придания всем входным данным одинаковой длины при группировании предложений.![]()
Архитектуры против контрольных точек
Когда мы углубимся в модели Transformer в этом курсе, вы увидите упоминания об архитектуре и контрольно-пропускных пунктах , а также о моделях . Все эти термины имеют немного разные значения:
- Архитектура : Это скелет модели — определение каждого слоя и каждой операции, происходящей в модели.
- Контрольные точки : Это веса, которые будут загружены в данной архитектуре.
- Модель : это общий термин, который не так точен, как «архитектура» или «контрольно-пропускной пункт»: он может означать и то, и другое. В этом курсе будет указана архитектура или контрольная точка , когда это необходимо для уменьшения неоднозначности.
Например, BERT — это архитектура, а bert-base-cased — набор весов, подготовленный командой Google для первого выпуска BERT, — контрольная точка.![]() Тем не менее, можно сказать «модель BERT» и «модель в базовом корпусе ».
Тем не менее, можно сказать «модель BERT» и «модель в базовом корпусе ».
GPT. Модели Open AI GPT-1, GPT-2, GPT-3
Фото: Изображение Free-Photos с PixabayМодели генеративного предварительно обученного преобразователя (GPT) от OpenAI взяли штурмом сообщество обработки естественного языка (NLP), представив очень мощные языковые модели. Эти модели могут выполнять различные задачи НЛП, такие как ответы на вопросы, вывод текста, обобщение текста и т. д. без какого-либо контролируемого обучения. Эти языковые модели нуждаются в очень небольшом количестве примеров или вообще не нуждаются в них, чтобы понять задачи и работать так же или даже лучше, чем современные модели, обученные в режиме с учителем.
В этой статье мы расскажем о путешествии этих моделей и поймем, как они развивались в течение двух лет. Здесь мы рассмотрим следующие темы:
1. Обсуждение документа GPT-1 (Улучшение понимания языка с помощью генеративного предварительного обучения).
2. Обсуждение документа GPT-2 (Языковые модели представляют собой неконтролируемое многозадачное обучение) и его последующих улучшений по сравнению с GPT-1.
3. Обсуждение статьи GPT-3 (Языковые модели мало кто может выучить) и усовершенствований, которые сделали ее одной из самых мощных моделей НЛП на сегодняшний день.
В этой статье предполагается знакомство с основами терминологии НЛП и архитектурой преобразователя.
Давайте начнем с того, что разберемся в этих документах один за другим. Чтобы сделать это путешествие более понятным, я разделил каждый документ на четыре раздела: цели и концепции, обсуждаемые в документах, используемые наборы данных, архитектура модели и детали реализации, а также оценка их производительности.
До этой работы большинство современных моделей НЛП обучались специально для решения конкретной задачи, такой как классификация настроений, вывод текста и т. д., с использованием обучения с учителем. Однако модели с учителем имеют два основных ограничения:
и. Им требуется большой объем аннотированных данных для изучения конкретной задачи, которая часто недоступна.
Им требуется большой объем аннотированных данных для изучения конкретной задачи, которая часто недоступна.
ii. Им не удается обобщить задачи, отличные от тех, для которых они были обучены.
В этом документе предлагается изучить генеративную языковую модель с использованием неразмеченных данных, а затем отрегулировать модель, предоставив примеры конкретных последующих задач, таких как классификация, анализ настроений, текстовые следствия и т. д. точно настроенные модели, отсюда и название «Генеративное предварительное обучение».
Давайте рассмотрим концепции и подходы, обсуждаемые в этой статье.
1. Цели и концепции обучения : Это частично контролируемое обучение (неконтролируемое предварительное обучение с последующей контролируемой точной настройкой) для задач НЛП состоит из следующих трех компонентов:
a. Неконтролируемое языковое моделирование (предварительное обучение): для неконтролируемого обучения использовалась стандартная цель языковой модели.
, где T — набор токенов в неконтролируемых данных {t_1,…,t_n}, k — размер контекстного окна, θ — параметры нейронной сети, обученной методом стохастического градиентного спуска.
б. Контролируемая тонкая настройка : Эта часть нацелена на максимальное увеличение вероятности наблюдения метки y с заданными функциями или токенами x_1,…,x_n.
, где C — помеченный набор данных, состоящий из обучающих примеров.
Вместо того, чтобы просто максимизировать цель, упомянутую в уравнении (ii), авторы добавили вспомогательную цель обучения для контролируемой тонкой настройки, чтобы получить лучшее обобщение и более быструю сходимость. Модифицированная цель обучения была сформулирована как:
, где L₁(C) — вспомогательная цель модели изучения языка, а λ — вес, присвоенный этой вторичной цели обучения. λ было установлено равным 0,5.
Контролируемая точная настройка была достигнута путем добавления линейного слоя и слоя softmax в модель преобразователя, чтобы получить метки задач для последующих задач.![]()
в. Преобразования входных данных для конкретных задач : Чтобы внести минимальные изменения в архитектуру модели во время точной настройки, входные данные для конкретных последующих задач были преобразованы в упорядоченные последовательности. Жетоны были переставлены следующим образом:
— Во входные последовательности добавлены начальные и конечные токены.
— Маркер-разделитель был добавлен между различными частями примера, чтобы входные данные можно было отправлять в виде упорядоченной последовательности. Для таких задач, как ответы на вопросы, вопросы с несколькими вариантами ответов и т. д., для каждого примера было отправлено несколько последовательностей. Например. обучающий пример, состоящий из последовательностей для контекста, вопроса и ответа для задачи ответа на вопрос.
2. Набор данных : GPT-1 использовал набор данных BooksCorpus для обучения языковой модели. У BooksCorpus было около 7000 неопубликованных книг, которые помогли обучить языковую модель на невидимых данных. Эти данные вряд ли можно было найти в тестовом наборе последующих задач. Кроме того, в этом корпусе были большие участки непрерывного текста, что помогло модели изучить зависимости большого диапазона.
Эти данные вряд ли можно было найти в тестовом наборе последующих задач. Кроме того, в этом корпусе были большие участки непрерывного текста, что помогло модели изучить зависимости большого диапазона.
3. Архитектура модели и подробности реализации : GPT-1 использовала 12-уровневый декодер только структуру преобразователя с маскированным внутренним вниманием для обучения языковой модели. Архитектура модели во многом осталась такой же, как описано в оригинальной работе о трансформерах. Маскировка помогла достичь цели языковой модели, при которой языковая модель не имела доступа к последующим словам справа от текущего слова.
Подробности реализации:
а. Для неконтролируемого обучения :
- Использовался словарь кодирования байтовых пар (BPE) с 40 000 слияний.
- Модель использовала 768-мерное состояние для кодирования токенов во встраивания слов. Позиционные вложения также были изучены во время обучения.
- Использовалась 12-уровневая модель с 12 головками внимания в каждом слое само-внимания.

- Для позиционного слоя прямой связи использовалось 3072-мерное состояние.
- Использовался оптимизатор Adam со скоростью обучения 2,5e-4.
- Внимание, для регуляризации использовались остаточные и встраивающие отсева с коэффициентом отсева 0,1. Модифицированная версия регуляризации L2 также использовалась для несмещенных весов. В качестве функции активации использовали
- GELU.
- Модель обучалась в течение 100 эпох на мини-пакетах размером 64 и длиной последовательности 512. Всего модель имела 117 млн параметров.
б. Для контролируемой тонкой настройки :
- Контролируемая тонкая настройка заняла всего 3 эпохи для большинства последующих задач. Это показало, что модель уже многое узнала о языке во время предварительного обучения. Таким образом, было достаточно минимальной тонкой настройки.
- Большинство гиперпараметров из неконтролируемой предварительной подготовки использовались для тонкой настройки.

4. Производительность и сводка :
GPT-1 показала лучшие результаты, чем специально обученные современные модели под наблюдением, в 9 из 12 задач, по которым модели сравнивались.
Еще одним значительным достижением этой модели стала ее неплохая нулевая производительность на различных задачах. В документе показано, что модель развивалась с нулевой производительностью в различных задачах НЛП, таких как ответы на вопросы, разрешение схемы, анализ настроений и т. Д., Благодаря предварительному обучению.
GPT-1 доказала, что языковая модель служит эффективной целью предварительного обучения, которая может помочь модели хорошо обобщаться. Архитектура облегчала перенос обучения и могла выполнять различные задачи НЛП с очень небольшой тонкой настройкой. Эта модель продемонстрировала мощь генеративного предварительного обучения и открыла возможности для других моделей, которые могли бы лучше раскрыть этот потенциал с большими наборами данных и большим количеством параметров.![]()
Изменения в модели GPT-2 были в основном связаны с использованием большего набора данных и добавлением большего количества параметров в модель для изучения еще более сильной языковой модели. Давайте посмотрим на важные изменения в модели GPT-2 и концепции, обсуждаемые в документе:
- Цели обучения и концепции : Ниже приведены две важные концепции, обсуждаемые в этой статье в контексте НЛП.
- Условие задачи : Мы видели, что цель обучения языковой модели формулируется как P (выход | ввод). Однако GPT-2 нацелен на изучение нескольких задач с использованием одной и той же модели без учителя. Для этого цель обучения должна быть изменена на P (выход | ввод, задача). Эта модификация известна как согласование задач, когда ожидается, что модель будет выдавать разные выходные данные для одних и тех же входных данных для разных задач. Некоторые модели реализуют обусловливание задач на архитектурном уровне, когда модель получает как входные данные, так и задачу.
 Для языковых моделей вывод, ввод и задача — все это последовательности естественного языка. Таким образом, условие задачи для языковых моделей выполняется путем предоставления модели примеров или инструкций на естественном языке для выполнения задачи. Обусловливание задачи формирует основу для переноса задачи с нулевым выстрелом, который мы рассмотрим далее.
Для языковых моделей вывод, ввод и задача — все это последовательности естественного языка. Таким образом, условие задачи для языковых моделей выполняется путем предоставления модели примеров или инструкций на естественном языке для выполнения задачи. Обусловливание задачи формирует основу для переноса задачи с нулевым выстрелом, который мы рассмотрим далее. - Обучение Zero Shot и передача Zero Short Task : Интересная возможность GPT 2 — передача задач с нулевым выстрелом. Обучение с нулевым выстрелом — это частный случай передачи задачи с нулевым выстрелом, когда примеры вообще не приводятся, а модель понимает задачу на основе данной инструкции. Вместо перестановки последовательностей, как это было сделано для GPT-1 для точной настройки, входные данные для GPT-2 были даны в формате, который ожидал, что модель поймет характер задачи и даст ответы. Это было сделано для имитации поведения передачи задач с нулевым выстрелом. Например. для задачи перевода с английского на французский модели было дано английское предложение, за которым следовало слово французский и подсказка (:).
 Модель должна была понять, что это переводческая задача, и дать французский аналог английского предложения.
Модель должна была понять, что это переводческая задача, и дать французский аналог английского предложения.
2. Набор данных : Чтобы создать обширный набор данных хорошего качества, авторы очистили платформу Reddit и извлекли данные из исходящих ссылок статей, получивших большое количество голосов. Получившийся набор данных под названием WebText содержал 40 ГБ текстовых данных из более чем 8 миллионов документов. Этот набор данных использовался для обучения GPT-2 и был огромен по сравнению с набором данных Book Corpus, используемым для обучения модели GPT-1. Все статьи из Википедии были удалены из WebText, так как многие наборы тестов содержат статьи из Википедии.
3. Архитектура модели и детали реализации : GPT-2 имеет 1,5 миллиарда параметров. что было в 10 раз больше, чем у ГПТ-1 (параметры 117М). Основные отличия от GPT-1 заключались в следующем:
- GPT-2 имел 48 слоев и использовал 1600 размерных векторов для встраивания слов.

- Был использован больший словарь из 50 257 токенов.
- Использовался больший размер пакета 512 и большее окно контекста 1024 маркера.
- Нормализация слоя перенесена на вход каждого подблока и добавлена нормализация дополнительного слоя после финального блока самоконтроля.
- При инициализации вес остаточных слоев масштабировался по шкале 1/√N, где N — количество остаточных слоев.
Авторы обучили четыре языковые модели с параметрами 117M (аналог GPT-1), 345M, 762M и 1.5B (GPT-2). Каждая последующая модель имела меньшее недоумение, чем предыдущая. Это установило, что недоумение языковых моделей в одном и том же наборе данных уменьшается с увеличением количества параметров. Кроме того, модель с наибольшим количеством параметров лучше справлялась с каждой последующей задачей.
4. Производительность и сводка : GPT-2 оценивался по нескольким наборам данных последующих задач, таких как понимание прочитанного, обобщение, перевод, ответы на вопросы и т. д. Давайте подробно рассмотрим некоторые из этих задач и производительность GPT-2 по ним. :
д. Давайте подробно рассмотрим некоторые из этих задач и производительность GPT-2 по ним. :
- GPT-2 улучшил существовавший на тот момент уровень техники для 7 из 8 наборов данных языкового моделирования в нулевых настройках.
- Набор данных для детских книг оценивает производительность языковых моделей для таких категорий слов, как существительные, предлоги, именованные объекты и т. д. GPT-2 повысил современную точность примерно на 7% для распознавания имен нарицательных и именованных объектов.
- Набор данных LAMBADA оценивает эффективность моделей при выявлении долгосрочных зависимостей и прогнозировании последнего слова предложения. GPT-2 уменьшил недоумение с 99,8 до 8,6 и значительно повысил точность.
- GPT-2 превзошел 3 из 4 базовых моделей в задачах на понимание прочитанного при нулевых настройках.
- В задаче перевода с французского на английский язык GPT-2 работал лучше, чем большинство неконтролируемых моделей в режиме нулевого выстрела, но не превосходил современную неконтролируемую модель.

- GPT-2 не мог хорошо работать с резюмированием текста, и его производительность была такой же или меньшей, чем у классических моделей, обученных для реферирования.
GPT-2 удалось достичь самых современных результатов на 7 из 8 протестированных наборов данных языкового моделирования в нулевом выстреле.
GPT-2 показал, что обучение на большем наборе данных и с большим количеством параметров улучшило способность языковой модели понимать задачи и превзошло современное состояние многих задач в условиях нулевого выстрела. В документе говорится, что с увеличением емкости модели производительность увеличивается логарифмически линейно. Также падение недоумения языковых моделей не демонстрировало насыщения и продолжало уменьшаться с увеличением количества параметров. На самом деле, GPT-2 не соответствовал набору данных WebText, и обучение в течение большего времени могло бы еще больше уменьшить недоумение. Это показало, что размер модели GPT-2 не был пределом, и создание еще более крупных языковых моделей уменьшит недоумение и улучшит языковые модели для понимания естественного языка.
В своем стремлении создать очень сильные и мощные языковые модели, которые не требуют тонкой настройки и требуют лишь нескольких демонстраций для понимания задач и их выполнения, Open AI построил модель GPT-3 со 175 миллиардами параметров. Эта модель имела в 10 раз больше параметров, чем мощная языковая модель Microsoft Turing NLG, и в 100 раз больше параметров, чем GPT-2. Благодаря большому количеству параметров и обширному набору данных, на которых был обучен GPT-3, он хорошо работает с последующими задачами НЛП в условиях нулевого выстрела и нескольких выстрелов. Из-за своей большой емкости у него есть такие возможности, как написание статей, которые трудно отличить от статей, написанных людьми. Он также может выполнять на лету задачи, на которых он никогда не обучался явно, такие как суммирование чисел, написание SQL-запросов и кодов, расшифровка слов в предложении, написание кода React и JavaScript с учетом описания задачи на естественном языке и т. д. Давайте понять концепции и разработки, упомянутые в документе GPT-3, а также некоторые более широкие последствия и ограничения этой модели:
- Цели обучения и концепции : Давайте обсудим две концепции, обсуждаемые в этой статье.

- Обучение в контексте : Большие языковые модели развивают распознавание образов и другие навыки, используя текстовые данные, на которых они обучаются. Изучая основную цель предсказания следующего слова с учетом контекстных слов, языковые модели также начинают распознавать закономерности в данных, что помогает им минимизировать потери для задачи языкового моделирования. Позже эта способность помогает модели при переносе задачи с нуля. Когда представлено несколько примеров и/или описание того, что ему нужно делать, языковые модели сопоставляют шаблон примеров с тем, что он изучил в прошлом для аналогичных данных, и использует эти знания для выполнения задач. Это мощная возможность больших языковых моделей, которая увеличивается с увеличением количества параметров модели.
- Параметр “Несколько выстрелов”, “Один выстрел” и “Нулевой выстрел” : Как обсуждалось ранее, настройки “Несколько выстрелов”, “Один выстрел” и “Нулевой выстрел” являются особыми случаями передачи задач с нулевым выстрелом.
 В режиме нескольких кадров модель снабжена описанием задачи и таким количеством примеров, которое умещается в контекстное окно модели. В однократной настройке модели предоставляется только один пример, а в нулевой настройке пример не предоставляется. С увеличением емкости модели также улучшаются возможности модели с несколькими, единичными и нулевыми выстрелами.
В режиме нескольких кадров модель снабжена описанием задачи и таким количеством примеров, которое умещается в контекстное окно модели. В однократной настройке модели предоставляется только один пример, а в нулевой настройке пример не предоставляется. С увеличением емкости модели также улучшаются возможности модели с несколькими, единичными и нулевыми выстрелами.
2. Набор данных : GPT-3 был обучен на сочетании пяти различных корпусов, каждому из которых был присвоен определенный вес. Наборы данных высокого качества отбирались чаще, и модель обучалась на них более одной эпохи. Использовались пять наборов данных: Common Crawl, WebText2, Books1, Books2 и Wikipedia.
3. Детали модели и реализации : Архитектура GPT-3 такая же, как и GPT-2. Несколько основных отличий от GPT-2:
- GPT-3 имеет 9(-8).
- Использовались чередующиеся плотные и разреженные паттерны внимания с локальными полосами.
4. Производительность и сводка : GPT-3 был оценен на множестве наборов данных языкового моделирования и НЛП. GPT-3 работал лучше, чем современный, для наборов данных языкового моделирования, таких как LAMBADA и Penn Tree Bank, в настройках с несколькими или нулевыми выстрелами. Для других наборов данных это не могло превзойти современное состояние, но улучшило современную производительность с нулевым выстрелом. GPT-3 также достаточно хорошо показал себя в задачах НЛП, таких как ответы на вопросы в закрытой книге, разрешение схемы, перевод и т. д., часто опережая современные или сравнимые с точно настроенными моделями. Для большинства задач модель работала лучше при настройке нескольких выстрелов по сравнению с одним и нулевым выстрелом.
GPT-3 работал лучше, чем современный, для наборов данных языкового моделирования, таких как LAMBADA и Penn Tree Bank, в настройках с несколькими или нулевыми выстрелами. Для других наборов данных это не могло превзойти современное состояние, но улучшило современную производительность с нулевым выстрелом. GPT-3 также достаточно хорошо показал себя в задачах НЛП, таких как ответы на вопросы в закрытой книге, разрешение схемы, перевод и т. д., часто опережая современные или сравнимые с точно настроенными моделями. Для большинства задач модель работала лучше при настройке нескольких выстрелов по сравнению с одним и нулевым выстрелом.
Помимо оценки модели на обычных задачах НЛП, модель также оценивалась на синтетических задачах, таких как арифметическое сложение, расшифровка слов, создание новостных статей, изучение и использование новых слов и т. д. Для этих задач также производительность увеличивалась с увеличением количество параметров, и модель работала лучше в настройках с несколькими выстрелами, чем с одним и нулевым выстрелом.
5. Ограничения и более широкое влияние : В документе обсуждаются некоторые недостатки модели GPT-3 и области, требующие улучшения. Давайте обобщим их здесь.
- Хотя GPT-3 способен воспроизводить текст высокого качества, временами он начинает терять связность при формулировании длинных предложений и повторяет последовательности текста снова и снова. Кроме того, GPT-3 не очень хорошо справляется с такими задачами, как вывод на естественном языке (определение того, что если предложение подразумевает другое предложение), заполнение пробелов, некоторые задачи на понимание прочитанного и т. д. В документе упоминается однонаправленность моделей GPT как вероятная причина для эти ограничения и предлагает обучение двунаправленных моделей в этом масштабе для преодоления этих проблем.
- Другим ограничением, указанным в документе, является цель моделирования общего языка GPT-3, которая взвешивает каждый токен одинаково и не имеет понятия задачи или целевого прогнозирования токенов.
 Чтобы противостоять этому, в документе предлагаются такие подходы, как увеличение цели обучения, использование обучения с подкреплением для точной настройки моделей, добавление других модальностей и т. д. меньшая интерпретируемость языка и результатов, генерируемых моделью, а также неопределенность в отношении того, что помогает модели достичь своего поведения при обучении с небольшими выстрелами.
Чтобы противостоять этому, в документе предлагаются такие подходы, как увеличение цели обучения, использование обучения с подкреплением для точной настройки моделей, добавление других модальностей и т. д. меньшая интерпретируемость языка и результатов, генерируемых моделью, а также неопределенность в отношении того, что помогает модели достичь своего поведения при обучении с небольшими выстрелами. - Наряду с этими ограничениями, GPT-3 несет в себе потенциальный риск неправомерного использования его способности генерировать человекоподобный текст для фишинга, рассылки спама, распространения дезинформации или выполнения других мошеннических действий. Кроме того, текст, сгенерированный GPT-3, имеет предвзятость языка, на котором он обучается. Статьи, созданные с помощью GPT-3, могут иметь гендерную, этническую, расовую или религиозную предвзятость. Таким образом, становится чрезвычайно важным использовать такие модели с осторожностью и контролировать генерируемый ими текст перед его использованием.

В этой статье кратко изложены путь и развитие моделей OpenAI GPT, а также их эволюция в трех статьях. Эти модели, несомненно, являются очень мощными языковыми моделями и произвели революцию в области обработки естественного языка, выполняя множество задач, используя только инструкции и несколько примеров. Хотя эти модели не соответствуют человеческим в понимании естественного языка, они, безусловно, показали путь к достижению этой цели.
Глоссарий:- Вспомогательная цель обучения — это дополнительная цель обучения или задача, которую изучают вместе с основной целью обучения, чтобы повысить производительность моделей, сделав их более общими. В данной статье содержится более подробная информация об этой концепции.
- Маскирование относится к удалению или замене слов в предложении каким-либо другим фиктивным токеном, так что модель не имеет доступа к этим словам во время обучения.

- Парное кодирование байтов — это метод сжатия данных, при котором часто встречающиеся пары последовательных байтов заменяются байтом, отсутствующим в данных, для сжатия данных. Для восстановления исходных данных используется таблица, содержащая отображение замененных байтов. В этом блоге подробно рассказывается о BPE.
- Нулевое обучение или поведение относится к способности модели выполнять задачу, не видя в прошлом ни одного примера такого рода. Во время обучения с нулевым выстрелом обновление градиентов не происходит, и предполагается, что модель понимает задачу, не глядя на какие-либо примеры.
- Передача задачи с нулевым выстрелом или метаобучение относится к настройке, в которой модель представлена с небольшим количеством примеров или без них, чтобы она могла понять задачу. Термин «нулевой выстрел» происходит от того факта, что обновления градиента не выполняются. Модель должна понять задачу на основе примеров и инструкций.
- Недоумение — это стандартный показатель оценки языковых моделей.
