Тскс трансформатор: Трансформатор ТСКС-40 | ТСКС-25 | ТСКС-16 | ТСКС-10
alexxlab | 13.11.1989 | 0 | Разное
Трансформатор ТСКС-40, ТСКС-25, ТСКС-16, ТСКС-10 | Объявления
- 22 сентября 2022 г. в 13:18
- 118
Поделиться
Пожаловаться
ООО ЧебЭнерго предлагаем
Трехфазные сухие трансформаторы специального назначения типа ТСКС мощностью 10; 16; 25 и 40 кВА предназначены для собственных нужд шкафов (ячеек) КРУ класса напряжения 6 и 10 кВ.
Трансформаторы силовые типа ТСКС имеют высокую надежность, пожаробезопасны, т. к обмотки и изоляционные детали активной части трансформаторов выполнены из материалов, не поддерживающих горения. Трансформаторы требуют минимальных затрат на обслуживание, экономичны и просты в эксплуатации.
Трансформаторы незащищенного исполнения (степень защиты IP00), выполнены с облегченной изоляцией.
Класс нагревостойкости — F.
Вид климатического исполнения — УХЛ.
Категория размещения — 4.
Режим работы — продолжительный.
Температура окружающего воздуха — от 1ºС до 40ºС.
Относительная влажность воздуха при 25ºС — не более 80%.
Корректированный уровень звуковой мощности не более 60 дБА
Материал обмоток — медь.
По требованию заказчика трансформаторы комплектуются блоком контроля температуры (за дополнительную плату).
Схема и группа соединения — Y/Yн-0; Д/Yн-11; Y/Д-11, Y/Z
Бренд:
F&F
Состояние:
Новое
Адрес:
Чувашская республика – Чувашия
Отправить запрос
Ещё 24 объявления
Контакты
| Ф.И.О. | Данилов Сергей нет отзывов |
|---|---|
| Должность: | Менеджер продаж |
| Компания: | ЧебЭнерго, ООО |
| Город: | Чувашская республика – Чувашия |
| Телефон: | +7 (8352) 38-43-12, 38-43-17 Сообщите, что нашли информацию на сайте «Элек.ру» |
| Дата регистрации: | 12 апреля 2016 г. Последний вход 7 дней назад |
Похожие объявления
ПРОДАМ: Трансформатор ТСКС-25
Трехфазные сухие трансформаторы специального назначения типа ТСКС25 мощностью 25 кВА предназначены для собственных нужд шкафов (ячеек) КРУ класса напряжения 6 и 10 кВ.
Трансформаторы силовые типа ТСКС имеют высокую надежность, пожаробезопасны, т.к обмотки и изоляционные детали активной части трансформаторов выполнены из материалов, не поддерживающих горения. Трансформаторы требуют минимальных затрат на обслуживание, экономичны и просты в эксплуатации.
Трансформаторы незащищенного исполнения (степень защиты IP00), выполнены с облегченной изоляцией.
Класс нагревостойкости – F.
Вид климатического исполнения – УХЛ.
Категория размещения – 4.
Режим работы – продолжительный.
Температура окружающего воздуха – от +1ºС до + 40ºС.
Относительная влажность воздуха при +25ºС – не более 80%.
Корректированный уровень звуковой мощности не более 60 дБА. Трансформаторы должны эксплуатироваться в следующих условиях:
а) высота над уровнем моря не более 1000 м;
в) трансформаторы не предназначены для работы в условиях тряски, вибрации, ударов, взрывоопасной и химически агрессивной среды.
Данилов Евгений · ЧебЭнерго · 30 сентября · Россия · Чувашская республика – Чувашия
ПРОДАМ: Трансформатор ТСКС-10
Трехфазные сухие трансформаторы специального назначения типа ТСКС10 мощностью 10 кВА предназначены для собственных нужд шкафов (ячеек) КРУ класса напряжения 6 и 10 кВ. Трансформаторы силовые типа ТСКС имеют высокую надежность, пожаробезопасны, т.к обмотки и изоляционные детали активной части трансформаторов выполнены из материалов, не поддерживающих горения. Трансформаторы требуют минимальных затрат на обслуживание, экономичны и просты в эксплуатации.
Трансформаторы незащищенного исполнения (степень защиты IP00), выполнены с облегченной изоляцией.
Класс нагревостойкости – F.
Вид климатического исполнения – УХЛ.
Категория размещения – 4.
Режим работы – продолжительный.
Температура окружающего воздуха – от +1ºС до + 40ºС.
Относительная влажность воздуха при +25ºС – не более 80%.
Корректированный уровень звуковой мощности не более 60 дБА. Трансформаторы должны эксплуатироваться в следующих условиях:
а) высота над уровнем моря не более 1000 м;
в) трансформаторы не предназначены для работы в условиях тряски, вибрации, ударов, взрывоопасной и химически агрессивной среды.
Частота питающей сети – 50Гц.
Напряжение на стороне ВН – 6; 6,3; 10; 10,5 кВ.
Напряжение на стороне НН – 0,4; 0,23 кВ.
Трансформаторы силовые типа ТСКС имеют высокую надежность, пожаробезопасны, т.к обмотки и изоляционные детали активной части трансформаторов выполнены из материалов, не поддерживающих горения. Трансформаторы требуют минимальных затрат на обслуживание, экономичны и просты в эксплуатации.
Трансформаторы незащищенного исполнения (степень защиты IP00), выполнены с облегченной изоляцией.
Класс нагревостойкости – F.
Вид климатического исполнения – УХЛ.
Категория размещения – 4.
Режим работы – продолжительный.
Температура окружающего воздуха – от +1ºС до + 40ºС.
Относительная влажность воздуха при +25ºС – не более 80%.
Корректированный уровень звуковой мощности не более 60 дБА. Трансформаторы должны эксплуатироваться в следующих условиях:
а) высота над уровнем моря не более 1000 м;
в) трансформаторы не предназначены для работы в условиях тряски, вибрации, ударов, взрывоопасной и химически агрессивной среды.
Частота питающей сети – 50Гц.
Напряжение на стороне ВН – 6; 6,3; 10; 10,5 кВ.
Напряжение на стороне НН – 0,4; 0,23 кВ.![]()
Данилов Евгений · ЧебЭнерго · 30 сентября · Россия · Чувашская республика – Чувашия
ПРОДАМ: Трансформатор ТСКС-40
Трехфазные сухие трансформаторы специального назначения типа ТСКС40 мощностью 40 кВА предназначены для собственных нужд шкафов (ячеек) КРУ класса напряжения 6 и 10 кВ.
Трансформаторы силовые типа ТСКС имеют высокую надежность, пожаробезопасны, т.
 Готовы изготовить нестандартные трансформаторы. Вся продукция сертифицирована по системе сертификации ГОСТ Р Госстандарта России и имеет сертификаты соответствия.
Материал обмоток – медь.
По требованию заказчика трансформаторы комплектуются блоком контроля температуры (за дополнительную плату).
Схема и группа соединения – Y/Yн-0; Д/Yн-11; Y/Д-11.
Изделия новые!!! Короткие сроки!!!
Действует система скидок!
С уважением, Данилов Евгений.
ООО ЧебЭнерго, г. Чебоксары.
Готовы изготовить нестандартные трансформаторы. Вся продукция сертифицирована по системе сертификации ГОСТ Р Госстандарта России и имеет сертификаты соответствия.
Материал обмоток – медь.
По требованию заказчика трансформаторы комплектуются блоком контроля температуры (за дополнительную плату).
Схема и группа соединения – Y/Yн-0; Д/Yн-11; Y/Д-11.
Изделия новые!!! Короткие сроки!!!
Действует система скидок!
С уважением, Данилов Евгений.
ООО ЧебЭнерго, г. Чебоксары.Данилов Евгений · ЧебЭнерго · 30 сентября · Россия · Чувашская республика – Чувашия
ПРОДАМ: Трансформатор ТСКС-16
Трехфазные сухие трансформаторы специального назначения типа ТСКС16 мощностью 16 кВА предназначены для собственных нужд шкафов (ячеек) КРУ класса напряжения 6 и 10 кВ.
Трансформаторы силовые типа ТСКС имеют высокую надежность, пожаробезопасны, т.к обмотки и изоляционные детали активной части трансформаторов выполнены из материалов, не поддерживающих горения.
 Готовы изготовить нестандартные трансформаторы. Вся продукция сертифицирована по системе сертификации ГОСТ Р Госстандарта России и имеет сертификаты соответствия.
Материал обмоток – медь.
По требованию заказчика трансформаторы комплектуются блоком контроля температуры (за дополнительную плату).
Схема и группа соединения – Y/Yн-0; Д/Yн-11; Y/Д-11.
Изделия новые!!! Короткие сроки!!!
Действует система скидок!
С уважением, Данилов Евгений.
ООО ЧебЭнерго, г. Чебоксары.
Готовы изготовить нестандартные трансформаторы. Вся продукция сертифицирована по системе сертификации ГОСТ Р Госстандарта России и имеет сертификаты соответствия.
Материал обмоток – медь.
По требованию заказчика трансформаторы комплектуются блоком контроля температуры (за дополнительную плату).
Схема и группа соединения – Y/Yн-0; Д/Yн-11; Y/Д-11.
Изделия новые!!! Короткие сроки!!!
Действует система скидок!
С уважением, Данилов Евгений.
ООО ЧебЭнерго, г. Чебоксары.Данилов Евгений · ЧебЭнерго
ПРОДАМ: Трансформатор ТСКС
Завод «Электрон» производит и поставляет трансформаторы собственных нужд серий ТСКС-40/145/10-10(6)/0,4, ТСКС 40/145/10-6(10)/0,23 ТСКС-25-6(10)/0,23, ТСКС-25-10(6)/0,4 для высоковольтных ячеек.
Вся продукция сертифицирована. Доставка в любой регион РФ.
Трансформаторы типа ТСКС-40/145/10(6)/0,4(0,23) трехфазные сухие специального назначения предназначены для питания собственных нужд шкафов КРУ класса напряжения 6 и 10 кВ, изготовляются для нужд народного хозяйства и для поставок на экспорт как комплектующие изделия. Частота напряжения питающей сети 50 Гц, допускается работа при 60 Гц.
Структура условного обозначения
ТСКС-40/145/10-Х3:
Т — трехфазный;
С — естественное воздушное охлажление при открытом исполнении;
К — для КРУ;
С — специальный;
40 — типовая мощность, кВ·А;
145 — мощность при броске тока, кВ·А;
10 — класс напряжения обмотки ВН, кВ;
Х3 — климатическое исполнение (У, Т) и категория размещения по
ГОСТ 15150-69.
Трансформатор собственных нужд ТСКС-40/10/0,4(0,23), ТСКС 40 6/0,4(0,23)
ТСКС-40/145/10/0,4(0,23) Трансформатор сухой ТСКС 40 6/0,4(0,23)
Трансформатор сухой ТСКС-40/10 ТСКС-40/6 ТСКС-40/145/10 6/0,4 10/0,4
Трансформаторы сухозаряженные серии ТСКС 40/145 10/0,4 ТСКС 40/145 6/0,4
Трансформатор собственных нужд ТСКС-40/145/10-6(10)/0,4, ТСКС 40/145/10-10(6)/0,4 для ячеек КРУ. В наличии. Сертифицировано.
Трансформаторы трехфазные сухие специального назначения ТСКС-40/145/10/0,4 с естественным воздушным охлаждением типа ТСКС-40/145/10 предназначены
для питания собственных нужд шкафов КРУ.
Частота напряжения питающей сети 50 Гц, допускается работа при 60 Гц.
Структура условного обозначения
ТСКС-40/145/10-Х3:
Т — трехфазный;
С — естественное воздушное охлажление при открытом исполнении;
К — для КРУ;
С — специальный;
40 — типовая мощность, кВ·А;
145 — мощность при броске тока, кВ·А;
10 — класс напряжения обмотки ВН, кВ;
Х3 — климатическое исполнение (У, Т) и категория размещения по
ГОСТ 15150-69.
Трансформатор собственных нужд ТСКС-40/10/0,4(0,23), ТСКС 40 6/0,4(0,23)
ТСКС-40/145/10/0,4(0,23) Трансформатор сухой ТСКС 40 6/0,4(0,23)
Трансформатор сухой ТСКС-40/10 ТСКС-40/6 ТСКС-40/145/10 6/0,4 10/0,4
Трансформаторы сухозаряженные серии ТСКС 40/145 10/0,4 ТСКС 40/145 6/0,4
Трансформатор собственных нужд ТСКС-40/145/10-6(10)/0,4, ТСКС 40/145/10-10(6)/0,4 для ячеек КРУ. В наличии. Сертифицировано.
Трансформаторы трехфазные сухие специального назначения ТСКС-40/145/10/0,4 с естественным воздушным охлаждением типа ТСКС-40/145/10 предназначены
для питания собственных нужд шкафов КРУ. Трансформатор ТСКС-40/145/10/0,4 имеет высокую надежность не требуют затрат на обслуживание, экономичен и прст в эксплуатации.
Условия эксплуатации
Номинальные значения климатических факторов по ГОСТ 15150-69 и ГОСТ 15543.1-89. Высота над уровнем моря не более 1000 м. Работа трансформатора на высоте более 1000 м в каждом конкретном случае должна быть согласована с изготовителем трансформаторов. Верхнее значение рабочей температуры 40°С для исполнения У3 и 45°С…
Трансформатор ТСКС-40/145/10/0,4 имеет высокую надежность не требуют затрат на обслуживание, экономичен и прст в эксплуатации.
Условия эксплуатации
Номинальные значения климатических факторов по ГОСТ 15150-69 и ГОСТ 15543.1-89. Высота над уровнем моря не более 1000 м. Работа трансформатора на высоте более 1000 м в каждом конкретном случае должна быть согласована с изготовителем трансформаторов. Верхнее значение рабочей температуры 40°С для исполнения У3 и 45°С…
Брильц Сергей · Завод Электрон · Сегодня · Россия · Чувашская республика – Чувашия
ПРОДАМ: Трансформатор типа ТСКС
Трансформаторы типа ТСКС-25/145/10(6)/0,4(0,23) предназначены для питания собственных нужд шкафов КРУ класса напряжения 6 и 10 кВ, изготовляются для нужд народного хозяйства.
ТСКС-25/145/10(6)/0,4(0,23)-Х3:
Т – трехфазный;
С – естественное воздушное охлаждение при открытом исполнении;
К – для КРУ;
С – специальный;
25 – типовая мощность, кВ•А;
145 – мощность при броске тока, кВ•А;
10(6) – класс напряжения обмотки ВН, кВ;
0,4(0,23) – Напряжение вторичных цепей, кВ
Х3 – климатическое исполнение (У, Т) и категория размещения по
ГОСТ 15150-69.![]() Частота напряжения питающей сети 50 Гц, допускается работа при 60 Гц.
Типы обозначений:
Трансформатор собственных нужд ТСКС-25/10/0,4(0,23), ТСКС- 25/6/0,4(0,23)
ТСКС-25/145/10/0,4(0,23), ТСКС-25/145/6/0,4
Трансформатор сухой ТСКС-25/ 6/0,4(0,23)
Трансформатор сухой ТСКС-25/10 , ТСКС-25/6, ТСКС-25/145/10(6)/0,4(0,23)
Трансформаторы сухозаряженные серии ТСКС 25/145/10/0,4 или ТСКС 25/145/ 6/0,4
Трансформатор собственных нужд ТСКС-25/145/10(6)/0,4, ТСКС 25/145/10(6)/0,23 для ячеек КРУ.
Трансформатор ТСКС-25 имеет высокую надежность, не требуют затрат на обслуживание, экономичен и прост в эксплуатации.
Так же Вы можете приобрести ТСКС-10, ТСКС-16, ТСКС-40,
Минимальные сроки изготовления. Сертифицировано.
Частота напряжения питающей сети 50 Гц, допускается работа при 60 Гц.
Типы обозначений:
Трансформатор собственных нужд ТСКС-25/10/0,4(0,23), ТСКС- 25/6/0,4(0,23)
ТСКС-25/145/10/0,4(0,23), ТСКС-25/145/6/0,4
Трансформатор сухой ТСКС-25/ 6/0,4(0,23)
Трансформатор сухой ТСКС-25/10 , ТСКС-25/6, ТСКС-25/145/10(6)/0,4(0,23)
Трансформаторы сухозаряженные серии ТСКС 25/145/10/0,4 или ТСКС 25/145/ 6/0,4
Трансформатор собственных нужд ТСКС-25/145/10(6)/0,4, ТСКС 25/145/10(6)/0,23 для ячеек КРУ.
Трансформатор ТСКС-25 имеет высокую надежность, не требуют затрат на обслуживание, экономичен и прост в эксплуатации.
Так же Вы можете приобрести ТСКС-10, ТСКС-16, ТСКС-40,
Минимальные сроки изготовления. Сертифицировано.
Данилов Евгений · ЧебЭнерго · 30 сентября · Россия · Чувашская республика – Чувашия
ПРОДАМ: Трансформатор ТС, ТСЗ, ТСТ, ТСКС
Трансформатор ТС-10, ТСЗ-10, ТСТ-10, ТС-16, ТСТ-16, ТСЗ-16, ТС-25, ТСТ-25, ТСЗ-25, ТС-40, ТСЗ-40, ТСЗ-63, ТС-63, ТС-100, ТСЗ-100, ТС-160, ТСЗ-160, ТС-250, ТСЗ-250, ТС-250, ТСЗ-250, ТСКС-25, ТСКС-40. Трансформаторы сухие низковольтные, высоковольтные
Трансформатор ТСКС-25
Трансформатор ТСКС-40
Трансформатор ТС-10
Трансформатор ТСЗ-10
Трансформатор ТСТ-10
Трансформатор ТС-16
Трансформатор ТСТ-16
Трансформатор ТСЗ-16
Трансформатор ТС-25
Трансформатор ТСТ-25
Трансформатор ТСЗ-25
Трансформатор ТС-40
Трансформатор ТСЗ-40
Трансформатор ТСЗ-63
Трансформатор ТС-63
Трансформатор ТС-100
Трансформатор ТСЗ-100
Трансформатор ТС-160
Трансформатор ТСЗ-160
Трансформатор ТС-250
Трансформатор ТСЗ-250
Трансформатор ТС-250
Трансформатор ТСЗ-250
Чебоксарский
Завод “Электрон”
Трансформаторы сухие низковольтные, высоковольтные
Трансформатор ТСКС-25
Трансформатор ТСКС-40
Трансформатор ТС-10
Трансформатор ТСЗ-10
Трансформатор ТСТ-10
Трансформатор ТС-16
Трансформатор ТСТ-16
Трансформатор ТСЗ-16
Трансформатор ТС-25
Трансформатор ТСТ-25
Трансформатор ТСЗ-25
Трансформатор ТС-40
Трансформатор ТСЗ-40
Трансформатор ТСЗ-63
Трансформатор ТС-63
Трансформатор ТС-100
Трансформатор ТСЗ-100
Трансформатор ТС-160
Трансформатор ТСЗ-160
Трансформатор ТС-250
Трансформатор ТСЗ-250
Трансформатор ТС-250
Трансформатор ТСЗ-250
Чебоксарский
Завод “Электрон”
Брильц Сергей · Завод Электрон · Сегодня · Россия · Чувашская республика – Чувашия
Трансформатор ТСКС-40 / Товары и услуги / Energoboard
Этот товар или услуга была перенесена в архив.
15 февраля в 14:52
Код: 15703
Рубрика: Трансформаторное оборудование
Тип сделки: Продажа
Состояние: находящееся на складе
Обновлено: 15 февраля в 14:52
Создано: 4 декабря 2012 в 15:14
Количество: Не указано
Год изготовления: Не указан
Цена: Не указана
Описание
“Завод Силовой Электроаппаратуры” производит и поставляет трансформаторы собственных нужд серий ТСКС-40/145/10-10(6)/0,4, ТСКС 40/145/10-6(10)/0,23 ТСКС-25-6(10)/0,23, ТСКС-25-10(6)/0,4 для высоковольтных ячеек.
Вся продукция сертифицирована. Доставка в любой регион РФ.
Трансформаторы типа ТСКС-40/145/10(6)/0,4(0,23) трехфазные сухие специального назначения предназначены для питания собственных нужд шкафов КРУ класса напряжения 6 и 10 кВ, изготовляются для нужд народного хозяйства и для поставок на экспорт как комплектующие изделия. Частота напряжения питающей сети 50 Гц, допускается работа при 60 Гц.
Структура условного обозначения
ТСКС-40/145/10-Х3:
Т – трехфазный;
С – естественное воздушное охлажление при открытом исполнении;
К – для КРУ;
С – специальный;
40 – типовая мощность, кВ·А;
145 – мощность при броске тока, кВ·А;
10 – класс напряжения обмотки ВН, кВ;
Х3 – климатическое исполнение (У, Т) и категория размещения по
ГОСТ 15150-69.
Трансформатор собственных нужд ТСКС-40/10/0,4(0,23), ТСКС 40 6/0,4(0,23)
ТСКС-40/145/10/0,4(0,23) Трансформатор сухой ТСКС 40 6/0,4(0,23)
Трансформатор сухой ТСКС-40/10 ТСКС-40/6 ТСКС-40/145/10 6/0,4 10/0,4
Трансформаторы сухозаряженные серии ТСКС 40/145 10/0,4 ТСКС 40/145 6/0,4
Трансформатор собственных нужд ТСКС-40/145/10-6(10)/0,4, ТСКС 40/145/10-10(6)/0,4 для ячеек КРУ. В наличии. Сертифицировано.
В наличии. Сертифицировано.
Трансформаторы трехфазные сухие специального назначения ТСКС-40/145/10/0,4 с естественным воздушным охлаждением типа ТСКС-40/145/10 предназначены
для питания собственных нужд шкафов КРУ.
Трансформатор ТСКС-40/145/10/0,4 имеет высокую надежность не требуют затрат на обслуживание, экономичен и прст в эксплуатации.
Условия эксплуатации
Номинальные значения климатических факторов по ГОСТ 15150-69 и ГОСТ 15543.1-89. Высота над уровнем моря не более 1000 м. Работа трансформатора на высоте более 1000 м в каждом конкретном случае должна быть согласована с изготовителем трансформаторов. Верхнее значение рабочей температуры 40°С для исполнения У3 и 45°С для исполнения Т3. Окружающая среда невзрывоопасная, не содержащая токопроводимой пыли, агрессивных газов и паров в концентрациях, разрушающих металлы и изоляцию. Требования техники безопасности по ГОСТ
Технические характеристики
Номинальные напряжения ВН – 6; 10; 10,5 кВ, НН – 0,23; 0,4 кВ. По согласованию между потребителем и изготовителем допускаются напряжения со стороны ВН – 6,3; 11; 11,5; 6,9 кВ, со стороны НН – 0,24; 0,415; 0,44 кВ. Схема и группа соединения Y/Yн-0, в обоснованных случаях по согласованию сторон допускаются схема и группа соединения D/Yн-11 и напряжения, отличные от вышеуказанных. Трансформатор должен обеспечивать питание трехфазной однополупериодной схемы выпрямителя с графиком нагрузки, приведенным на рис. 1. Мощность трансформатора при броске тока 145 кВ·А, напряжение КЗ 5,7%. Длительная нагрузка, включенная до выпрямителя, не превышает 25 кВ·А.
По согласованию между потребителем и изготовителем допускаются напряжения со стороны ВН – 6,3; 11; 11,5; 6,9 кВ, со стороны НН – 0,24; 0,415; 0,44 кВ. Схема и группа соединения Y/Yн-0, в обоснованных случаях по согласованию сторон допускаются схема и группа соединения D/Yн-11 и напряжения, отличные от вышеуказанных. Трансформатор должен обеспечивать питание трехфазной однополупериодной схемы выпрямителя с графиком нагрузки, приведенным на рис. 1. Мощность трансформатора при броске тока 145 кВ·А, напряжение КЗ 5,7%. Длительная нагрузка, включенная до выпрямителя, не превышает 25 кВ·А.
Поставка в любой регион России. Цены от производителя. Гарантия завода-производителя.
Контактная информация
Профиль пользователя: Смотреть профиль
Все товары и услуги пользователя: Найти
Название предприятия: Завод СЭА
Контактное лицо: Менеджер
Город: Чебоксары
Код города: 8352
Телефон: 23-07-07
2036
Закладки
Ввод НН, ввод ВН силового трансформатора
Сегодня, в 10:53 1411
Ремонтный ЭНЕРГОКомплект трансформатора 250 /10(6) ТМ, ТМГ, ТМФ, ТМЭ
Сегодня, в 10:53 1188
Ремонтный ЭНЕРГОКомплект РТИ для трансформатора ТМ-630, ТМГ-630, ТМЗ-630, ТМФ-630 /10(6) кВа
Сегодня, в 10:52 1091
Ремкомплект для трансформатора 25 – 2500 кВА ТМ, ТМГ, ТМЗ
Сегодня, в 10:52 1177
Ремонтный ЭНЕРГОКомплект РТИ для трансформатора ТМ-400, ТМГ-400, ТМЗ-400, ТМФ-400 /10(6) кВа
Сегодня, в 10:51 461
ЗАЖИМЫ АППАРАТНЫЕ, контактные (плашечные) на трансформатор 160, 250, 400, 630, 1000, 1600, 2000 кВА
Сегодня, в 10:51 1155
Зажим контактный НН на трансформатор 1000 кВа к М33х2. 0, М33х1.5 к ТМГ, ТМЗ, ТМ
0, М33х1.5 к ТМГ, ТМЗ, ТМ
Сегодня, в 10:51 262
Контактные зажимы для трансформаторов 160 – 2500 кВА
Сегодня, в 10:50 807
ЗАЖИМ контактный М20х2.5 или М20х1.5 на трансформатор 400 кВа
Сегодня, в 10:50 259
Зажим контактный ВН и НН к шпильке М12 трансформатора
Сегодня, в 10:49 319
Трансформатор ОСХ-ПУ-0.![]() 315-У2
315-У2
16 апреля в 12:47 4172
Преобразователи тиристорные экскаваторные моноблочные (ПТЭМ)
29 июня в 16:10 2410
Трансформатор тока ТЗЛМ-1 У3 0,66кВ Деам 70,ТЗЛМ- У3 0,66кВ Деам 70.
18 июля в 18:29 2141
Трансформатор тока ТОЛ-10 аналог трансформатора ТЛО-10, ТЛК-10,ТОЛ-СЭЩ-10
14 сентября в 15:34 2064
Трансформаторы ТМ
3 октября в 11:33 1940
Трансформатор тока ТВЛМ-10 аналог ТВК-10 Самара
27 июня в 16:36 1895
Трансформаторы тока ТОЛ-СЭЩ,ТОЛ-10-1-1,ТОЛ-10-1-2, ТОЛ-СВЭЛ
14 сентября в 15:40 1824
Трансформаторы ТРДН, ТДНТ, ТДН, ТМТН, ТМН, ТДНС
3 октября в 11:33 1723
Сухие трансформаторы
3 октября в 11:32 1680
Трансформатор тока ТПЛ-10М,ТПЛ-10С,ТЛП-10,ТОЛ-10,ТВЛМ-10
5 октября в 12:45 1665
Сотрудники ЗАО «ЗЭТО» в числе «Лучших рационализаторов и изобретателей Псковской области»
Вчера, в 15:23 34
Специалисты «Удмуртэнерго» ведут работу по выявлению сайтов-мошенников
Вчера, в 10:55 38
Филиал «Калугаэнерго» продолжает работу по снижению дебиторской задолженности
Вчера, в 10:39 41
Представители ПАО «Русгидро» ознакомились с производством великолукского завода
6 октября в 16:03 49
«Россети Центр» и «Россети Центр и Приволжье» стали отраслевыми лидерами в ESG-рейтингах AK&M по итогам 2021 года
5 октября в 18:54 46
ТОЛЬКО В ОКТЯБРЕ при покупке новогоднего освещения – МОНТАЖ В ПОДАРОК!
5 октября в 17:26 42
Расчет стоимости новогоднего освещения по фото дома – бесплатно
5 октября в 17:24 46
Удмуртэнерго повышает надежность электроснабжения потребителей в зоне ответственности Увинского РЭС
5 октября в 15:50 48
«ЗЭТО» на 20-ой Казахстанской международной выставке Pоwerexpo Almaty 2022
5 октября в 12:54 54
Автоматизация теплосетей Ульяновска: очередной этап
4 октября в 23:00 40
товары и услуги Абсорбент Л
277
Сегодня, в 11:21
товары и услуги Трансформатор ТСКС-40
2036
Сегодня, в 11:21
пользователи Профиль пользователя ID16276
304
Сегодня, в 11:21
пользователи Профиль пользователя ID16236
274
Сегодня, в 11:21
товары и услуги
КСО 393. Изготовим камеры КСО-298, КСО-285, КСО-392, КСО366, КСО 386, КСО 272, КСО 392 в короткие сроки по низким ценам!
Изготовим камеры КСО-298, КСО-285, КСО-392, КСО366, КСО 386, КСО 272, КСО 392 в короткие сроки по низким ценам!
630
Сегодня, в 11:21
пользователи Профиль пользователя ID16066
308
Сегодня, в 11:21
товары и услуги Трансформатор тока ТПЛ – 10 75/5 (0,5s)
603
Сегодня, в 11:21
пользователи Профиль пользователя ID15736
334
Сегодня, в 11:21
товары и услуги РемКомплект для трансформатора на 1600 кВа к ТМФ
42
Сегодня, в 11:21
пользователи Профиль пользователя ID21195
424
Сегодня, в 11:21
публикации Новая газотурбинная ТЭЦ в Касимове выдаст в энергосистему Рязанской области более 18 МВт мощности
246996
Сегодня, в 11:04
справочник Инструкция по монтажу контактных соединений шин между собой и с выводами электротехнических устройств
72505
Сегодня, в 10:46
справочник Измерение сопротивления обмоток постоянному току
60194
Сегодня, в 10:57
публикации Выключатель элегазовый типа ВГБ-35, ВГБЭ-35, ВГБЭП-35
52268
Сегодня, в 07:36
справочник Инструкция по осмотру РП, ТП, КТП, МТП
48632
Сегодня, в 10:28
пользователи Профиль пользователя ID7667
46319
Сегодня, в 07:53
справочник Эксплуатация, хранение и транспортировка кислородных баллонов
45357
Сегодня, в 08:10
справочник Методика измерения сопротивления изоляции
43184
Сегодня, в 08:54
публикации Выключатели нагрузки на напряжение 6, 10 кВ
42678
Сегодня, в 07:41
справочник Положение об оперативно-выездной бригаде района электрических сетей
40477
Сегодня, в 07:33
Информация обновлена сегодня, в 11:20
Евгений 194 Объявления
Сергей 134 Объявления
Владимир 111 Объявлений
522889 87 Объявлений
Николай 69 Объявлений
peremotka-patriot 52 Объявления
find2pm 46 Объявлений
Анатолий 44 Объявления
Юрий 32 Объявления
Михаил 31 Объявление
Информация обновлена сегодня, в 11:20
Елена Владимировна 1064 Объявления
Ирина 972 Объявления
Евгений 684 Объявления
Евгений 426 Объявлений
koemz@mail.![]() ru
350 Объявлений
ru
350 Объявлений
Сергей 267 Объявлений
522889 136 Объявлений
Сергей 134 Объявления
Владимир 111 Объявлений
Артем 109 Объявлений
Информация обновлена сегодня, в 11:20
Трансформаторы сухие, высоковольтные – производство, поставки
| Телефон +7(8352) 709558), +7 (927)846-36-11 | ||||
| Viber | ||||
| E-mail:transformator21@yandex. | ||||
| Время работы: пон-пят. 8:00-17:00 | ||||
| Производственная база: Чувашская Республика, г.Чебоксары, проезд Лапсарский д.15А. | ||||
Продукция
Мы производим трансформаторы с 2010 года.
На сайте представлены основные виды выпускаемых сухих трансформаторов.
Можно заказать продукцию практически с любыми параметрами которые вам необходимы.
Трансформаторы ТСКС
Основное применение: электроустановки, служащие для приёма и распределения электрической энергии – Комплектные распределительные устройства (КРУ).
Трансформаторы низковольтные
Трансформаторы ТС; ТСЗ; ТСТ; ТПЗ; ОС; ОСЗ; ОСУ силовые сухие низковольтные. Предназначены для преобразования электроэнергии у потребителей.
Реакторы СРТС
Реакторы СРТС, ТРОС, РТСТ, СРОС, СРОСЗ, ФРОСП используются с целью уменьшения содержания высших гармоник (пульсаций) в выпрямленном токе.
Магнитопроводы трансформаторов
Изготавливаем магнитопроводы трансформаторов (остовы) из электротехнической анизотропной стали по Вашим чертежам
Контактные кольца к турбогенераторам
Замена изношенных колец турбогенераторов. Соответствуют требованиям чертежей изготовителей турбогенераторов и имеют сертификаты качества.
Плоскошлифовальные работы
Оказываем услуги по шлифовке призм, поверочных плит, производственных ножей, матриц на плоскошлифовальном станке алмазными или абразивными кругами.
Фотогалерея
Трансформаторы ТСКС силовые сухие высоковольтные
Основная сфера применения: электроустановки, служащие для приёма и распределения электрической энергии – Комплектные распределительные устройства (КРУ).
Т – трехфазный;
С – естественное воздушное охлажление при открытом исполнении;
К – для КРУ;
С – специальный.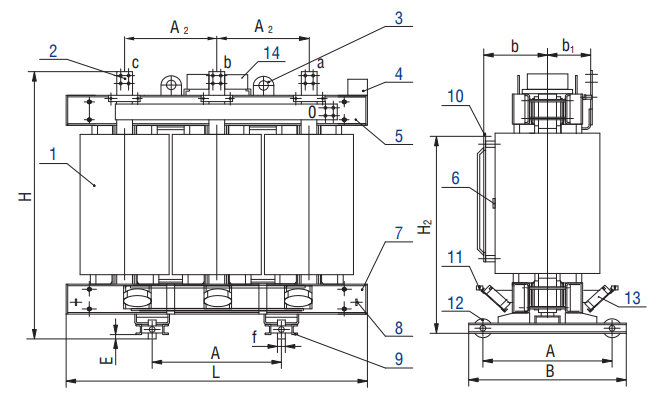
Производимые нами трансформаторы силовые типа ТСКС мощностью 10; 16; 25 и 40 кВА предназначены для собственных нужд шкафов (ячеек) КРУ класса напряжения 6 и 10 кВ.
Эти изделия очень надёжны и имеют высокие показатели пожаробезопасности, так как детали обмотки и изоляция изготовлены из материалов, которые практически не горят.
Трехфазные сухие трансформаторы специального назначения типа ТСКС не требовательны к условиям, очень просты в эксплуатации и экономичны.
Устанавливаются в помещениях с естественной вентиляцией. Лучше ставить в отдельный шкаф в стенках которого нужно предусмотреть ответстия для естественной вентиляции и охлаждения трансформатора во время работы.
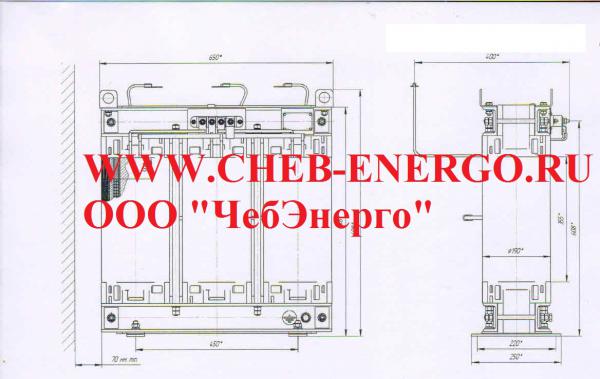
Технические характеристики высоковольтных трансформаторов ТСКС 10, ТСКС 16, ТСКС 25, ТСКС 40
Тип трансформатора | Мощность, кВА | Номинальное напряжение, кВ | Габаритные размеры, мм, не более (длина, ширина, высота) | |||
ВН | НН | L | B | Н | ||
ТСКС – 10,0 | 10 | 6; 6,3; 10; 10,5 | 0,23; 0,4 | 610 | 260 | 635 |
ТСКС – 16,0 | 16 | 610 | 260 | 635 | ||
ТСКС – 25,0 | 25 | 640 | 280 | 690 | ||
ТСКС – 40,0 | 40 | 700 | 305 | 750 | ||
Преимущества сухих трансформаторов по сравнению с традиционными масляными трансформаторами
- Минимальный риск возгорания
- Отсутствие охлаждающей жидкости
- Нет необходимости в обслуживании
- Низкие эксплуатационные затраты
- Неограниченные возможности по установке
- Увеличение производительности
- Высокая устойчивость к кратковременным перегрузкам
- Высокая надежность
* Возможно изготовление трансформатора с индивидуальными характеристиками по мощности и выходными характеристиками напряжения.
Гарантии и надёжность
- Не менее 30000 часов безотказной работы
- Не менее 12 лет трансформатор работает без капремонта
- Не менее 25 лет срок службы нашего изделия
- 3 года – гарантийный срок эксплуатации
Трансформаторы ТСКС сертифицированы
и изготавливаются в соответствии с ТУ 3411-001-65661497-2010.
Компания “ЭЛЬМА” с 2010 года производит сухие трансформаторы различных типов низкого и высокого напряжения.
Как точно настроить модель для общих последующих задач
Это руководство покажет вам, как точно настроить модели 🤗 Трансформаторов для общих последующих задач. Вы будете использовать 🤗 Библиотека наборов данных для быстрой загрузки и предварительной обработки наборов данных, подготовки их к обучению с помощью PyTorch и ТензорФлоу.
Прежде чем начать, убедитесь, что у вас установлена библиотека 🤗 Наборы данных. Более подробные инструкции по установке см.
обратитесь к 🤗 странице установки наборов данных. Все из
примеры в этом руководстве будут использовать наборы данных 🤗 для загрузки и предварительной обработки набора данных.
Все из
примеры в этом руководстве будут использовать наборы данных 🤗 для загрузки и предварительной обработки набора данных.
Наборы данных установки pip
Узнайте, как настроить модель для:
- seq_imdb
- ток_нер
- qa_squad
Классификация последовательности с обзорами IMDb
Классификация последовательностей относится к задаче классификации последовательностей текста в соответствии с заданным количеством классов. В этом примере узнайте, как точно настроить модель в наборе данных IMDb, чтобы определить положительный отзыв или отрицательный.
Более подробный пример тонкой настройки модели для классификации текста см. в соответствующем Блокнот PyTorch или блокнот TensorFlow.
Загрузить набор данных IMDb
Библиотека наборов данных 🤗 упрощает загрузку набора данных:
из наборов данных import load_dataset
imdb = load_dataset("imdb") Это загружает объект DatasetDict , который вы можете проиндексировать для просмотра примера:
imdb["train"][0]
{
"этикетка": 1,
"text": "Школа Бромвеля – это мультяшная комедия. Она показывалась одновременно с некоторыми другими программами о школьной жизни, такими как \"Учителя\". Мои 35 лет преподавательской деятельности наводят меня на мысль, что сатира школы Бромвеля – гораздо ближе к реальности, чем "Учителя". Борьба за финансовое выживание, проницательные ученики, которые видят сквозь жалкую помпезность своих учителей, мелочность всей ситуации - все это напоминает мне школы, которые я знал, и их учеников. Когда я увидел эпизод, в котором ученик несколько раз пытался сжечь школу, я сразу вспомнил ......... в .......... Высшей Классическая строчка: ИНСПЕКТОР: Я Я здесь, чтобы уволить одного из ваших учителей. СТУДЕНТ: Добро пожаловать в школу Бромвелл. Я ожидаю, что многие взрослые моего возраста сочтут школу Бромвелл надуманной. Как жаль, что это не так!",
}
Она показывалась одновременно с некоторыми другими программами о школьной жизни, такими как \"Учителя\". Мои 35 лет преподавательской деятельности наводят меня на мысль, что сатира школы Бромвеля – гораздо ближе к реальности, чем "Учителя". Борьба за финансовое выживание, проницательные ученики, которые видят сквозь жалкую помпезность своих учителей, мелочность всей ситуации - все это напоминает мне школы, которые я знал, и их учеников. Когда я увидел эпизод, в котором ученик несколько раз пытался сжечь школу, я сразу вспомнил ......... в .......... Высшей Классическая строчка: ИНСПЕКТОР: Я Я здесь, чтобы уволить одного из ваших учителей. СТУДЕНТ: Добро пожаловать в школу Бромвелл. Я ожидаю, что многие взрослые моего возраста сочтут школу Бромвелл надуманной. Как жаль, что это не так!",
} Предварительная обработка
Следующим шагом является преобразование текста в удобочитаемый формат с помощью модели. Важно загружать один и тот же токенизатор
модель была обучена для обеспечения надлежащего токенизации слов.![]() Загрузите токенизатор DistilBERT с помощью
AutoTokenizer, потому что в конечном итоге мы будем обучать классификатор с использованием предварительно обученной модели DistilBERT:
Загрузите токенизатор DistilBERT с помощью
AutoTokenizer, потому что в конечном итоге мы будем обучать классификатор с использованием предварительно обученной модели DistilBERT:
из трансформаторов import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased") Теперь, когда вы создали экземпляр токенизатора, создайте функцию, которая будет токенизировать текст. Вы также должны обрезать более длинные последовательности в тексте должны быть не длиннее максимальной входной длины модели:
функция предобработки по определению (примеры):
return tokenizer(examples["text"], truncation=True) Используйте функцию 🤗 Datasets map , чтобы применить функцию предварительной обработки ко всему набору данных. Вы также можете установить batched = True , чтобы применить функцию предварительной обработки сразу к нескольким элементам набора данных для более быстрого
preprocessing:
tokenized_imdb = imdb.map(preprocess_function, batched=True)
Наконец, дополните текст, чтобы он был одинаковой длины. Хотя можно дополнить текст в токенизатор функция
установив padding=True , более эффективно дополнять текст только до длины самого длинного элемента в его
партия. Это известно как динамическое заполнение . Вы можете сделать это с помощью функции DataCollatorWithPadding :
из импорта трансформаторов DataCollatorWithPadding data_collator = DataCollatorWithPadding (токенизатор = токенизатор)
Точная настройка с помощью Trainer API
Теперь загрузите свою модель с классом AutoModelForSequenceClassification вместе с количеством ожидаемых меток:
из импорта трансформаторов AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2) На этом этапе осталось только три шага:
- Определите гиперпараметры обучения в TrainingArguments.

- Передайте обучающие аргументы тренеру вместе с моделью, набором данных, токенизатором и средством сопоставления данных.
- Вызовите
Trainer.train()для точной настройки вашей модели.
импорт трансформаторов TrainingArguments, Trainer
training_args = Аргументы обучения (
output_dir="./результаты",
скорость_обучения=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=5,
вес_распада = 0,01,
)
тренер = тренер(
модель=модель,
аргументы = обучающие_аргументы,
train_dataset = tokenized_imdb["поезд"],
eval_dataset=tokenized_imdb["тест"],
токенизатор = токенизатор,
data_collator=data_collator,
)
тренер.поезд() Точная настройка с TensorFlow
Тонкая настройка с помощью TensorFlow так же проста, за исключением нескольких отличий.
Начните с объединения обработанных примеров вместе с динамическим дополнением с помощью функции DataCollatorWithPadding.![]() Убедитесь, что вы установили
Убедитесь, что вы установили return_tensor="tf" для возврата выходов tf.Tensor вместо тензоров PyTorch!
из импорта трансформаторов DataCollatorWithPadding data_collator = DataCollatorWithPadding(tokenizer, return_tensor="tf")
Затем преобразуйте наборы данных в Формат tf.data.Dataset с to_tf_dataset . Укажите входы и метки в столбец аргумент:
tf_train_dataset = tokenized_imdb["train"].to_tf_dataset(
столбцы = ["внимание_маска", "входные_идентификаторы", "метка"],
перемешать = Верно,
размер партии = 16,
collate_fn=data_collator,
)
tf_validation_dataset = tokenized_imdb["поезд"].to_tf_dataset(
столбцы = ["внимание_маска", "входные_идентификаторы", "метка"],
перетасовать = Ложь,
размер партии = 16,
collate_fn=data_collator,
) Настройте функцию оптимизатора, график скорости обучения и некоторые гиперпараметры обучения:
из импорта трансформаторов create_optimizer импортировать тензорный поток как tf размер_пакета = 16 число_эпох = 5 batches_per_epoch = len(tokenized_imdb["train"]) // размер_пакета total_train_steps = int (batches_per_epoch * num_epochs) оптимизатор, расписание = create_optimizer(init_lr=2e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
Загрузите вашу модель с классом TFAutoModelForSequenceClassification вместе с количеством ожидаемых меток:
из импорта трансформаторов TFAutoModelForSequenceClassification model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
Скомпилируйте модель:
импортируйте тензорный поток как tf model.compile(optimizer=optimizer)
Наконец, настройте модель, вызвав model.fit :
model.fit(
tf_train_set,
validation_data=tf_validation_set,
эпохи = num_train_epochs,
) Классификация токенов с новыми объектами WNUT
Классификация токенов относится к задаче классификации отдельных токенов в предложении. Один из самых распространенных токенов Задачами классификации является распознавание именованных объектов (NER). NER пытается найти метку для каждой сущности в предложении, например, лицо, местоположение или организация. В этом примере вы узнаете, как точно настроить модель в наборе данных WNUT 17 для обнаружения новых объектов.
Более подробный пример тонкой настройки модели для классификации токенов см. в соответствующем Блокнот PyTorch или блокнот TensorFlow.
Загрузить набор данных WNUT 17
Загрузите набор данных WNUT 17 из 🤗 библиотеки наборов данных:
>>> from datasets import load_dataset
>>> wnut = load_dataset("wnut_17") Беглый взгляд на набор данных показывает метки, связанные с каждым словом в предложении:
>>> wnut["train"][0]
{'идентификатор': '0',
'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 8, 8, 0, 7, 0, 0, 0, 0 , 0, 0, 0, 0],
'tokens': ['@paulwalk', 'Это', "s", 'the', 'вид', 'откуда', 'где', 'я', 'м', 'живу', 'для ', 'две', 'недели', '. ', 'Империя', 'Штат', 'Здание', '=', 'ESB', '.', 'Красиво', 'плохо', 'шторм', 'здесь', 'последний', 'вечер', '.']
}
', 'Империя', 'Штат', 'Здание', '=', 'ESB', '.', 'Красиво', 'плохо', 'шторм', 'здесь', 'последний', 'вечер', '.']
} Просмотр конкретных тегов NER по:
>>> label_list = wnut["train"].features[f"ner_tags"].feature.names
>>> список_меток
[
"О",
"Б-корпорация",
"Я-корпорация",
"Б-творчество",
«Я-творчество-работа»,
"Б-группа",
«Я-группа»,
"Б-локация",
«Я-локация»,
"Б-человек",
«Я-человек»,
"В-продукт",
«Я-продукт»,
] Буква предшествует каждому тегу NER, что может означать:
-
B-указывает начало объекта. -
I-указывает, что токен содержится внутри одного и того же объекта (например, токенStateявляется частью объекта, подобногоЭмпайр Стейт Билдинг). -
0указывает, что токен не соответствует ни одному объекту.
Предварительная обработка
Теперь вам нужно токенизировать текст. Загрузите токенизатор DistilBERT с помощью AutoTokenizer:
из импорта трансформаторов AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
Поскольку ввод уже разделен на слова, установите is_split_into_words=True , чтобы разбить слова на
подслова:
>>> tokenized_input = tokenizer(example["tokens"], is_split_into_words=True) >>> токены = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"]) >>> токены ['[CLS]', '@', 'пол', '##прогулка', 'это', ''', 's', 'the', 'вид', 'откуда', 'где', ' я', "'", "м", "жизнь", "на", "две", "недели", ".", "империя", "государство", "здание", "=", "эс" , '##b', '.', 'красиво', 'плохо', 'шторм', 'здесь', 'последний', 'вечер', '.', '[СЕНТЯБРЬ]']
Добавление специальных токенов [CLS] и [SEP] и токенизация подслов создает несоответствие между
ввод и метки. Выровняйте метки и токены следующим образом:
- Сопоставление всех токенов с соответствующими им словами с помощью метода
word_ids. - Назначение метки
-100специальным токенам[CLS]и «[SEP]“`, поэтому функция потери PyTorch игнорирует их.
- Маркировка только первой лексемы данного слова. Назначить
-100к другим субтокенам того же слова.
Вот как вы можете создать функцию, которая будет перестраивать метки и токены:
def tokenize_and_align_labels(примеры):
tokenized_inputs = tokenizer (примеры ["токены"], truncation = True, is_split_into_words = True)
метки = []
для i метка в перечислении (примеры [f"ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i) # Привязать токены к соответствующему слову.
предыдущее_слово_idx = Нет
label_ids = []
для word_idx в word_ids: # Установите специальные токены на -100.
если word_idx равен None:
label_ids.append(-100)
elif word_idx != previous_word_idx: # Пометить только первый токен данного слова.
label_ids.append (метка [word_idx])
еще:
label_ids.append(-100)
предыдущее_слово_idx = слово_idx
labels. append(label_ids)
tokenized_inputs["метки"] = метки
вернуть tokenized_inputs
append(label_ids)
tokenized_inputs["метки"] = метки
вернуть tokenized_inputs Теперь разметьте и выровняйте метки по всему набору данных с помощью 🤗 Наборы данных map function:
tokenized_wnut = wnut.map(tokenize_and_align_labels, batched=True)
Наконец, заполните текст и метки, чтобы они были одинаковой длины :
из импорта трансформаторов DataCollatorForTokenClassification data_collator = DataCollatorForTokenClassification (токенизатор)
Точная настройка с помощью Trainer API
Загрузите модель с классом AutoModelForTokenClassification вместе с количеством ожидаемых меток:
из импорта трансформаторов AutoModelForTokenClassification, TrainingArguments, Trainer
model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased", num_labels=len(label_list)) Соберите аргументы обучения в TrainingArguments:
training_args = TrainingArguments(
output_dir="./результаты",
оценка_стратегия="эпоха",
скорость_обучения=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
вес_распада = 0,01,
) Соберите свою модель, аргументы обучения, набор данных, средство сопоставления данных и токенизатор в Trainer:
Trainer = Trainer(
модель=модель,
аргументы = обучающие_аргументы,
train_dataset = tokenized_wnut["поезд"],
eval_dataset=tokenized_wnut["тест"],
data_collator=data_collator,
токенизатор = токенизатор,
) Точная настройка вашей модели:
Trainer.train()
Точная настройка с TensorFlow
Объедините ваши примеры вместе и дополните текст и метки, чтобы они были одинаковой длины:
из импорта трансформаторов DataCollatorForTokenClassification data_collator = DataCollatorForTokenClassification(tokenizer, return_tensors="tf")
Преобразуйте свои наборы данных в формат tf.data.Dataset с to_tf_dataset :
tf_train_set = tokenized_wnut["train"].setto_tf_data
столбцы = ["внимание_маска", "входные_идентификаторы", "метки"],
перемешать = Верно,
размер партии = 16,
collate_fn=data_collator,
)
tf_validation_set = tokenized_wnut["проверка"].to_tf_dataset(
столбцы = ["внимание_маска", "входные_идентификаторы", "метки"],
перетасовать = Ложь,
размер партии = 16,
collate_fn=data_collator,
) Загрузите модель с классом TFAutoModelForTokenClassification вместе с количеством ожидаемых меток:
из трансформаторов import TFAutoModelForTokenClassification model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased", num_labels=len(label_list))
Настройте функцию оптимизатора, график скорости обучения и некоторые гиперпараметры обучения:
from transforms import create_optimizer
размер_пакета = 16
num_train_epochs = 3
num_train_steps = (len(tokenized_datasets["train"]) // размер пакета) * num_train_epochs
оптимизатор, lr_schedule = create_optimizer(
init_lr=2e-5,
num_train_steps=num_train_steps,
weight_decay_rate = 0,01,
num_warmup_steps=0,
) Скомпилируйте модель:
импортируйте тензорный поток как tf model.compile(optimizer=optimizer)
Позвоните по номеру model.fit для точной настройки вашей модели:
model.fit(
tf_train_set,
validation_data=tf_validation_set,
эпохи = num_train_epochs,
) Ответы на вопросы с SQuAD
Существует множество типов заданий на ответы на вопросы (QA). Извлекающий контроль качества фокусируется на определении ответа из текста. задан вопрос. В этом примере вы узнаете, как точно настроить модель в наборе данных SQuAD.
задан вопрос. В этом примере вы узнаете, как точно настроить модель в наборе данных SQuAD.
Более подробный пример тонкой настройки модели для ответов на вопросы см. в соответствующем Блокнот PyTorch или блокнот TensorFlow.
Загрузить набор данных SQuAD
Загрузите набор данных SQuAD из 🤗 библиотеки наборов данных:
из наборов данных import load_dataset
отряд = load_dataset("отряд") Взгляните на пример из набора данных:
>>> отряд["поезд"][0]
{'answers': {'answer_start': [515], 'text': ['Святая Бернадетта Субиру']},
«контекст»: «Архитектурно школа имеет католический характер. На золотом куполе Главного здания находится золотая статуя Девы Марии. Непосредственно перед главным зданием и лицом к нему находится медная статуя Христа с поднятыми руками с надписью «Venite Ad Me Omnes». Рядом с Главным зданием находится Базилика Святого Сердца. Сразу за базиликой находится Грот, место молитвы и размышлений Марии. Это копия грота в Лурде, Франция, где, по общему мнению, Дева Мария явилась святой Бернадетте Субиру в 1858 году. простая современная каменная статуя Марии.',
'идентификатор': '5733be284776f41
простая современная каменная статуя Марии.',
'идентификатор': '5733be284776f411182',
«вопрос»: «Кому якобы явилась Дева Мария в 1858 году в Лурде, Франция?»,
'title': 'University_of_Notre_Dame'
}
Предварительная обработка
Загрузите токенизатор DistilBERT с помощью AutoTokenizer:
из импорта преобразователей AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased") При предварительной обработке текста для ответа на вопрос необходимо учитывать несколько моментов:
- Некоторые примеры в наборе данных могут иметь очень длинный
контекст, который превышает максимальную длину входных данных модели. Ты можно справиться с этим, обрезав контекстtruncation="only_second". - Далее вам нужно сопоставить начальную и конечную позиции ответа с исходным контекстом. Установлен
return_offset_mapping=Trueдля обработки этого. - Имея в руках сопоставление, вы можете найти начальный и конечный маркеры ответа.
 Используйте метод
Используйте метод sequence_idsдля найти, какая часть смещения соответствует вопросу, а какая часть смещения соответствует контексту.
Соберите все в функции предварительной обработки, как показано ниже:
def preprocess_function(примеры):
вопросы = [q.strip() для q в примерах["вопрос"]]
входы = токенизатор(
вопросы,
примеры["контекст"],
максимальная_длина=384,
усечение = "только_секунда",
return_offsets_mapping = Верно,
отступ = «максимальная_длина»,
)
offset_mapping = inputs.pop("offset_mapping")
ответы = примеры["ответы"]
начальные_позиции = []
конечные_позиции = []
для i смещение в перечислении (offset_mapping):
ответ = ответы [я]
start_char = ответ["answer_start"][0]
end_char = ответ["answer_start"][0] + len(ответ["текст"][0])
sequence_ids = inputs.sequence_ids(i)
# Находим начало и конец контекста
идентификатор = 0
в то время как sequence_ids[idx] != 1:
идентификатор += 1
context_start = IDX
в то время как sequence_ids[idx] == 1:
идентификатор += 1
context_end = IDX-1
# Если ответ не полностью в контексте, пометьте его (0, 0)
если offset[context_start][0] > end_char или offset[context_end][1] < start_char:
start_positions. append(0)
end_positions.append(0)
еще:
# В противном случае это начальная и конечная позиции токена
idx = контекст_начало
в то время как idx <= context_end и offset[idx][0] <= start_char:
идентификатор += 1
start_positions.append (idx - 1)
idx = контекст_конец
в то время как idx >= context_start и offset[idx][1] >= end_char:
идентификатор -= 1
end_positions.append (idx + 1)
inputs["start_positions"] = start_positions
входы["конечные_позиции"] = конечные_позиции
обратные входы
append(0)
end_positions.append(0)
еще:
# В противном случае это начальная и конечная позиции токена
idx = контекст_начало
в то время как idx <= context_end и offset[idx][0] <= start_char:
идентификатор += 1
start_positions.append (idx - 1)
idx = контекст_конец
в то время как idx >= context_start и offset[idx][1] >= end_char:
идентификатор -= 1
end_positions.append (idx + 1)
inputs["start_positions"] = start_positions
входы["конечные_позиции"] = конечные_позиции
обратные входы Применить функцию предварительной обработки ко всему набору данных с помощью 🤗 Наборы данных карта функция:
tokenized_squad = отряд.карта (предварительная_функция, пакетная = True, remove_columns=squad["train"].column_names)
Объединить обработанные примеры вместе :
из импорта трансформаторов default_data_collator data_collator = default_data_collator
Точная настройка с помощью Trainer API
Загрузите модель с классом AutoModelForQuestionAnswering:
из импорта трансформаторов AutoModelForQuestionAnswering, TrainingArguments, Trainer model = AutoModelForQuestionAnswering.from_pretrained("distilbert-base-uncased")
Соберите аргументы обучения в TrainingArguments:
training_args = TrainingArguments(
output_dir="./результаты",
оценка_стратегия="эпоха",
скорость_обучения=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
вес_распада = 0,01,
) Соберите свою модель, аргументы обучения, набор данных, средство сопоставления данных и токенизатор в Trainer:
Trainer = Trainer(
модель=модель,
аргументы = обучающие_аргументы,
train_dataset = tokenized_squad["поезд"],
eval_dataset=tokenized_squad["проверка"],
data_collator=data_collator,
токенизатор = токенизатор,
) Точная настройка вашей модели:
Trainer.train()
Точная настройка с TensorFlow
Объедините обработанные примеры вместе с подборщиком данных TensorFlow по умолчанию:
из transforms.data.data_collator импортировать tf_default_collator data_collator = tf_default_collator
Преобразуйте наборы данных в формат tf. с помощью функции ![]() data.Dataset
data.Dataset to_tf_dataset :
tf_train_set = tokenized_squad["train"].to_tf_dataset(
столбцы = ["внимание_маска", "входные_идентификаторы", "начальные_позиции", "конечные_позиции"],
dummy_labels = Верно,
перемешать = Верно,
размер партии = 16,
collate_fn=data_collator,
)
tf_validation_set = tokenized_squad["проверка"].to_tf_dataset(
столбцы = ["внимание_маска", "входные_идентификаторы", "начальные_позиции", "конечные_позиции"],
dummy_labels = Верно,
перетасовать = Ложь,
размер партии = 16,
collate_fn=data_collator,
) Настройте функцию оптимизатора, график скорости обучения и некоторые гиперпараметры обучения:
из импорта трансформаторов create_optimizer
размер_пакета = 16
число_эпох = 2
total_train_steps = (len(tokenized_squad["train"]) // размер пакета) * num_epochs
оптимизатор, расписание = create_optimizer(
init_lr=2e-5,
num_warmup_steps=0,
num_train_steps=total_train_steps,
) Загрузите вашу модель с классом TFAutoModelForQuestionAnswering:
из импорта трансформаторов TFAutoModelForQuestionAnswering
модель = TFAutoModelForQuestionAnswering ("дистильберт-база-без оболочки") Скомпилируйте модель:
импортируйте тензорный поток как tf model.compile(optimizer=optimizer)
Вызовите model.fit для точной настройки модели:
model.fit(
tf_train_set,
validation_data=tf_validation_set,
эпохи = num_train_epochs,
) Улучшение преобразователей с помощью вероятностных ключей внимания
Там Минь Нгуен, Тан Минь Нгуен, Дунг Д. Д. Ле, Дуй Кхуонг Нгуен, Вьет-Ань Тран, Ричард Баранюк, Нхат Хо, Стэнли ОшерТруды 39Международная конференция по машинному обучению , PMLR 162:16595-16621, 2022.
Аннотация
Мультиголовное внимание является движущей силой современных трансформеров, которые достигают выдающихся результатов в различных задачах обработки естественного языка (NLP) и компьютерного зрения. Было замечено, что для многих приложений эти головки внимания изучают избыточное встраивание, и большинство из них можно удалить без ухудшения производительности модели. Вдохновленные этим наблюдением, мы предлагаем Transformer with a Mixture of Gaussian Keys (Transformer-MGK), новую архитектуру трансформатора, которая заменяет избыточные головки в трансформаторах смесью ключей на каждой головке. Эти комбинации клавиш следуют модели смеси Гаусса и позволяют каждой головке внимания эффективно фокусироваться на различных частях входной последовательности. По сравнению со своим обычным аналогом-трансформером Transformer-MGK ускоряет обучение и вывод, имеет меньше параметров и требует меньшего количества FLOP для вычислений, обеспечивая при этом сопоставимую или лучшую точность в разных задачах. Transformer-MGK также может быть легко расширен для использования с линейным вниманием. Мы эмпирически демонстрируем преимущества Transformer-MGK в ряде практических приложений, включая языковое моделирование и задачи, включающие очень длинные последовательности. В тестах Wikitext-103 и Long Range Arena трансформаторы-MGK с 4 головками демонстрируют сравнимую или лучшую производительность с базовыми трансформаторами с 8 головками.
Эти комбинации клавиш следуют модели смеси Гаусса и позволяют каждой головке внимания эффективно фокусироваться на различных частях входной последовательности. По сравнению со своим обычным аналогом-трансформером Transformer-MGK ускоряет обучение и вывод, имеет меньше параметров и требует меньшего количества FLOP для вычислений, обеспечивая при этом сопоставимую или лучшую точность в разных задачах. Transformer-MGK также может быть легко расширен для использования с линейным вниманием. Мы эмпирически демонстрируем преимущества Transformer-MGK в ряде практических приложений, включая языковое моделирование и задачи, включающие очень длинные последовательности. В тестах Wikitext-103 и Long Range Arena трансформаторы-MGK с 4 головками демонстрируют сравнимую или лучшую производительность с базовыми трансформаторами с 8 головками.
Процитировать эту статью
БибТекс
@InProceedings{pmlr-v162-nguyen22c,
title = {Улучшение трансформаторов с вероятностными ключами внимания},
автор = {Нгуен, Там Минь и Нгуен, Тан Минь и Ле, Дунг Д.![]() Д. и Нгуен, Дуй Хуонг и Тран, Вьет-Ань и Баранюк, Ричард и Хо, Нхат и Ошер, Стэнли},
booktitle = {Материалы 39-й Международной конференции по машинному обучению},
страницы = {16595--16621},
год = {2022},
редактор = {Чаудхури, Камалика и Джегелька, Стефани и Сонг, Ле и Сепешвари, Чаба и Ню, Ганг и Сабато, Сиван},
громкость = {162},
серия = {Материалы исследования машинного обучения},
месяц = {17--23 июля},
издатель = {PMLR},
pdf = {https://proceedings.mlr.press/v162/nguyen22c/nguyen22c.pdf},
URL = {https://proceedings.mlr.press/v162/nguyen22c.html},
abstract = {Многоголовое внимание является движущей силой современных трансформеров, которые достигают выдающихся результатов в различных задачах обработки естественного языка (NLP) и компьютерного зрения. Было замечено, что для многих приложений эти головки внимания изучают избыточное встраивание, и большинство из них можно удалить без ухудшения производительности модели. Вдохновленные этим наблюдением, мы предлагаем Transformer with a Mixture of Gaussian Keys (Transformer-MGK), новую архитектуру трансформатора, которая заменяет избыточные головки в трансформаторах смесью ключей на каждой головке.
Д. и Нгуен, Дуй Хуонг и Тран, Вьет-Ань и Баранюк, Ричард и Хо, Нхат и Ошер, Стэнли},
booktitle = {Материалы 39-й Международной конференции по машинному обучению},
страницы = {16595--16621},
год = {2022},
редактор = {Чаудхури, Камалика и Джегелька, Стефани и Сонг, Ле и Сепешвари, Чаба и Ню, Ганг и Сабато, Сиван},
громкость = {162},
серия = {Материалы исследования машинного обучения},
месяц = {17--23 июля},
издатель = {PMLR},
pdf = {https://proceedings.mlr.press/v162/nguyen22c/nguyen22c.pdf},
URL = {https://proceedings.mlr.press/v162/nguyen22c.html},
abstract = {Многоголовое внимание является движущей силой современных трансформеров, которые достигают выдающихся результатов в различных задачах обработки естественного языка (NLP) и компьютерного зрения. Было замечено, что для многих приложений эти головки внимания изучают избыточное встраивание, и большинство из них можно удалить без ухудшения производительности модели. Вдохновленные этим наблюдением, мы предлагаем Transformer with a Mixture of Gaussian Keys (Transformer-MGK), новую архитектуру трансформатора, которая заменяет избыточные головки в трансформаторах смесью ключей на каждой головке.![]() Эти комбинации клавиш следуют модели смеси Гаусса и позволяют каждой головке внимания эффективно фокусироваться на различных частях входной последовательности. По сравнению со своим обычным аналогом-трансформером Transformer-MGK ускоряет обучение и вывод, имеет меньше параметров и требует меньшего количества FLOP для вычислений, обеспечивая при этом сопоставимую или лучшую точность в разных задачах. Transformer-MGK также может быть легко расширен для использования с линейным вниманием. Мы эмпирически демонстрируем преимущества Transformer-MGK в ряде практических приложений, включая языковое моделирование и задачи, включающие очень длинные последовательности. В тестах Wikitext-103 и Long Range Arena трансформаторы-MGK с 4 головками демонстрируют сравнимую или лучшую производительность с базовыми трансформаторами с 8 головками.}
}
Эти комбинации клавиш следуют модели смеси Гаусса и позволяют каждой головке внимания эффективно фокусироваться на различных частях входной последовательности. По сравнению со своим обычным аналогом-трансформером Transformer-MGK ускоряет обучение и вывод, имеет меньше параметров и требует меньшего количества FLOP для вычислений, обеспечивая при этом сопоставимую или лучшую точность в разных задачах. Transformer-MGK также может быть легко расширен для использования с линейным вниманием. Мы эмпирически демонстрируем преимущества Transformer-MGK в ряде практических приложений, включая языковое моделирование и задачи, включающие очень длинные последовательности. В тестах Wikitext-103 и Long Range Arena трансформаторы-MGK с 4 головками демонстрируют сравнимую или лучшую производительность с базовыми трансформаторами с 8 головками.}
}
Сноска
%0 Документ конференции
%T Улучшение трансформаторов с вероятностными ключами внимания
%A Там Минь Нгуен
%А Тан Минь Нгуен
%A Дунг Д. Д. Ле
%A Дуй Кхуонг Нгуен
%Вьет-Ань Тран
%A Ричард Баранюк
%А Нят Хо
%A Стэнли Ошер
%B Материалы 39-й Международной конференции по машинному обучению
%C Материалы исследования машинного обучения
%D 2022
%E Камалика Чаудхури
%E Стефани Егелька
%E Ле Сонг
%E Чаба Сепешвари
%E Ган Ню
%E Сиван Сабато
%F пмлр-v162-nguyen22c
%I PMLR
%Р 16595--16621
%U https://proceedings.mlr.press/v162/nguyen22c.html
%V 162
%X Мультиголовное внимание — это движущая сила современных трансформеров, которые достигают выдающихся результатов в различных задачах обработки естественного языка (NLP) и компьютерного зрения. Было замечено, что для многих приложений эти головки внимания изучают избыточное встраивание, и большинство из них можно удалить без ухудшения производительности модели. Вдохновленные этим наблюдением, мы предлагаем Transformer with a Mixture of Gaussian Keys (Transformer-MGK), новую архитектуру трансформатора, которая заменяет избыточные головки в трансформаторах смесью ключей на каждой головке. Эти комбинации клавиш следуют модели смеси Гаусса и позволяют каждой головке внимания эффективно фокусироваться на различных частях входной последовательности.
Д. Ле
%A Дуй Кхуонг Нгуен
%Вьет-Ань Тран
%A Ричард Баранюк
%А Нят Хо
%A Стэнли Ошер
%B Материалы 39-й Международной конференции по машинному обучению
%C Материалы исследования машинного обучения
%D 2022
%E Камалика Чаудхури
%E Стефани Егелька
%E Ле Сонг
%E Чаба Сепешвари
%E Ган Ню
%E Сиван Сабато
%F пмлр-v162-nguyen22c
%I PMLR
%Р 16595--16621
%U https://proceedings.mlr.press/v162/nguyen22c.html
%V 162
%X Мультиголовное внимание — это движущая сила современных трансформеров, которые достигают выдающихся результатов в различных задачах обработки естественного языка (NLP) и компьютерного зрения. Было замечено, что для многих приложений эти головки внимания изучают избыточное встраивание, и большинство из них можно удалить без ухудшения производительности модели. Вдохновленные этим наблюдением, мы предлагаем Transformer with a Mixture of Gaussian Keys (Transformer-MGK), новую архитектуру трансформатора, которая заменяет избыточные головки в трансформаторах смесью ключей на каждой головке. Эти комбинации клавиш следуют модели смеси Гаусса и позволяют каждой головке внимания эффективно фокусироваться на различных частях входной последовательности. По сравнению со своим обычным аналогом-трансформером Transformer-MGK ускоряет обучение и вывод, имеет меньше параметров и требует меньшего количества FLOP для вычислений, обеспечивая при этом сопоставимую или лучшую точность в разных задачах. Transformer-MGK также может быть легко расширен для использования с линейным вниманием. Мы эмпирически демонстрируем преимущества Transformer-MGK в ряде практических приложений, включая языковое моделирование и задачи, включающие очень длинные последовательности. В тестах Wikitext-103 и Long Range Arena трансформаторы-MGK с 4 головками демонстрируют сравнимую или лучшую производительность с базовыми трансформаторами с 8 головками.
По сравнению со своим обычным аналогом-трансформером Transformer-MGK ускоряет обучение и вывод, имеет меньше параметров и требует меньшего количества FLOP для вычислений, обеспечивая при этом сопоставимую или лучшую точность в разных задачах. Transformer-MGK также может быть легко расширен для использования с линейным вниманием. Мы эмпирически демонстрируем преимущества Transformer-MGK в ряде практических приложений, включая языковое моделирование и задачи, включающие очень длинные последовательности. В тестах Wikitext-103 и Long Range Arena трансформаторы-MGK с 4 головками демонстрируют сравнимую или лучшую производительность с базовыми трансформаторами с 8 головками.
АПА
Нгуен, Т.М., Нгуен, Т.М., Ле, Д.Д.Д., Нгуен, Д.К., Тран, В., Баранюк, Р., Хо, Н. и Ошер, С.. (2022). Улучшение трансформаторов с вероятностными ключами внимания. Proceedings of the 39th International Conference on Machine Learning , in Proceedings of Machine Learning Research 162:16595-16621 Доступно по адресу https://proceedings.![]() mlr.press/v162/nguyen22c.html.
mlr.press/v162/nguyen22c.html.
Сопутствующие материалы
Исследовательские проекты | Тан Нгуен — Исследование Страница
Многоголовное внимание — это движущая сила современных трансформеров, которые достигают выдающихся результатов в различных задачах обработки естественного языка (NLP) и компьютерного зрения. Было замечено, что для многих приложений эти головки внимания изучают избыточное встраивание, и большинство из них можно удалить без ухудшения производительности модели. Вдохновленные этим наблюдением, мы предлагаем Transformer with a Mixture of Gaussian Keys (Transformer-MGK), новую архитектуру трансформатора, которая заменяет избыточные головки в трансформаторах смесью ключей на каждой головке. Эти комбинации клавиш следуют модели смеси Гаусса и позволяют каждой головке внимания эффективно фокусироваться на различных частях входной последовательности. По сравнению со своим обычным аналогом-трансформером Transformer-MGK ускоряет обучение и логические выводы, имеет меньше параметров и требует меньшего количества FLOP для вычислений, обеспечивая при этом сравнимую или лучшую точность во всех задачах. Transformer-MGK также может быть легко расширен для использования с линейными датчиками внимания. Мы эмпирически демонстрируем преимущества Transformer-MGK в ряде практических приложений, включая языковое моделирование и задачи, включающие очень длинные последовательности. В тестах Wikitext-103 и Long Range Arena трансформаторы-MGK с 4 головками демонстрируют сравнимую или лучшую производительность с базовыми трансформаторами с 8 головками.
Transformer-MGK также может быть легко расширен для использования с линейными датчиками внимания. Мы эмпирически демонстрируем преимущества Transformer-MGK в ряде практических приложений, включая языковое моделирование и задачи, включающие очень длинные последовательности. В тестах Wikitext-103 и Long Range Arena трансформаторы-MGK с 4 головками демонстрируют сравнимую или лучшую производительность с базовыми трансформаторами с 8 головками.
Т. Нгуен (соавтор), Т. Нгуен (соавтор) , Д. Д. Ле, К. Нгуен, А. Тран, Р. Г. Баранюк, Н. Хо, С. Дж. Ошер. Преобразователь со смесью гауссовых ключей. Представлено в ICLR, 2022
Мы предлагаем GRAph Neural Diffusion с исходным термином (GRAND++) для глубокого обучения графа с ограниченным количеством помеченных узлов, т. е. с низкой скоростью маркировки. GRAND++ — это класс архитектур глубокого обучения на графах с непрерывной глубиной, теоретической основой которых является процесс диффузии на графах с исходным термином.![]() Исходный член гарантирует два интересных теоретических свойства GRAND++: (i) представление узлов графа в динамике GRAND++ не будет сходиться к постоянному вектору по всем узлам, даже когда время стремится к бесконечности, что смягчает чрезмерное сглаживание проблема графовых нейронных сетей и позволяет изучать графы в очень глубоких архитектурах. (ii) GRAND++ может обеспечить точную классификацию, даже если модель обучена с очень ограниченным количеством помеченных обучающих данных. Мы экспериментально проверяем два вышеупомянутых преимущества на различных тестовых задачах глубокого обучения на графах, демонстрируя значительное улучшение по сравнению со многими существующими нейронными сетями на графах.
Исходный член гарантирует два интересных теоретических свойства GRAND++: (i) представление узлов графа в динамике GRAND++ не будет сходиться к постоянному вектору по всем узлам, даже когда время стремится к бесконечности, что смягчает чрезмерное сглаживание проблема графовых нейронных сетей и позволяет изучать графы в очень глубоких архитектурах. (ii) GRAND++ может обеспечить точную классификацию, даже если модель обучена с очень ограниченным количеством помеченных обучающих данных. Мы экспериментально проверяем два вышеупомянутых преимущества на различных тестовых задачах глубокого обучения на графах, демонстрируя значительное улучшение по сравнению со многими существующими нейронными сетями на графах.
М. Торп (соавтор), Т. Нгуен (соавтор) , Х. Ся (соавтор), Т. Стромер, А. Бертоцци, С. Ошер, Б. Ван. GRAND++: графическая нейронная диффузия с исходным термином. Представлено в ICLR, 2022.
Мы предлагаем FMMformers, класс эффективных и гибких преобразователей, вдохновленных знаменитым методом быстрых мультиполей (FMM) для ускорения моделирования взаимодействующих частиц. FMM разлагает взаимодействие между частицами на компоненты ближнего и дальнего поля, а затем выполняет прямые и грубые вычисления соответственно. Точно так же формирователи FMM разлагают внимание на внимание ближнего и дальнего поля, моделируя внимание ближнего поля с помощью ленточной матрицы, а внимание дальнего поля — с помощью матрицы низкого ранга. Вычисление матрицы внимания для FMMformers требует линейной сложности по времени вычислений и объему памяти по отношению к длине последовательности. Напротив, стандартные преобразователи страдают квадратичной сложностью. Мы анализируем и подтверждаем преимущество FMMformers перед стандартным преобразователем в тестах Long Range Arena и языкового моделирования. FMMformers может даже превзойти стандартный трансформатор по точности со значительным отрывом. Например, FMMformers достигают средней точности классификации 60,74 % в пяти задачах Long Range Arena, что значительно лучше, чем средняя точность стандартного преобразователя 58,70 %.
FMM разлагает взаимодействие между частицами на компоненты ближнего и дальнего поля, а затем выполняет прямые и грубые вычисления соответственно. Точно так же формирователи FMM разлагают внимание на внимание ближнего и дальнего поля, моделируя внимание ближнего поля с помощью ленточной матрицы, а внимание дальнего поля — с помощью матрицы низкого ранга. Вычисление матрицы внимания для FMMformers требует линейной сложности по времени вычислений и объему памяти по отношению к длине последовательности. Напротив, стандартные преобразователи страдают квадратичной сложностью. Мы анализируем и подтверждаем преимущество FMMformers перед стандартным преобразователем в тестах Long Range Arena и языкового моделирования. FMMformers может даже превзойти стандартный трансформатор по точности со значительным отрывом. Например, FMMformers достигают средней точности классификации 60,74 % в пяти задачах Long Range Arena, что значительно лучше, чем средняя точность стандартного преобразователя 58,70 %.
Т. Нгуен , В. Сулиафу, С. Дж. Ошер, Л. Чен и Б. Ван. FMMformer: эффективный и гибкий преобразователь за счет разложения ближней и дальней зоны Внимание . NeurIPS, 2021.
Нгуен , В. Сулиафу, С. Дж. Ошер, Л. Чен и Б. Ван. FMMformer: эффективный и гибкий преобразователь за счет разложения ближней и дальней зоны Внимание . NeurIPS, 2021.
Мы предлагаем FMMformers, класс эффективных и гибких преобразователей, вдохновленных знаменитым методом быстрых мультиполей (FMM) для ускорения моделирования взаимодействующих частиц. FMM разлагает взаимодействие между частицами на компоненты ближнего и дальнего поля, а затем выполняет прямые и грубые вычисления соответственно. Точно так же формирователи FMM разлагают внимание на внимание ближнего и дальнего поля, моделируя внимание ближнего поля с помощью ленточной матрицы, а внимание дальнего поля — с помощью матрицы низкого ранга. Вычисление матрицы внимания для FMMformers требует линейной сложности по времени вычислений и объему памяти по отношению к длине последовательности.
Х. Ся, В. Сулиафу, Х. Джи, Т. Нгуен , А. Л. Бертоцци, С. Дж. Ошер и Б. Ван. Нейронные обыкновенные дифференциальные уравнения Heavy Ball. NeurIPS, 2021.
NeurIPS, 2021.
Проектирование глубоких нейронных сетей — это искусство, которое часто требует дорогостоящего поиска возможных архитектур. Чтобы преодолеть это для рекуррентных нейронных сетей (RNN), мы устанавливаем связь между динамикой скрытого состояния в RNN и градиентным спуском (GD). Затем мы интегрируем импульс в эту структуру и предлагаем новое семейство RNN, называемое {\em MomentumRNN}. Мы теоретически доказываем и численно демонстрируем, что MomentumRNN устраняют проблему исчезающего градиента при обучении RNN. Мы изучаем долговременную кратковременную память импульса (MomentumLSTM) и проверяем ее преимущества в скорости сходимости и точности по сравнению с ее аналогом LSTM в различных тестах с небольшим компромиссом в вычислительной эффективности или эффективности памяти. Мы также демонстрируем, что MomentumRNN применим ко многим типам рекуррентных ячеек, в том числе к современным ортогональным RNN. Наконец, мы показываем, что другие передовые методы оптимизации на основе импульса, такие как ускоренные градиенты Адама и Нестерова с перезапуском, могут быть легко включены в структуру MomentumRNN для проектирования новых повторяющихся ячеек с еще более высокой производительностью.
Т. Нгуен , Р. Г. Баранюк, А. Л. Бертоцци и С. Дж. Ошер. MomentumRNN: Интеграция Momentum в рекуррентные нейронные сети. NeurIPS, 2020.
Нейронные сети уязвимы для входных возмущений, таких как аддитивный шум и атаки злоумышленников. Напротив, человеческое восприятие гораздо более устойчиво к таким возмущениям. Гипотеза байесовского мозга утверждает, что человеческий мозг использует внутреннюю генеративную модель для обновления апостериорных убеждений сенсорного ввода. Этот механизм можно интерпретировать как форму самосогласования между максимальной апостериорной (MAP) оценкой внутренней генеративной модели и внешней средой. Вдохновленные такой гипотезой, мы обеспечиваем самосогласованность в нейронных сетях, включив генеративную рекуррентную обратную связь. Мы реализуем этот дизайн на сверточных нейронных сетях (CNN). Предлагаемая структура, называемая сверточной нейронной сетью с обратной связью (CNN-F), вводит генеративную обратную связь со скрытыми переменными в существующие архитектуры CNN, где согласованные прогнозы делаются посредством чередующегося вывода MAP в рамках байесовской структуры. В экспериментах CNN-F демонстрирует значительно улучшенную устойчивость к состязаниям по сравнению с обычными CNN с прямой связью на стандартных тестах.
В экспериментах CNN-F демонстрирует значительно улучшенную устойчивость к состязаниям по сравнению с обычными CNN с прямой связью на стандартных тестах.
Ю. Хуан, Дж. Горнет, С. Дай, З. Ю, Т. Нгуен , Д. Ю. Цао, А. Анандкумар. Нейронные сети с рекуррентной генерирующей обратной связью . NeurIPS, 2020.
Стохастический градиентный спуск (SGD) с постоянным импульсом и его варианты, такие как Адам, являются предпочтительными алгоритмами оптимизации для обучения глубоких нейронных сетей (ГНС). Поскольку обучение DNN невероятно затратно в вычислительном отношении, существует большой интерес к ускорению сходимости. Ускоренный градиент Нестерова (NAG) улучшает скорость сходимости градиентного спуска (GD) для выпуклой оптимизации с использованием специально разработанного импульса; однако он накапливает ошибку, когда используется неточный градиент (например, в SGD), замедляя конвергенцию в лучшем случае и расходясь в худшем. В этой статье мы предлагаем запланированный перезапуск SGD (SRSGD), новую схему в стиле NAG для обучения DNN. SRSGD заменяет постоянный импульс в SGD увеличивающимся импульсом в NAG, но стабилизирует итерации, сбрасывая импульс до нуля в соответствии с графиком. Используя различные модели и тесты для классификации изображений, мы демонстрируем, что при обучении DNN SRSGD значительно улучшает сходимость и обобщение; например, при обучении ResNet200 для классификации ImageNet SRSGD достигает коэффициента ошибок 20,9.3% против контрольного показателя 22,13%. Эти улучшения становятся более значительными по мере того, как сеть становится глубже. Кроме того, как в CIFAR, так и в ImageNet, SRSGD достигает аналогичного или даже лучшего уровня ошибок при значительно меньшем количестве периодов обучения по сравнению с базовым уровнем SGD.
SRSGD заменяет постоянный импульс в SGD увеличивающимся импульсом в NAG, но стабилизирует итерации, сбрасывая импульс до нуля в соответствии с графиком. Используя различные модели и тесты для классификации изображений, мы демонстрируем, что при обучении DNN SRSGD значительно улучшает сходимость и обобщение; например, при обучении ResNet200 для классификации ImageNet SRSGD достигает коэффициента ошибок 20,9.3% против контрольного показателя 22,13%. Эти улучшения становятся более значительными по мере того, как сеть становится глубже. Кроме того, как в CIFAR, так и в ImageNet, SRSGD достигает аналогичного или даже лучшего уровня ошибок при значительно меньшем количестве периодов обучения по сравнению с базовым уровнем SGD.
Ван (соавтор), Т. Нгуен (соавтор) , А. Л. Бертоцци, Р. Г. Баранюк и С. Дж. Ошер. Запланированный импульс перезапуска для ускоренного стохастического градиентного спуска . Препринт arXiv arXiv: 2002.10583, 2020.
Непрерывные нормализующие потоки (CNF) стали многообещающими глубокими генеративными моделями для широкого круга задач благодаря их обратимости и точной оценке правдоподобия. Однако формирование CNF на сигналах, представляющих интерес для генерации условного изображения и последующих задач прогнозирования, неэффективно из-за многомерного скрытого кода, генерируемого моделью, который должен иметь тот же размер, что и входные данные. В этой статье мы предлагаем InfoCNF, эффективную условную CNF, которая разделяет скрытое пространство на контролируемый код для конкретного класса и неконтролируемый код, который используется всеми классами для эффективного использования помеченной информации. Поскольку стратегия разбиения (немного) увеличивает количество вычислений функций (NFE), InfoCNF также использует вентильные сети для изучения допусков ошибок своих решателей обыкновенных дифференциальных уравнений (ODE) для повышения скорости и производительности. Мы эмпирически показываем, что InfoCNF повышает точность теста по сравнению с базовым уровнем, обеспечивая при этом сопоставимые оценки правдоподобия и снижая NFE на CIFAR10. Кроме того, применение той же стратегии секционирования в InfoCNF к данным временных рядов помогает повысить производительность экстраполяции.
Однако формирование CNF на сигналах, представляющих интерес для генерации условного изображения и последующих задач прогнозирования, неэффективно из-за многомерного скрытого кода, генерируемого моделью, который должен иметь тот же размер, что и входные данные. В этой статье мы предлагаем InfoCNF, эффективную условную CNF, которая разделяет скрытое пространство на контролируемый код для конкретного класса и неконтролируемый код, который используется всеми классами для эффективного использования помеченной информации. Поскольку стратегия разбиения (немного) увеличивает количество вычислений функций (NFE), InfoCNF также использует вентильные сети для изучения допусков ошибок своих решателей обыкновенных дифференциальных уравнений (ODE) для повышения скорости и производительности. Мы эмпирически показываем, что InfoCNF повышает точность теста по сравнению с базовым уровнем, обеспечивая при этом сопоставимые оценки правдоподобия и снижая NFE на CIFAR10. Кроме того, применение той же стратегии секционирования в InfoCNF к данным временных рядов помогает повысить производительность экстраполяции.
Т. Нгуен , А. Гарг, Р. Г. Баранюк, А. Анандкумар. InfoCNF: эффективный условный непрерывный нормализующий поток с адаптивными решателями . Препринт arXiv arXiv:1912.03978, 2019.
Модель нейронного рендеринга: совместная генерация и прогнозирование для частично контролируемого обучения
Неконтролируемое и полуконтролируемое обучение — важные проблемы, но сложные при работе со сложными данными, такими как естественные изображения. Прогресс в решении этих проблем ускорился бы, если бы у нас был доступ к соответствующим генеративным моделям, в рамках которых можно было бы ставить соответствующие задачи логического вывода.
Учитывая успех сверточных нейронных сетей (CNN) для прогнозирования изображений, мы разрабатываем новый класс вероятностных генеративных моделей, а именно модели нейронного рендеринга (NRM), вывод которых соответствует любой заданной архитектуре CNN. NRM использует данную CNN для проектирования априорного распределения в вероятностной модели. Мы показываем, что это приводит к эффективному полуконтролируемому обучению, которое использует менее размеченные данные, сохраняя при этом хорошую производительность прогнозирования. NRM генерирует изображения от грубого до более мелкого масштаба. Он вводит небольшой набор скрытых переменных на каждом уровне и обеспечивает зависимость между всеми скрытыми переменными посредством сопряженного априорного распределения. Этот сопряженный априор дает новый регуляризатор, основанный на путях, визуализируемых в генеративной модели для обучения CNN — нормализацию пути рендеринга (RPN). Мы показываем, что этот регуляризатор улучшает обобщение как в теории, так и на практике. Кроме того, оценка правдоподобия в NRM приводит к потерям при обучении для CNN, и, вдохновленные этим, мы разрабатываем новую потерю, называемую кросс-энтропией Max-Min, которая превосходит традиционные потери кросс-энтропии для классификации объектов. Перекрестная энтропия Max-Min предлагает новую глубокую сетевую архитектуру, а именно сеть Max-Min, для реализации этой потери.
Мы показываем, что это приводит к эффективному полуконтролируемому обучению, которое использует менее размеченные данные, сохраняя при этом хорошую производительность прогнозирования. NRM генерирует изображения от грубого до более мелкого масштаба. Он вводит небольшой набор скрытых переменных на каждом уровне и обеспечивает зависимость между всеми скрытыми переменными посредством сопряженного априорного распределения. Этот сопряженный априор дает новый регуляризатор, основанный на путях, визуализируемых в генеративной модели для обучения CNN — нормализацию пути рендеринга (RPN). Мы показываем, что этот регуляризатор улучшает обобщение как в теории, так и на практике. Кроме того, оценка правдоподобия в NRM приводит к потерям при обучении для CNN, и, вдохновленные этим, мы разрабатываем новую потерю, называемую кросс-энтропией Max-Min, которая превосходит традиционные потери кросс-энтропии для классификации объектов. Перекрестная энтропия Max-Min предлагает новую глубокую сетевую архитектуру, а именно сеть Max-Min, для реализации этой потери. Численные эксперименты показывают, что NRM с RPN и перекрестной энтропией Max-Min превосходит или соответствует современному уровню техники в тестах, включая SVHN, CIFAR10 и CIFAR100 для полууправляемых и контролируемых задач обучения.
Численные эксперименты показывают, что NRM с RPN и перекрестной энтропией Max-Min превосходит или соответствует современному уровню техники в тестах, включая SVHN, CIFAR10 и CIFAR100 для полууправляемых и контролируемых задач обучения.
Ю. Хуанг, Дж. Горнет, С. Дай, З. Ю, Т. Нгуен , Д. Ю. Цао, А. Анандкумар. Нейронные сети с рекуррентной генерирующей обратной связью . Препринт arXiv arXiv: 2007.09200, 2020. (Принято на NeurIPS 2020)
Т. Нгуен (соавтор) , Н. Хо (соавтор), А. Б. Патель, А. Анандкумар, М. И. Джордан, Р. Г. Баранюк. Модель нейронного рендеринга: совместная генерация и прогнозирование для полууправляемого обучения . DeepMath, 2019.
Н. Хо, Т. Нгуен (соавтор), А. Б. Патель, А. Анандкумар, М. И. Джордан, Р. Г. Баранюк. Модель глубокого рендеринга со скрытой зависимостью . Семинар по теоретическим основам и приложениям глубоких генеративных моделей в ICML, 2018.
А. Б. Патель, Т. Нгуен и Р. Г. Баранюк. Вероятностная структура для глубокого обучения . NIPS, 2016.
Б. Патель, Т. Нгуен и Р. Г. Баранюк. Вероятностная структура для глубокого обучения . NIPS, 2016.
T. Nguyen , W. Liu, E. Perez, R.G. Baraniuk, and A.B. Patel. Полууправляемое обучение с помощью модели Deep Rendering Mixture . Препринт arXiv arXiv:1612.01942, 2016.
T. Nguyen, W. Liu, F. Sinz, R.G. Baraniuk, A.A. Tolias, X. Pitkow, A.B. Patel. На пути к кортикальной модели глубокого обучения: полууправляемое обучение, разделительная нормализация и синаптическое сокращение . Conference on Cognitive Computational Neuroscience (CCN), 2017 г.
Изучение классификаторов изображений на основе (ограниченных) реальных и (обильных) синтетических данных
Хотя самые большие успехи глубокого обучения в компьютерном зрении основаны на массивных наборах данных, состоящих из помеченных изображений, это часто дорого обходится или невозможно получить и аннотировать такие объемные данные на практике. Одним из многообещающих решений является обучение моделей на синтетических данных, для которых мы знаем истинные метки, а затем развертывание этих моделей в реальных сценариях. К сожалению, методы контролируемого обучения плохо работают, когда распределения обучения и тестирования расходятся. Тонкие различия между реальными и синтетическими данными значительно снижают производительность. Чтобы изучить модели без реальных меток, мы предлагаем решение, состоящее из двух частей: (i) мы используем синтетический рендерер, способный генерировать большое количество реалистично изменяющихся синтетических изображений; и (ii) мы предлагаем стратегию адаптации домена, чтобы преодолеть разрыв между синтетическими и реальными изображениями. Смешивая синтетические и реальные данные в каждом мини-пакете во время обучения, мы повышаем точность тестов для задач классификации объектов. Наконец, мы предлагаем генеративно-состязательную сеть смешанной реальности (MrGAN), которая итеративно сопоставляет синтетические и реальные данные с помощью многоэтапного итеративного процесса.
Одним из многообещающих решений является обучение моделей на синтетических данных, для которых мы знаем истинные метки, а затем развертывание этих моделей в реальных сценариях. К сожалению, методы контролируемого обучения плохо работают, когда распределения обучения и тестирования расходятся. Тонкие различия между реальными и синтетическими данными значительно снижают производительность. Чтобы изучить модели без реальных меток, мы предлагаем решение, состоящее из двух частей: (i) мы используем синтетический рендерер, способный генерировать большое количество реалистично изменяющихся синтетических изображений; и (ii) мы предлагаем стратегию адаптации домена, чтобы преодолеть разрыв между синтетическими и реальными изображениями. Смешивая синтетические и реальные данные в каждом мини-пакете во время обучения, мы повышаем точность тестов для задач классификации объектов. Наконец, мы предлагаем генеративно-состязательную сеть смешанной реальности (MrGAN), которая итеративно сопоставляет синтетические и реальные данные с помощью многоэтапного итеративного процесса.