Вес швеллера 14 за 1 метр: Купить швеллер 14, размеры швеллера, цена на швеллер 14 в Москве
alexxlab | 18.03.2023 | 0 | Разное
Вес швеллера 16 за 1 метр в Кирове: 500-товаров: бесплатная доставка, скидка-22% [перейти]
Партнерская программаПомощь
Киров
Каталог
Каталог Товаров
Одежда и обувь
Одежда и обувь
Стройматериалы
Стройматериалы
Текстиль и кожа
Текстиль и кожа
Здоровье и красота
Здоровье и красота
Детские товары
Детские товары
Электротехника
Электротехника
Продукты и напитки
Продукты и напитки
Дом и сад
Дом и сад
Сельское хозяйство
Сельское хозяйство
Мебель и интерьер
Мебель и интерьер
Торговля и склад
Торговля и склад
Все категории
ВходИзбранное
Вес швеллера 16 за 1 метр
82 861
Швеллер оцинкованный 16 Тип: швеллер, Ширина сечения: 16 мм, Номер швеллера: 16
ПОДРОБНЕЕЕще цены и похожие товары
Швеллер, ширина 24 см (за 1 м) Тип: швеллер, Длина: 1 м, Ширина сечения: 240 мм
ПОДРОБНЕЕЕще цены и похожие товары
Швеллер 16 У Тип: швеллер, Номер швеллера: 5, Номер двутавра: 12
ПОДРОБНЕЕЕще цены и похожие товары
97 845
Швеллер 12; вес 10,833кг/1м. п., длина 12м. Тип: швеллер, Ширина сечения: 1000мм, Номер швеллера: 10
п., длина 12м. Тип: швеллер, Ширина сечения: 1000мм, Номер швеллера: 10
ПОДРОБНЕЕЕще цены и похожие товары
Арматура гладкая А-1 (А240) – 16 мм (цена за метр) Класс: A-I, Диаметр арматуры, мм: 16, Профиль:
ПОДРОБНЕЕЕще цены и похожие товары
Арматура 16 рифленая А3 А500С (цена за метр) Диаметр арматуры, мм: 16, Профиль: периодический
ПОДРОБНЕЕЕще цены и похожие товары
106 506
Швеллер 24П Тип: швеллер, Толщина полки: 10 мм, Номер швеллера: 5
ПОДРОБНЕЕЕще цены и похожие товары
102 410
Швеллер 24П Тип: швеллер, Номер двутавра: 24
ПОДРОБНЕЕЕще цены и похожие товары
Швеллер стальной 16 Тип: швеллер, Номер двутавра: 16
ПОДРОБНЕЕЕще цены и похожие товары
Арматура 16 гладкая а1 а240 (цена за метр) Класс: A-I, Диаметр арматуры, мм: 16, Профиль: гладкий
ПОДРОБНЕЕЕще цены и похожие товары
Швеллер 16 Тип: швеллер, Номер швеллера: 10, Номер двутавра: 16
ПОДРОБНЕЕЕще цены и похожие товары
Арматура 16 рифленая А3 А500С немерная (цена за метр) Диаметр арматуры, мм: 16, Профиль:
ПОДРОБНЕЕЕще цены и похожие товары
169 880
Швеллер гнутый оцинкованный 100х100х5 Тип: швеллер, Номер швеллера: 5, Метод изготовления: гнутый
ПОДРОБНЕЕЕще цены и похожие товары
90 000
Швеллер гнутый 100х40х4 Тип: швеллер, Длина: 6 м, Номер двутавра: 40
ПОДРОБНЕЕЕще цены и похожие товары
Швеллер № 20 (цена за метр) Тип: швеллер, Номер двутавра: 20, Метод изготовления: горячекатаный
ПОДРОБНЕЕЕще цены и похожие товары
90 000
Швеллер гнутый 100х60х5 Тип: швеллер, Длина: 6 м, Номер швеллера: 5
ПОДРОБНЕЕЕще цены и похожие товары
90 000
Швеллер гнутый 100х65х4 Тип: швеллер, Длина: 6 м, Метод изготовления: гнутый
ПОДРОБНЕЕЕще цены и похожие товары
198 920
Швеллер гнутый оцинкованный 100х100х4 Тип: швеллер, Метод изготовления: гнутый
ПОДРОБНЕЕЕще цены и похожие товары
Швеллер 14 мм Тип: швеллер, Длина: 4 м, Ширина сечения: 140 мм
ПОДРОБНЕЕЕще цены и похожие товары
96 900
Швеллер гнутый 200х110х4 Тип: швеллер, Метод изготовления: гнутый
ПОДРОБНЕЕЕще цены и похожие товары
64 700
Швеллер гнутый 100х100х5 Тип: швеллер, Номер швеллера: 5, Номер двутавра: 22
ПОДРОБНЕЕЕще цены и похожие товары
90 000
Швеллер гнутый 100х40х5 Тип: швеллер, Длина: 6 м, Номер швеллера: 5
ПОДРОБНЕЕЕще цены и похожие товары
90 000
Швеллер гнутый 100х65х5 Тип: швеллер, Длина: 6 м, Номер швеллера: 5
ПОДРОБНЕЕЕще цены и похожие товары
65 400
Швеллер гнутый 100х40х4 Тип: швеллер, Номер швеллера: 22, Номер двутавра: 40
ПОДРОБНЕЕЕще цены и похожие товары
489 270
Швеллер гнутый нержавеющий AISI 304 (08Х18Н10) 120х50х3 мм Тип: швеллер, Ширина сечения: 50 мм,
ПОДРОБНЕЕЕще цены и похожие товары
95 930
Швеллер гнутый 50х20х1. 5 ст.3 Тип: швеллер, Длина: 6 м, Номер швеллера: 20
5 ст.3 Тип: швеллер, Длина: 6 м, Номер швеллера: 20
ПОДРОБНЕЕЕще цены и похожие товары
95 930
Швеллер гнутый 120х60х50х5 ст.3 Тип: швеллер, Длина: 6 м, Номер швеллера: 5
ПОДРОБНЕЕЕще цены и похожие товары
162 690
Швеллер гнутый оцинкованный 120х50х3 Тип: швеллер, Номер двутавра: 50, Метод изготовления: гнутый
ПОДРОБНЕЕЕще цены и похожие товары
2 страница из 18
Швеллер
Купить швеллер в Ярославле
В Компании «МеталлГрупп76» вы можете купить швеллер в Ярославле по самой оптимальной цене. Мы сотрудничаем только с проверенными заводами-производителями по всей территории РФ, что позволяет нашим клиентам купить швеллер нужной модели, цена на который будет гораздо ниже, чем у большинства компаний из Ярославля.
Швеллер стальной – это универсальный строительный элемент П-образной формы, который широко используется в строительстве и является неотъемлемой частью многих металлоконструкций. Купить швеллер станет оптимальным решением и при проведении ремонтно-монтажных работ, так как данное металлическое изделие обладает высокой несущей способностью.
Купить швеллер станет оптимальным решением и при проведении ремонтно-монтажных работ, так как данное металлическое изделие обладает высокой несущей способностью.
Мы всегда проводим мониторинг рынка металлопроката и поэтому цена на швеллер в Ярославле у нас остается одной из самых доступных.
Купить швеллер в Ярославле: цена за метр
Мы не работает с посредниками, что дает возможность купить металлический швеллер по цене практически как у производителя. Для того, чтобы узнать, какая на швеллер цена за метр в данный момент, а также по наличию продукции свяжитесь по телефону (4852) 48 48 48 с нашими специалистами.
При покупке 1 п/м швеллера приплата 5%
Сбросить
Сортировать по:НазваниюЦене
На странице:12244896
Швеллер 5
дл. 6 метров/ Вес 30 кг/ Цена за шт.
2610
Перейти в корзину
Швеллер 8
дл. 12 метров/ Вес 85 кг/ Цена за шт.

6800
Перейти в корзину
Швеллер 10
дл. 12 метров/ вес 107 кг/ Цена за шт.
9095
Перейти в корзину
Швеллер 12
Дл. 12 метров/ Вес 129 кг/ Цена за шт.
11868
Перейти в корзину
Швеллер 14
Дл. 12 метров/ Вес 155 кг/ Цена за шт.
13175
Перейти в корзину
Швеллер 16
Дл. 12 метров/ Вес 180 кг/ Цена за шт.
15300
Перейти в корзину
Швеллер 18
Дл. 12 метров/ Вес 200 кг/Цена за шт.
0
Перейти в корзину
Швеллер 24
Дл. 6 метров/ Вес 142 кг/ Цена за шт.
0
Перейти в корзину
Купить швеллер в Ярославле в компании «МеталлГрупп76» — значит получить в самые короткие сроки высококачественные изделия по самой выгодной цене! Неважно, какой метраж швеллера Вас интересует, мы предложим лучшую цену за 1 метр.
6 причин купить швеллер стальной в Ярославле именно у нас
Многие организации региона выбирают нашу компанию в качестве партнера, так как у нас можно не только купить швеллер в Ярославле по лучшей цене, но и получить ряд преимуществ.
Наши клиенты получают:
- Возможность покупки швеллер в Ярославле от завода производителя.
- Широкий выбор продукции.
- Качество проверенное многими годами работы.
- Лучшие цены за метр.
- Быструю доставку по Ярославлю и области.
- Оперативную квалифицированную помощь в любом вопросе.
Область применения стального швеллера
В зависимости от сферы применения, длины и ширины металлический швеллер имеет определенную нумерацию. К примеру, швеллер 10 и 12 идеально подходит для возведения перегородок в многоэтажных домах, а также для строительства каркасов. Для тяжелой промышленности используется изделие с повышенной прочностью — швеллер 20. Соответственно цена швеллера 20 за метр будет дороже, чем менее прочной модели.
В целом сфера применения данного изделия довольно широкая. Кроме строительства, швеллер стальной используют в автомобильной отрасли, возведении железных дорог, тяжелом машиностроении, станкостроении. Небольшой вес швеллера, низкая цена и малый расход делают изделие одним из самых востребованных во многих отраслях производства.
Небольшой вес швеллера, низкая цена и малый расход делают изделие одним из самых востребованных во многих отраслях производства.
В нашем ассортименте присутствует огромный модельный ряд швеллеров различной нумерации: начиная от «6,5», заканчивая швеллерами 30, которые можно купить у нас под заказ.
Благодаря оптимальной ценовой политике и индивидуальному подходу к каждому клиенту делают нас лидером в области продажи металлопроката в городе Ярославле.
Практическое квантование в PyTorch | ПиТорч
к Сурадж Субраманиан, Марк Саруфим, Джерри Чжан
Квантизация — это дешевый и простой способ ускорить работу DNN и снизить требования к памяти. PyTorch предлагает несколько различных подходов к квантованию вашей модели. В этом сообщении блога мы заложим (быстро) основу квантования в глубоком обучении, а затем посмотрим, как каждый метод выглядит на практике.
Рис. 1. Квантование PyTorch <3
Содержимое
- Основы квантования
- Функция отображения
- Параметры квантования
- Калибровка
- Схемы аффинного и симметричного квантования
- Схемы квантования для каждого тензора и канала
- Серверная часть
- QConfig
- В PyTorch
- Динамическое/весовое квантование после тренировки
- Статическое квантование после обучения (PTQ)
- Обучение квантованию (QAT)
- Анализ чувствительности
- Рекомендации для вашего рабочего процесса
- Примечания
- Ссылки
Основы квантования
Если кто-то спросит вас, который час, вы не ответите «10:14:34:430705», а скажете «четверть десятого».

Квантование уходит своими корнями в сжатие информации; в глубоких сетях это относится к снижению численной точности его весов и / или активаций.
Перепараметрированные DNN имеют больше степеней свободы, что делает их хорошими кандидатами для сжатия информации [1]. Когда вы квантуете модель, обычно происходят две вещи: модель становится меньше и работает с большей эффективностью. Поставщики оборудования явно допускают более быструю обработку 8-битных данных (чем 32-битных), что приводит к более высокой пропускной способности. Меньшая модель требует меньше памяти и потребляет меньше энергии [2], что имеет решающее значение для развертывания на периферии.
Функция отображения
Как вы могли догадаться, функция отображения — это функция, которая отображает значения из числа с плавающей запятой в целочисленное пространство. Обычно используемая функция отображения представляет собой линейное преобразование, заданное формулой , где – входные данные и – параметры квантования .
Для обратного преобразования в пространство с плавающей запятой обратная функция задается как .
, а их разность составляет ошибку квантования .
Параметры квантования
Функция отображения параметрируется коэффициентом масштабирования и нулевой точкой .
– это просто отношение входного диапазона к выходному диапазону.
, где [] — диапазон отсечения входа, т.е. границы допустимых входов. [] — это диапазон квантованного выходного пространства, на которое он отображается. Для 8-битного квантования выходной диапазон .
действует как смещение, гарантируя, что 0 во входном пространстве точно соответствует 0 в квантованном пространстве.
Калибровка
Процесс выбора входного диапазона отсечения известен как калибровка . Самый простой метод (также используемый по умолчанию в PyTorch) — записать текущие минимальные и максимальные значения и присвоить их и . TensorRT также использует минимизацию энтропии (расхождение KL), минимизацию среднеквадратичной ошибки или процентили входного диапазона.
TensorRT также использует минимизацию энтропии (расхождение KL), минимизацию среднеквадратичной ошибки или процентили входного диапазона.
В PyTorch модули Observer (документы, код) собирают статистику по входным значениям и вычисляют qparams. Различные схемы калибровки приводят к разным квантованным выходным данным, и лучше эмпирически проверить, какая схема лучше всего подходит для вашего приложения и архитектуры (подробнее об этом позже).
из torch.quantization.observer импортировать MinMaxObserver, MovingAverageMinMaxObserver, HistogramObserver С, Л = 3, 4 нормальный = факел.распределения.нормальный.Нормальный(0,1) входы = [normal.sample((C, L)), normal.sample((C, L))] печать (входы) # >>>>> # [тензор([[-0,0590, 1,1674, 0,7119, -1,1270], # [-1,3974, 0,5077, -0,5601, 0,0683], # [-0,0929, 0,9473, 0,7159, -0,4574]]]), # тензор([[-0,0236, -0,7599, 1,0290, 0,8914], # [-1,1727, -1,2556, -0,2271, 0,9568], # [-0,2500, 1,4579, 1,4707, 0,4043]])] наблюдатели = [MinMaxObserver(), MovingAverageMinMaxObserver(), HistogramObserver()] для наблюдений в наблюдателях: для x во входных данных: obs(x) print(obs.__class__.__name__, obs.calculate_qparams()) # >>>>> # MinMaxObserver (tensor([0.0112]), tensor([124], dtype=torch.int32)) # MovingAverageMinMaxObserver (tensor([0.0101]), tensor([139], dtype=torch.int32)) # HistogramObserver (tensor([0.0100]), tensor([106], dtype=torch.int32))
Аффинные и симметричные схемы квантования
Схемы аффинного или асимметричного квантования назначают входной диапазон для минимального и максимального наблюдаемых значений. Аффинные схемы обычно предлагают более узкие диапазоны отсечения и полезны для квантования неотрицательных активаций (вам не нужно, чтобы входной диапазон содержал отрицательные значения, если ваши входные тензоры никогда не бывают отрицательными). Диапазон рассчитывается как . Аффинное квантование приводит к более дорогостоящему выводу при использовании для весовых тензоров [3].
Симметричное квантование Схемы центрируют входной диапазон вокруг 0, устраняя необходимость вычисления смещения нулевой точки.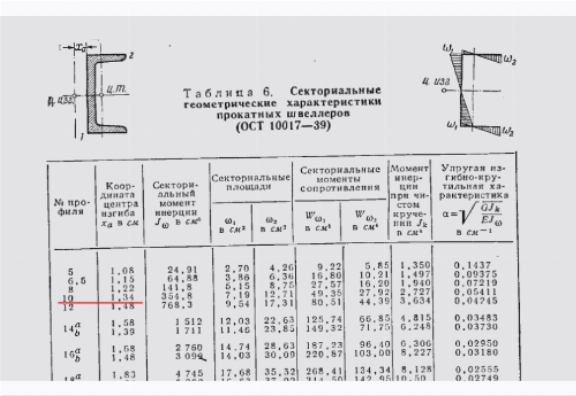
действие = torch.distributions.pareto.Pareto(1, 10).sample((1,1024))
веса = torch.distributions.normal.Normal(0, 0.12).sample((3, 64, 7, 7)).flatten()
деф get_симметричный_диапазон (х):
бета = факел.max(x.max(), x.min().abs())
вернуть -beta.item(), beta.item()
защита get_affine_range(x):
вернуть x.min().item(), x.max().item()
def plot(plt, данные, схема):
границы = get_affine_range(данные), если схема == 'аффинная' иначе get_симметричный_диапазон(данные)
a, _, _ = plt.hist (данные, плотность = True, ячейки = 100)
ymin, ymax = np.quantile(a[a>0], [0,25, 0,95])
plt.vlines(x=границы, ls='--', colors='purple', ymin=ymin, ymax=ymax)
рис, топор = plt.subplots(2,2)
сюжет (оси [0, 0], акт, 'аффинный')
axs[0, 0].set_title("Активация, аффинно-квантованная")
сюжет (оси [0, 1], акт, 'симметричный')
axs[0, 1]. set_title("Активация, симметрично-квантованная")
график (оси [1, 0], веса, 'аффинный')
axs[1, 0].set_title("Веса, аффинно-квантованные")
график (оси [1, 1], веса, «симметричный»)
axs[1, 1].set_title("Веса, симметрично-квантованные")
plt.show()
set_title("Активация, симметрично-квантованная")
график (оси [1, 0], веса, 'аффинный')
axs[1, 0].set_title("Веса, аффинно-квантованные")
график (оси [1, 1], веса, «симметричный»)
axs[1, 1].set_title("Веса, симметрично-квантованные")
plt.show()
Рис. 2. Диапазоны отсечения (фиолетовые) для аффинных и симметричных схем
В PyTorch вы можете указать аффинные или симметричные схемы при инициализации Observer. Обратите внимание, что не все наблюдатели поддерживают обе схемы.
для qscheme в [torch.per_tensor_affine, torch.per_tensor_symmetric]:
obs = MovingAverageMinMaxObserver(qscheme=qscheme)
для x во входных данных: obs(x)
print(f"Qscheme: {qscheme} | {obs.calculate_qparams()}")
# > >>>>
# Q-схема: torch.per_tensor_affine | (тензор([0.0101]), тензор([139], dtype=torch.int32))
# Qscheme: torch.per_tensor_симметричный | (тензор([0,0109]), тензор([128]))
Схемы квантования для каждого тензора и канала
Параметры квантования могут рассчитываться как для всего тензора весов слоя в целом, так и отдельно для каждого канала. Для каждого тензора один и тот же диапазон отсечения применяется ко всем каналам в слое
Для каждого тензора один и тот же диапазон отсечения применяется ко всем каналам в слое
Рис. 3. Для каждого канала используется один набор qparams для каждого канала. Для каждого тензора используются одни и те же qparams для всего тензора.
Для весового квантования симметричное поканальное квантование обеспечивает лучшую точность; тензорное квантование работает плохо, возможно, из-за высокой дисперсии конв. весов по каналам из-за свертки пакетной нормы [3].
из torch.quantization.observer import MovingAveragePerChannelMinMaxObserver obs = MovingAveragePerChannelMinMaxObserver(ch_axis=0) # рассчитать qparams для всех каналов `C` отдельно для x во входных данных: obs(x) печать (obs.calculate_qparams()) # >>>>> # (тензор([0,0090, 0,0075, 0,0055]), тензор([125, 187, 82], dtype=torch.int32))
Базовый модуль
В настоящее время операторы квантования выполняются на машинах x86 через серверную часть FBGEMM или используют примитивы QNNPACK на машинах ARM. Бэкенд-поддержка серверных графических процессоров (через TensorRT и cuDNN) появится в ближайшее время. Узнайте больше о расширении квантования на пользовательские серверные части: RFC-0019..
Бэкенд-поддержка серверных графических процессоров (через TensorRT и cuDNN) появится в ближайшее время. Узнайте больше о расширении квантования на пользовательские серверные части: RFC-0019..
серверная часть = 'fbgemm', если x86 иначе 'qnnpack' qconfig = torch.quantization.get_default_qconfig(серверная часть) torch.backends.quantized.engine = серверная часть
QConfig
QConfig (код, документы) NamedTuple хранит наблюдателей и схемы квантования, используемые для квантования активаций и весов.
Обязательно передайте класс Observer (не экземпляр) или вызываемый объект, который может возвращать экземпляры Observer. Используйте with_args() , чтобы переопределить аргументы по умолчанию.
my_qconfig = torch.quantization.QConfig( активация = MovingAverageMinMaxObserver.with_args (qscheme = torch.per_tensor_affine), вес = MovingAveragePerChannelMinMaxObserver.with_args (qscheme = torch.qint8) ) # >>>>> # QConfig(activation=functools.partial(
, qscheme=torch.per_tensor_affine){}, weight=functools.partial( , qscheme=torch.qint8){})
В PyTorch
PyTorch позволяет вам несколько различных способов квантизации вашей модели в зависимости от
- , если вы предпочитаете гибкий, но ручной или ограниченный автоматический процесс ( Eager Mode v/s FX Graph Mode )
- , если qparams для активации квантования (выходные данные слоя) предварительно вычисляются для всех входных данных или вычисляются заново для каждого входного сигнала ( статические по сравнению с динамическими ),
- , если qparams вычисляются с повторным обучением или без него ( обучение с учетом квантования v/s квантование после обучения )
Режим FX Graph автоматически объединяет подходящие модули, вставляет заглушки Quant/DeQuant, калибрует модель и возвращает квантованный модуль — и все это в двух вызовах метода — но только для сетей, которые можно проследить символически. Примеры ниже содержат вызовы с использованием Eager Mode и FX Graph Mode для сравнения.
Примеры ниже содержат вызовы с использованием Eager Mode и FX Graph Mode для сравнения.
В DNN подходящими кандидатами для квантования являются веса FP32 (параметры слоя) и активации (выходные данные слоя). Квантование весов уменьшает размер модели. Квантованные активации обычно приводят к более быстрому выводу.
Например, 50-уровневая сеть ResNet имеет около 26 миллионов весовых параметров и вычисляет около 16 миллионов активаций на прямом проходе.
Динамическое/весовое квантование после тренировки
Здесь веса модели предварительно квантуются; активации квантуются «на лету» («динамически») во время логического вывода. Самый простой из всех подходов, он имеет однострочный вызов API в torch.quantization.quantize_dynamic . В настоящее время только линейный и рекуррентный ( LSTM , ГРУ , РНН ) поддерживаются слои для динамического квантования.
(+) Может привести к более высокой точности, поскольку диапазон ограничения точно откалиброван для каждого входа [1].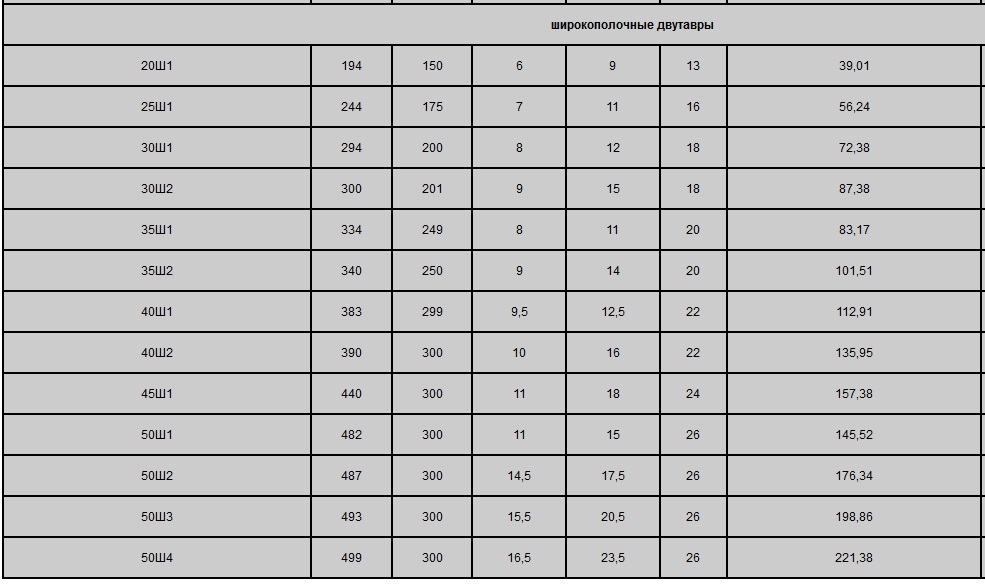
(+) Динамическое квантование предпочтительнее для таких моделей, как LSTM и Transformers, где запись/извлечение весов модели из памяти преобладает над пропускной способностью [4].
(-) Калибровка и квантование активаций на каждом уровне во время выполнения может привести к дополнительным вычислительным затратам.
импортный факел
импорт факела nn
# игрушечная модель
m = nn.Sequential(
nn.Conv2d(2, 64, (8,)),
nn.ReLU(),
nn.Линейный(16,10),
nn.LSTM(10, 10))
м.оценка()
## ЖАЖДЫЙ РЕЖИМ
из torch.quantization импортировать quantize_dynamic
model_quantized = квантовать_динамический (
модель = m, qconfig_spec = {nn.LSTM, nn.Linear}, dtype = torch.qint8, inplace = False
)
## РЕЖИМ ЭФФЕКТОВ
из torch.quantization импортировать quantize_fx
qconfig_dict = {"": torch.quantization.default_dynamic_qconfig} # Пустой ключ означает, что значение по умолчанию применяется ко всем модулям
model_prepared = quantize_fx.prepare_fx(m, qconfig_dict)
model_quantized = quantize_fx. convert_fx (model_prepared)
convert_fx (model_prepared)
Статическое квантование после обучения (PTQ)
PTQ также предварительно квантует веса модели, но вместо калибровки активаций на лету диапазон отсечения предварительно калибруется и фиксируется («статически») с использованием данных проверки. Активации остаются с квантованной точностью между операциями во время логического вывода. Около 100 мини-пакетов репрезентативных данных достаточно для калибровки наблюдателей [2]. В приведенных ниже примерах используются случайные данные для калибровки для удобства — их использование в вашем приложении приведет к неправильным параметрам qparams.
Рис. 4. Этапы статического квантования после обучения
объединяет несколько последовательных модулей (например: [Conv2d, BatchNorm, ReLU] ) в один. Слияние модулей означает, что компилятору нужно запускать только одно ядро вместо многих; это ускоряет работу и повышает точность за счет уменьшения ошибки квантования.
(+) Статическое квантование обеспечивает более быстрый вывод, чем динамическое квантование, поскольку оно устраняет затраты на преобразование float<->int между слоями.
(-) Статические квантованные модели могут нуждаться в регулярной повторной калибровке, чтобы оставаться устойчивыми к дрейфу распределения.
# Статическое квантование модели состоит из следующих шагов:
# Модули предохранителей
# Вставить заглушки Quant/DeQuant
# Подготовьте объединенный модуль (вставьте наблюдателей до и после слоев)
# Откалибруйте подготовленный модуль (передайте ему репрезентативные данные)
# Преобразовать откалиброванный модуль (заменить квантованным вариантом)
импортный факел
импорт факела nn
импортировать копию
backend = "fbgemm" # работает на процессоре x86. Используйте «qnnpack», если работаете на ARM.
модель = nn.Sequential(
nn.Conv2d(2,64,3),
nn.ReLU(),
nn.Conv2d(64, 128, 3),
nn.ReLU()
)
## ЖАЖДЫЙ РЕЖИМ
m = copy. deepcopy(модель)
м.оценка()
"""Предохранитель
- Слияние на месте заменяет первый модуль в последовательности слитым модулем, а остальные - идентификационными модулями.
"""
torch.quantization.fuse_modules(m, ['0','1'], inplace=True) # объединить первую пару Conv-ReLU
torch.quantization.fuse_modules(m, ['2','3'], inplace=True) # объединить вторую пару Conv-ReLU
"""Вставить заглушки"""
m = nn.Sequential(torch.quantization.QuantStub(),
* м,
факел.квантование.DeQuantStub())
"""Подготовить"""
m.qconfig = torch.quantization.get_default_qconfig(серверная часть)
torch.quantization.prepare(m, inplace=True)
"""Калибровка
- В этом примере для удобства используются случайные данные. Вместо этого используйте репрезентативные (проверочные) данные.
"""
с torch.inference_mode():
для _ в диапазоне (10):
х = факел.rand(1,2, 28, 28)
м (х)
"""Конвертировать"""
torch.quantization.convert(m, inplace=True)
"""Проверять"""
print(m[[1]].weight().element_size()) # 1 байт вместо 4 байт для FP32
## ГРАФИК FX
из torch.
deepcopy(модель)
м.оценка()
"""Предохранитель
- Слияние на месте заменяет первый модуль в последовательности слитым модулем, а остальные - идентификационными модулями.
"""
torch.quantization.fuse_modules(m, ['0','1'], inplace=True) # объединить первую пару Conv-ReLU
torch.quantization.fuse_modules(m, ['2','3'], inplace=True) # объединить вторую пару Conv-ReLU
"""Вставить заглушки"""
m = nn.Sequential(torch.quantization.QuantStub(),
* м,
факел.квантование.DeQuantStub())
"""Подготовить"""
m.qconfig = torch.quantization.get_default_qconfig(серверная часть)
torch.quantization.prepare(m, inplace=True)
"""Калибровка
- В этом примере для удобства используются случайные данные. Вместо этого используйте репрезентативные (проверочные) данные.
"""
с torch.inference_mode():
для _ в диапазоне (10):
х = факел.rand(1,2, 28, 28)
м (х)
"""Конвертировать"""
torch.quantization.convert(m, inplace=True)
"""Проверять"""
print(m[[1]].weight().element_size()) # 1 байт вместо 4 байт для FP32
## ГРАФИК FX
из torch. quantization импортировать quantize_fx
m = copy.deepcopy(модель)
м.оценка()
qconfig_dict = {"": torch.quantization.get_default_qconfig(серверная часть)}
# Подготовить
model_prepared = quantize_fx.prepare_fx(m, qconfig_dict)
# Калибровка - Используйте репрезентативные (проверочные) данные.
с torch.inference_mode():
для _ в диапазоне (10):
х = факел.rand(1,2,28, 28)
модель_подготовлено (х)
# квантовать
model_quantized = quantize_fx.convert_fx (model_prepared)
quantization импортировать quantize_fx
m = copy.deepcopy(модель)
м.оценка()
qconfig_dict = {"": torch.quantization.get_default_qconfig(серверная часть)}
# Подготовить
model_prepared = quantize_fx.prepare_fx(m, qconfig_dict)
# Калибровка - Используйте репрезентативные (проверочные) данные.
с torch.inference_mode():
для _ в диапазоне (10):
х = факел.rand(1,2,28, 28)
модель_подготовлено (х)
# квантовать
model_quantized = quantize_fx.convert_fx (model_prepared)
Обучение квантованию (QAT)
Рис. 5. Этапы обучения с учетом квантования
Подход PTQ отлично подходит для больших моделей, но в меньших моделях страдает точность [[6]]. Это, конечно, связано с потерей численной точности при адаптации модели из FP32 к области INT8 (рис. 6(a)) . QAT решает эту проблему, включая эту ошибку квантования в потери при обучении, тем самым обучая модель, основанную на INT8.
Рис. 6. Сравнение конвергенции PTQ и QAT [3]
Все веса и смещения хранятся в FP32, и обратное распространение происходит как обычно. Однако при прямом проходе квантование внутренне моделируется с помощью модулей
Однако при прямом проходе квантование внутренне моделируется с помощью модулей FakeQuantize . Их называют фальшивыми, потому что они квантуют и сразу же деквантуют данные, добавляя шум квантования, подобный тому, который может возникнуть во время квантованного вывода. Таким образом, окончательные потери учитывают любые ожидаемые ошибки квантования. Оптимизация этого позволяет модели идентифицировать более широкую область функции потерь (рис. 6(b)) и определить параметры FP32 таким образом, чтобы их квантование до INT8 не оказывало существенного влияния на точность.
Рис. 7. Фальшивое квантование в прямом и обратном проходе
Источник изображения: https://developer.nvidia.com/blog/achieving-fp32-accuracy-for-int8-inference-using-quantization-aware-training-with-tensorrt
(+) QAT обеспечивает более высокую точность, чем PTQ.
(+) Qparams можно изучить во время обучения модели для большей точности (см. LearnableFakeQuantize)
LearnableFakeQuantize)
(-) Вычислительная стоимость переобучения модели в QAT может составлять несколько сотен эпох [1]
# QAT следует тем же шагам, что и PTQ, за исключением цикла обучения, прежде чем вы фактически преобразуете модель в ее квантованную версию.
импортный факел
импорт факела nn
backend = "fbgemm" # работает на процессоре x86. Используйте «qnnpack», если работаете на ARM.
m = nn.Sequential(
nn.Conv2d(2,64,8),
nn.ReLU(),
nn.Conv2d(64, 128, 8),
nn.ReLU()
)
"""Предохранитель"""
torch.quantization.fuse_modules(m, ['0','1'], inplace=True) # объединить первую пару Conv-ReLU
torch.quantization.fuse_modules(m, ['2','3'], inplace=True) # объединить вторую пару Conv-ReLU
"""Вставить заглушки"""
m = nn.Sequential(torch.quantization.QuantStub(),
* м,
факел.квантование.DeQuantStub())
"""Подготовить"""
м.поезд()
m.qconfig = torch.quantization.get_default_qconfig(серверная часть)
torch.quantization. prepare_qat(m, inplace=True)
"""Тренировочный цикл"""
n_эпох = 10
opt = torch.optim.SGD(m.parameters(), lr=0,1)
loss_fn = лямбда-выход, tgt: torch.pow(tgt-out, 2).mean()
для эпохи в диапазоне (n_epochs):
х = факел.rand(10,2,24,24)
выход = м (х)
потеря = потеря_fn (вне, torch.rand_like (вне))
опт.нулевой_град()
потеря.назад()
опт.шаг()
"""Конвертировать"""
м.оценка()
torch.quantization.convert(m, inplace=True)
prepare_qat(m, inplace=True)
"""Тренировочный цикл"""
n_эпох = 10
opt = torch.optim.SGD(m.parameters(), lr=0,1)
loss_fn = лямбда-выход, tgt: torch.pow(tgt-out, 2).mean()
для эпохи в диапазоне (n_epochs):
х = факел.rand(10,2,24,24)
выход = м (х)
потеря = потеря_fn (вне, torch.rand_like (вне))
опт.нулевой_град()
потеря.назад()
опт.шаг()
"""Конвертировать"""
м.оценка()
torch.quantization.convert(m, inplace=True)
Анализ чувствительности
Не все слои одинаково реагируют на квантование, некоторые из них более чувствительны к падению точности, чем другие. Определение оптимальной комбинации слоев, которая сводит к минимуму падение точности, требует много времени, поэтому [3] предлагают анализ чувствительности по одному за раз, чтобы определить, какие слои наиболее чувствительны, и сохранить для них точность FP32. В их экспериментах пропуск всего 2 слоев преобразования (из 28 в MobileNet v1) дал им точность, близкую к FP32. Используя режим FX Graph, мы можем легко создавать собственные qconfigs:0003
# ЕДИНЫЙ АНАЛИЗ ЧУВСТВИТЕЛЬНОСТИ для quantized_layer, _ в model.named_modules(): print("Только слой квантования: ", quantized_layer) # Ключ module_name разрешает специфичные для модуля qconfigs. qconfig_dict = {"": Нет, "module_name":[(квантованный_слой, torch.quantization.get_default_qconfig(бэкенд))]} model_prepared = quantize_fx.prepare_fx(модель, qconfig_dict) # откалибровать model_quantized = quantize_fx.convert_fx (model_prepared) # оценить(модель)
Другой подход заключается в сравнении статистики уровней FP32 и INT8; обычно используемыми показателями для них являются SQNR (отношение сигнала к квантованному шуму) и среднеквадратическая ошибка. Такой сравнительный анализ также может помочь в дальнейшей оптимизации.
Рис. 8. Сравнение веса модели и активации
PyTorch предоставляет инструменты для помощи в этом анализе в Numeric Suite. Узнайте больше об использовании Numeric Suite из полного руководства.
# выдержка из https://pytorch.org/tutorials/prototype/numeric_suite_tutorial.html импортировать torch.quantization._numeric_suite как ns по определению SQNR(x, y): # Чем выше, тем лучше Ps = факел.норм(х) Pn = факел.норма (х-у) вернуть 20*torch.log10(Ps/Pn) wt_compare_dict = ns.compare_weights(fp32_model.state_dict(), int8_model.state_dict()) для ключа в wt_compare_dict: print(key, calculate_error(wt_compare_dict[key]['float'], wt_compare_dict[key]['quantized'].dequantize())) act_compare_dict = ns.compare_model_outputs(fp32_model, int8_model, input_data) для ключа в act_compare_dict: print(key, calculate_error(act_compare_dict[key]['float'][0], act_compare_dict[key]['quantized'][0].dequantize()))
Рис. 9. Предлагаемый рабочий процесс квантования
Нажмите, чтобы увеличить изображение
Обратите внимание
- Большие (более 10 миллионов параметров) модели более устойчивы к ошибкам квантования. [2]
- Квантование модели по контрольной точке FP32 обеспечивает более высокую точность, чем обучение модели INT8 с нуля.
 [2]
[2] - Профилирование среды выполнения модели является необязательным, но оно может помочь определить слои, вызывающие узкие места.
- Динамическое квантование — это простой первый шаг, особенно если в вашей модели много линейных или рекуррентных слоев.
- Используйте симметричное поканальное квантование с наблюдателями
MinMaxдля квантования весов. Использовать аффинное тензорное квантование с наблюдателямиMovingAverageMinMaxдля активаций квантования[2, 3] - Используйте такие метрики, как SQNR, чтобы определить, какие слои наиболее подвержены ошибкам квантования. Отключите квантование на этих слоях.
- Используйте QAT для точной настройки примерно 10% исходного графика обучения с графиком скорости обучения отжига, начиная с 1% начальной скорости обучения обучения. [3]
- Если описанный выше рабочий процесс не сработал для вас, мы хотим узнать больше. Разместите ветку с подробностями вашего кода (архитектура модели, показатель точности, опробованные методы).
 Не стесняйтесь писать мне копии @suraj.pt.
Не стесняйтесь писать мне копии @suraj.pt.
Пришлось многое переварить, поздравляю, что не сдались! Далее мы рассмотрим квантование «реальной» модели, в которой используются динамические управляющие структуры (если-иначе, циклы). Эти элементы запрещают символическую трассировку модели, что немного усложняет прямое квантование модели из коробки. В следующем посте этой серии мы запачкаем руки моделью, которая битком набита циклами и блоками if-else и даже использует сторонние библиотеки в переадресация вызов.
Мы также рассмотрим новую интересную функцию квантования PyTorch под названием Define-by-Run, которая пытается ослабить это ограничение, требуя, чтобы только подмножества вычислительного графа модели были свободны от динамического потока. Ознакомьтесь с постером Define-by-Run на PTDD’21 для предварительного просмотра.
Ссылки
[1] Голами, А., Ким, С., Донг, З., Яо, З., Махони, М. В., и Койцер, К. (2021). Обзор методов квантования для эффективного вывода нейронной сети.